Diversifying Sparsity Using Variational Determinantal Point Processes
We propose a novel diverse feature selection method based on determinantal point processes (DPPs). Our model enables one to flexibly define diversity based on the covariance of features (similar to orthogonal matching pursuit) or alternatively based …
Authors: Nematollah Kayhan Batmanghelich, Gerald Quon, Alex Kulesza
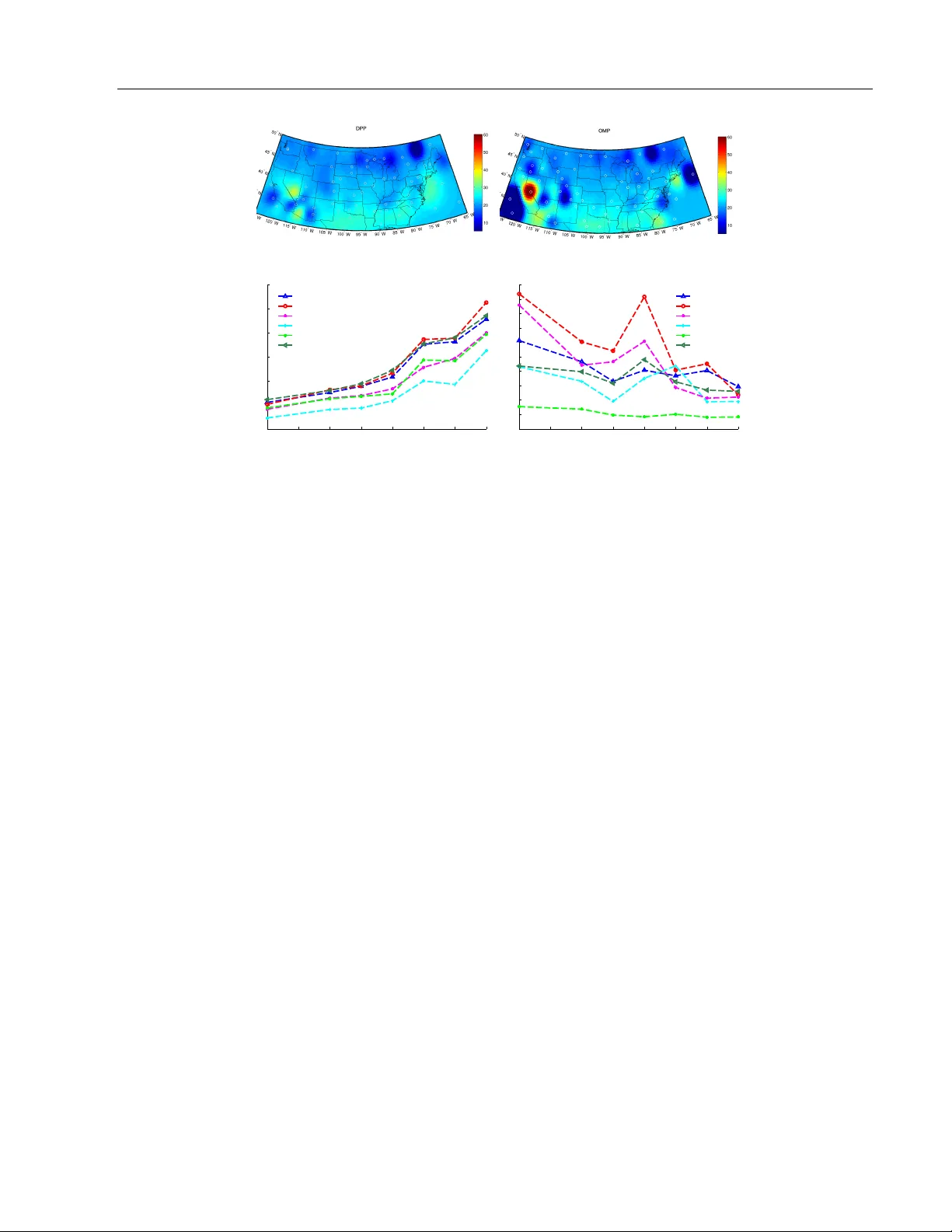
Div ersifying Sparsit y Using V ariational Determinan tal P oin t Pro cesses N.K. Batmanghelic h 1 G. Quon 1 A. Kulesza 2 M. Kellis 1 P . Golland 1 L. Bornn 3 1 Massac husetts Institute of T ec hnology 2 Univ ersity of Michigan 3 Harv ard Univ ersity Abstract W e prop ose a nov el div erse feature selection metho d based on determinan tal p oin t pro- cesses (DPPs). Our mo del enables one to flexibly define diversit y based on the cov ari- ance of features (similar to orthogonal matc h- ing pursuit) or alternatively based on side information. W e in tro duce our approach in the con text of Bay esian sparse regression, emplo ying a DPP as a v ariational approx- imation to the true spik e and slab p oste- rior distribution. W e subsequen tly show how this v ariational DPP approximation general- izes and extends mean-field appro ximation, and can b e learned efficiently b y exploiting the fast sampling prop erties of DPPs. Our motiv ating application comes from bioinfor- matics, where we aim to iden tify a diverse set of genes whose expression profiles predict a tumor t ype where the div ersity is defined with resp ect to a gene-gene in teraction net- w ork. W e also explore an application in spa- tial statistics. In b oth cases, we demonstrate that the proposed method yields significan tly more diverse feature sets than classic sparse metho ds, without compromising accuracy . 1 In tro duction As mo dern tec hnology enables us to capture increas- ingly large amounts of data, it is critically imp or- tan t to find efficient wa ys to create compact, func- tional, and interpretable represen tations. F eature se- lection is a promising approach, since reducing the fea- ture space both improv es in terpretability and preven ts o ver-fitting; as a result, it has receiv ed considerable at- ten tion in the literature [e.g., 26, 13]. In this pap er, w e focus on the problem of diverse feature selection, where the notion of div ersity can b e defined in terms of the features themselv es or in terms of av ailable side information. Div erse feature sets ha v e the p oten tial to b e b oth more compact and easier to interpret, without sacrificing p erformance. Diversit y also pla ys a more fundamen- tal role in some real-world applications; for example, breast cancer is increasingly recognized to present a highly heterogeneous group of malignancies [8] where subgroups ma y inv olv e different mec hanisms of action. F or the common task of identifying gene expression- based biomark ers of different tumor subt yp es, maxi- mizing the div ersity of selected genes helps iden tifying these disparate mec hanisms of action. Div ersit y in this case is defined with respect to a separate gene-gene in- teraction netw ork (see Section 4.1). Existing techniques for feature selection generally do not explicitly consider feature diversit y . F rom an opti- mization point of view, feature selection can be view ed as a searc h o ver all p ossible subsets of features to iden- tify the optimal subset according to a pre-sp ecified metric, often balancing mo del fit and mo del com- plexit y . T o a void enumerating the en tire com binato- rial searc h space, embedded approac hes, such as the LASSO [26], relax the problem to a combination of a sparsit y term ( ` 1 ) and a data fidelit y term. How ever, suc h metho ds t ypically do not encourage diversit y ex- plicitly . In fact, LASSO has been sho wn to be unstable in the face of nearly collinear features [11], with sev eral v arian ts prop osed to ameliorate this issue [28]. An alternativ e approach is to search greedily by suc- cessiv ely adding (or removing) the b est (or w orst) fea- ture [13]. Orthogonal matching pursuit (OMP) pro- ceeds in this w ay using forw ard step-wise feature se- lection, but the selected feature is chosen to b e as orthogonal as p ossible to previously selected features [21]. One can view this orthogonalit y as a measure to implicitly maximize div ersity [6]. In spite of its well- established p erformance [27], OMP is a procedure that lac ks an underlying generativ e mo del and, therefore, the flexibility to define diversit y other than through Man uscript under review the inner pro duct of features. In this pap er w e tak e a probabilistic view of the prob- lem, assigning a probabilit y measure to feature sub- sets. W e then seek the maximum a p osteriori (MAP) estimate as the optimal subset. In particular, our probabilit y measure is a v ariational approximation to the p osterior of the spike-and-slab v ariable selection mo del. By imp osing a particular form on that ap- pro ximation, we obtain a measure that assigns higher scores to feature subsets that are not only relev an t to a regression or classification task but also div erse. The c hallenge is to find a form that ac hiev es this goal while remaining computationally tractable. T o this end, our v ariational appro ximation tak es the form of a determinantal p oint pro cess (DPP). DPPs are app ealing in this context since they naturally en- courage diversit y , defined in terms of a kernel ma- trix that can b e, for example, the feature co v ari- ance matrix (discouraging collinearity), or alterna- tiv ely deriv ed from application-specific notions of sim- ilarit y [16]. DPPs also offer computationally appealing prop erties suc h as efficient sampling and approximate MAP estimation [10, 19]. As a result, not only can we efficien tly approximate the optimal feature set, but we can also provide sampling-based credible in terv als. Unlik e mean field approximations that fully factor- ize the p osterior distribution, our approximate DPP p osterior has a complex dependency structure. This mak es fitting the DPP a challenging task. Kulesza et al. [16] used an optimization approach to learn condi- tional DPPs, and Affandi et al. [1] proposed to param- eterize the kernel of DPPs and learn the parameters using a sampling approac h; how ever, neither approach allo ws learning a full, unparameterized k ernel. In con- trast, our algorithm is based on a flexible v ariational framew ork prop osed by Salimans and Knowles [23] that only requires t wo basic op erations: efficient ev alu- ation of the join t lik elihoo d and efficien t sampling from the current estimate of the p osterior. F ortunately , for DPPs these operations are efficient. F or regression, the marginal lik eliho o d tak es a closed form, and for man y other mo dels, including classification, it can b e appro ximated efficien tly . T o the b est of our kno wl- edge this w ork presen ts the first use of DPPs within a v ariational framew ork. The closest w ork to ours is b y George et al. [9]. They suggested v ariations of so-called dilution priors that, instead of assigning prior uniformly across models, as- sign probability more uniformly across neighb orho o ds , and then distribute the neighborho od probabilities across the mo dels within them. One of the diluting priors prop osed in [9] is prop ortional to the determi- nan t of the features, resembling the form of a DPP . Suc h a prior does not guaran tee diversifying prop erties on the posteriori selected features. Although possible, instead of prior, we suggest to appro ximate the p os- terior with DPP . W e inv estigate this mo del choice in Section 4. This w ork mak es the following contributions. W e pro- p ose to use a DPP as an approximate p osterior for Ba yesian feature selection. T o fit the v ariational ap- pro ximation, we draw a connection b etw een DPPs and the exp onen tial family using the decomp osition pro- p osed by Kulesza et al. [16]. This connection makes man y tools dev eloped for the exp onen tial family a v ail- able for DPPs, including v ariational learning metho ds for distributions that are not fully factorizable. Our prop osed metho d brings a num b er of adv an tages, in- cluding the ability to: (i) prop ose m ultiple sets of rel- ev an t and diverse features which can b e viewed as al- ternativ e feature selection solutions; (ii) c haracterize feature selection uncertaint y through p osterior sam- pling; (iii) flexibly define feature set diversit y based on side information, rather than just cov ariance; and (iv) compute the marginal probability for inclusion of new features conditioned on the presence of an existing feature set, thanks to the computational prop erties of DPPs. The remainder of the pap er is organized as follows. W e first review DPPs in Section 2. The idea of div erse sparsit y is illustrated in the con text of Bay esian v ari- able selection in Section 3.1. In Section 3.2, we show ho w to learn the parameters of such models. In the Section 4, w e apply the metho d to identify a diverse set of genes to predict a tumor t yp e while the div ersity is defined with resp ect to a gene-gene interaction net- w ork. Finally , in Section 4.2, we explore application to learning an optimal distribution of grid p oin ts in a spatial pro cess conv olution mo del. 2 Determinan tal P oin t Pro cess The determinantal p oin t process (DPP) defines distri- bution o ver configurations of points in space. If the space is finite, sa y [ M ] := { 1 , · · · , M } ; it defines prob- abilit y mass o ver all 2 M subsets. Specifically , the prob- abilit y of a subset γ ∈ { 0 , 1 } M is prop ortional to the determinan t of [ L ] γ where [ · ] γ denotes the submatrix con taining the columns and ro ws i for which γ i = 1 and L ∈ R M × M is a p ositiv e semidefinite kernel ma- trix. Strictly sp eaking, this representation defines a sub class of DPPs called L -ensembles. If L ij is a mea- suremen t of similarity betw een elements i and j , then the DPP assigns higher probabilities to subsets that are div erse. More precisely , if L ij = φ ( i ) T φ ( j ) for a feature function φ : [ M ] → R d , then the probability of a set γ is proportional to the squared volume spanned Man uscript under review (a) 0 10 20 30 40 50 60 70 80 90 100 0.5 0.6 0.7 0.8 0.9 1 1.1 1.2 1.3 Condition Number ( λ 1 / λ 2 ) Count in the block block 1 block 2 block 3 block 4 (b) Figure 1: (a) L -ensem ble of DPP for a to y problem of six items. The items are dissimilar except the first three items. This leads to a blo c k diagonal k ernel L . (b) Empirical av erage n umber of elements selected from each blo c k. Although the green block is bigger than the other blo c ks, as it b ecomes more collinear ( λ 1 λ 2 → ∞ ), the probability of selecting an item from the first blo ck con verges to that of the other blo c ks. b y { φ ( i ) | γ i = 1 } . Elements with orthogonal fea- ture functions will tend to span larger volumes, and hence ha ve a higher probability of co-o ccurrence. F or more in-depth review of DPP and its applications in mac hine learning see [16]. In addition to ha ving computationally appealing prop- erties such as efficient marginalization and sam- pling, repulsiv e in teractions are also mo deled elegantly through a DPP . T o illustrate this preference for diver- sit y , supp ose w e would lik e to c ho ose a subset from six items. The items are dissimilar except for the first three items. Therefore, their L -ensemble matrix is blo c k diagonal where the first three items form a sin- gle group, illustrated as a green blo c k in Figure 1a. W e assume that the green block has rank tw o with eigen v alues of λ 1 and λ 2 . As the condition num ber λ 1 λ 2 increases, the items of the green blo c k become more similar (collinear). W e can sample from this DPP and compute the empirical a verage of samples falling in to eac h blo c k as a function of λ 1 λ 2 (Figure 1b). If there is no in teraction, the probabilities are prop ortional to the sizes of the blo c ks but as λ 1 λ 2 → ∞ , the probabilit y of selecting an item from the first blo ck decreases to that of the rest of the blo c ks. 3 Metho ds 3.1 Ba yesian V ariable Selection F ollowing standard notation, we consider the regres- sion mo del y = P M m =1 x m β m + ε , where the regres- sors { x 1 , · · · , x M } are collected into a design matrix X = [ x 1 , · · · , x M ] ∈ R N × M and ε is the residual noise ε ∼ N ( · ; 0 , σ ). One can view v ariable selection as de- ciding which of the co efficien ts β m are nonzero. This is often made explicit in Bay esian v ariable selection through a latent binary random vector γ ∈ { 0 , 1 } M that sp ecifies which predictors are included: y = X ( γ β ) + ε, (1) where is the element-wise product. Assuming an ex- c hangeable Bernoulli prior for γ and a conjugate prior for β with cov ariance σ 2 Λ − 1 0 , i.e., β ∼ N ( · ; 0 , σ 2 Λ − 1 0 ), random v ariable γ m β m defines the so-called “spike- and-slab” prior [4, 18]. It is drawn from the spike with probability α and from the slab with probability 1 − α . Assuming an in verse Gamma prior with param- eters ( a 0 , b 0 ) for v ariance σ 2 , the join t lik eliho o d of the mo del can b e written as follows: p ( y , π ; X , ρ ) = (2) p ( y | γ , β , σ ; X ) p ( β | σ ; Λ 0 ) p ( σ ; a 0 , b 0 ) p ( γ ; α ) , where π = { β , σ, γ } is the set of latent random v ari- ables and ρ = { Λ 0 , a 0 , b 0 , α } is the set of fixed param- eters. W e set Λ 0 = c I . Conditioned on γ , the marginal likelihoo d of the re- stricted regression can be expressed in closed-form [5]: log p ( y | γ ; X , ρ ) = (3) − N 2 log 2 π + 1 2 (log det (Λ 0 ) − log det (Λ N )) + ( a 0 − a N ) (log b 0 − log b N ) + log Γ ( a N ) − log Γ ( a 0 ) Λ N = X T X + Λ 0 , µ N = Λ − 1 N X T y where Γ ( · ) is the Gamma function, a N = a 0 + N/ 2, and b N = b 0 + 1 2 y T y − µ T N Λ N . Exact inference of the p osterior inclusion probabilit y of the regressors, i.e., p ( γ | y ; X , ρ ), is computationally prohibitiv e since it entails a sum ov er all p ossible sub- sets of [ M ] := { 1 , · · · , M } . W e therefore resort to an appro ximation. V ariational approaches approximate the form of the p osterior; for example, the mean field approac h emplo ys a fully factorized function as the ap- pro ximating distribution [3, 4]. Marginalizing β out, the mean field appro ximates the p osterior probabilit y of v ariable inclusion as q ( γ ; θ ) = M Y m =1 q ( γ m ; θ m ) = M Y m =1 θ γ m m (1 − θ m ) 1 − γ m (4) Ho wev er, this form of posterior do es not accoun t for in- teraction b et ween regressors, diversit y b eing one such form. T o encourage diversit y , one needs to mo del the inter- actions betw een features. W e propose to use a DPP in an elegan t wa y to define probability mass o v er all p ossible subsets of [ M ]. As a naming conv en tion, “ XX-YY ” refers to prior sp ecification XX and v ariational Man uscript under review distribution YY ; hence we will refer to the setting as Bernoulli-DPP . It is p ossible to define the DPP as a prior for γ and approximate the p osterior with a fully factorized mean field metho d, i.e., Bernoulli (referred as DPP-Bernoulli ). How ever, suc h a prior do es not guaran tee that the posterior exhibits the diversifying prop ert y . It is also straightforw ard to hav e DPP as prior and p osterior ( i.e., DPP-DPP ) but here we fo cus on inv estigating how effective DPP is as prior versus p osterior. F ollowing the form ulation of Kulesza et al. [16], w e pro- p ose the following v ariational p osterior distribution: q ( γ ; θ )= 1 Z θ det [ L ] γ = 1 Z θ det h diag( e θ 2 ) ΦΦ T diag( e θ 2 ) i γ = 1 Z θ e θ T γ det ΦΦ T γ (5) where θ and γ are parameters and laten t random v ari- ables resp ectiv ely , and Z θ = det( I + L ) is the normal- ization constant [16]. Φ ∈ R M × d is a given matrix of similarit y features whose row m , φ ( m ), is the similar- it y feature v ector for item m , and L -ensemble matrix is L = diag( e θ 2 ) ΦΦ T diag( e θ 2 ). F or example if Φ = X , the DPP discourages collinearity . Φ can also b e de- fined via side information (see Section 4). Note that Eq. (5) reduces to Eq. (4) if the similarit y features are indicator v ectors, i.e., ΦΦ T = I . In this case, the DPP approximation proposed here reverts to a mean field approximation. 3.2 Learning W e now prop ose an algorithm to fit the v aria- tional approximation for b oth DPP-Bernoulli and Bernoulli-DPP . Learning with Bernoulli-DPP is more challenging than DPP-Bernoulli . T o see why , note that the v ariational approach minimizes the di- v ergence KL ( q θ | p ( γ , y )) = E q θ [log q θ ( γ ) − log p ( γ , y )] (6) When q θ is a DPP , computing the first term, which is the entrop y of the DPP entails 2 M summands which, to the best of our kno wledge, does not hav e any closed- form. W e focus on appro ximating Bernoulli-DPP and sho w how a straightforw ard mo dification to the result- ing algorithm can effectiv ely approximate the posterior of DPP-Bernoulli . T o learn θ in Eq. (5), we b orro w the sto c hastic ap- pro ximation algorithm from [23], which allows one to approximate any distribution that is given in a closed-form. In structur e d or fixe d-form v ariational Ba yes [15], the posterior distribution is chosen to be a sp ecific mem b er of an exp onen tial family , namely q ( γ ; θ ) = exp θ T T ( γ ) − U ( θ ) ν ( γ ) where T ( γ ) is the sufficien t statistic, U ( θ ) is the normalizer and ν ( θ ) is a base measure. The DPP in its general form is not a member of exp onen tial family but parameter- izing DPPs as Eq. (5) allows us to employ the frame- w ork. W e first summarize the algorithm in [23] in our con text where T ( γ ) := γ , ν ( γ ) := det([ ΦΦ T ] γ ), and U ( θ ) := det( L + I ). F or notational conv enience, we define ˜ q ˜ θ := exp( ˜ γ T ˜ θ ) where ˜ θ T = θ T , θ 0 and ˜ γ T = γ T , 1 . If θ 0 = − U ( θ ), then ˜ q is the normalized p osterior, otherwise it is an unnormalized v ersion [23]. T aking the gradi- en t of the unnormalized KL-divergence D ( ˜ q ˜ θ | p ( γ , y )), with resp ect to ˜ θ we obtain: ∇ ˜ θ D q ˜ θ | p ( γ , y ) = ∇ ˜ θ E ˜ q log ˜ q ˜ θ ( γ ) − log p ( γ , y ) = Z ˜ q ˜ θ ( γ ) h ˜ γ ˜ γ T ˜ θ − ˜ γ log p ( γ , y ) i dν ( γ ) (7) By setting Eq. (7) to zero, Salimans and Kno wles [23] linked linear regression and the v ariational Bay es metho d. Namely , at the optimal solution, ˜ θ should satisfy the linear system : C ˜ θ = g where C := E q ˜ γ ˜ γ T and g := E q [ ˜ γ log p ( γ , y )]. C and g are es- timated via weigh ted Monte Carlo sampling by draw- ing a single sample, γ t , from the current p osterior ap- pro ximation q ˜ θ t , g t +1 = (1 − w ) g t + w ˜ γ t log p ( γ t , y ) C t +1 = (1 − w ) C t + w ˜ γ t ˜ γ t T (8) where w ∈ [0 , 1] is the step size. In terestingly , E q γ γ T is the DPP marginal kernel, K , which has the closed form K = L ( L + I ) − 1 . Nev ertheless, in our exp erimen ts, w e did not see any clear adv antage in substituting the current estimate for K directly in to Eq. (8) v ersus using the empirical estimate. Pseudo-co de for our algorithm is sho wn in Algorithm 1 in App endix A. W e set p ( γ ) = Q m α γ m (1 − α ) 1 − γ m , and as suggested in [23], w := 1 √ N . W e further set the initial L -ensemble to L = ( e θ 0 / 2 Φ )( Φ T e θ 0 / 2 ), where θ 0 is adjusted to make sure that the initial sam- ples from the DPP are not empt y sets. T o do so, we note that the diagonal elements of K are the marginal probabilit y of inclusion of element i . Therefore the ex- p ected cardinalit y of the subset is tr ( K ) = P i e θ 0 λ i 1+ e θ 0 λ i , where λ i is the i ’th eigen vector of ΦΦ T . T o set the exp ected cardinality of subsets to a preset v alue κ , we solv e the equation for θ 0 . Algorithm 1 only requires sampling from a DPP with parameters θ t and computing p ( y, γ t ) = p ( y | γ t ) p ( γ t ). F or example, in the regression problem Eq. (3), p ( y | γ t ) Man uscript under review has the closed-form solution in Eq. (4). In a linear lo- gistic regression case (classification), p ( y | γ t ) do es not ha ve a closed-form but conditioned on γ t , its computa- tion is the equiv alen t of computing the marginal likeli- ho od for linear kernel Gaussian Pro cess mo del, which can b e appro ximated using exp ectation propagation (EP).Join t distribution p ( y , γ t ) can enco de more in- v olved mo dels as long as p ( y | γ t ) can b e approximated efficien tly (see the supplementary material for an ex- ample). One side b enefit of the algorithm is the auto- mated selection of the n umber of features included in the model. If fixed mo del size is desired, the algorithm can b e easily extended to employ k − DPPs, where the cardinalit y of the subset is fixed, by replacing the sam- pling part of the algorithm. After learning the DPP , we compute the MAP esti- mate using [10, 19] to find the most relev ant and di- v erse set. Other than MAP , w e can easily compute a credible interv al of our appro ximation of y b y drawing samples from the approximate p osterior, predicting y for each draw, and computing the v ariance of the pre- diction. In Algorithm 1, we fo cused on ha ving Bernoulli prior and DPP p osterior, i.e., Bernoulli-DPP . T o adapt the algorithm for DPP-Bernoulli , w e mo dify p ( y , γ ) b y changing the prior to p ( γ ) = det([ L ] γ ) det( L + I ) and setting the Φ for the posterior to the identit y matrix whic h results in Eq. (4). The rest of the algorithm sta ys in- tact. Computational Complexity: T o perform the in ver- sion in line 10 of Algorithm 1, we use conjugate gradi- en t(CG) which has the complexity of O ( m √ k ), where k is the condition num b er and m is the n umber of non- zero en tries. W e initialize the solv er with w arm initial- ization θ t − 1 whic h helps greatly (in our exp erience, CG con verges very quic kly). W e currently rely on a MA TLAB implemen tation to pro ve the concept; a low- rank approximation of C (similar to LBF GS metho d) should alleviate the memory complexity . If ΦΦ 0 is low- rank (which is the case in this pap er) the complexity of sampling from the DPP is reduced to O ( d 2 M ) p er iteration where d is the rank of the similarity matrix and M is the n umber of elements. Computing the marginal likelihoo d for regression has a closed form that in volv es in version of a matrix ( O ( J 3 ) where J is the num b er of selected elements in each iteration). F or classification, we use exp ectation propagation to appro ximate the marginal likelihoo d and the complex- it y of that is defined b y J (num b er of selected elements in each iteration). With smart initialization from the previous iteration, EP conv erges v ery quic kly . In addi- tion, smart bo okkeeping from previous iterations can reduce the num b er of marginal likelihoo d computa- tions. 4 Exp erimen ts W e sho w the results for t wo exp erimen ts co vering b oth classification (Section 4.1) and regression (Section 4.2); more exp erimen ts are provided in the supplementary material. While in Section 4.2, the features them- selv es are used to define div ersity ( Φ = X ) to p enal- ize collinearity , in Section 4.1 w e define the diversit y through side information ( Φ 6 = X ). In all of our ex- p erimen ts, we fit the parameters of the p osterior DPP and compute the MAP subset, S ∗ , using [19]. Since L is lo w rank and due to the numerical scale of the optimal qualit y score, exp( θ ), the lo cal optimization strategy of [10] failed, hence we use the greedy ap- proac h prop osed in [19] to approximate the MAP . W e compared our models to six other baseline metho ds: orthogonal matc hing pursuit ( OMP ), generalized linear mo del (GLM) Lasso ( Lasso ), GLM elastic net ( eNet ), forw ard selection ( FS ), spike-and-slab ( SpikeSlab ) [4], and using DPP as prior with a fully factorized mean field ( DPP-Bernoulli ). Lasso and FS are standard ap- proac hes for feature selection using conv ex and greedy optimization. Elastic net w as chosen since the extra ` 2 norm b etter cop es with collinearity b etter. OMP w as c hosen since the orthogonalit y procedure induces some notion of diversit y for Φ = X . SpikeSlab and DPP-Bernoulli assume Bernoulli and DPP priors for the inclusion of the features resp ectively but b oth de- plo y mean field to appro ximate the posterior. P arame- ters of the metho ds are adjusted to match the num b er of selected features with the cardinalit y of S ∗ . 4.1 Breast cancer prognosis prediction In this section, we turn to the motiv ating application of our metho d – finding a diverse set of genes (fea- tures) that distinguish stage I and I I breast tumors. Constructing accurate classifiers will help identify im- p ortan t biomarkers of breast cancer progression, and furthermore, increasing the functional diversit y of se- lected genes will more likely iden tify a comprehensive set of cancer-related pathw ays. The main idea is as follo ws. Gene expression profiles are the most readily a v ailable data for predicting breast cancer prognosis. Ho wev er, correlation of gene expression is a relatively p oor predictor of correlation in gene function [17], and so X is a p o or feature to define functional similarity of genes. Distance b et ween gene pairs in a protein- protein interaction (PPI) net work is predictiv e of gene function [17]: PPI net works tend to form comm unities, and genes b elonging to the same comm unity p erform similar functions. Ho wev er, since communit y detec- tion is very challenging [7], using netw ork distance to define similarity for DPP av oids a communit y detec- tion step. Man uscript under review 0 0.2 0.4 0.6 0.8 Bernoulli−DPP OMP Lasso eNet FS Random SpikeSlab DPP−Bernoulli AUC (a) −400 −300 −200 −100 0 100 *** *** Bernoulli−DPP OMP Lasso eNet FS Random SpikeSlab DPP−Bernoulli log det (L) (b) (c) (d) Figure 2: (a) Area under curve (AUC) p erformance a veraged o ver 100 train/test repeats of classification of tumor stages for different metho ds. (b) Diversit y of selected features, quantified as the determinant of L S where S is the subset of genes selected by each metho d (higher v alues indicate more diversit y). DPP yields more diverse subset without compromising accuracy . The asterisks in (b) indicate statistical significance (based on p -v alue) using a Wilcox rank sum test. (c), (d) Netw orks for top 40 genes for Bernoulli-DPP and OMP resp ectiv ely . The genes are sorted according to the num b er of times they presen t in the optimal set in 100 rep eats. The radius is prop ortional to num b er of times the gene is selected while the color indicates the sum of L ij in that gene. W e first collected 668 sub jects from The Cancer Genome A tlas [20] with stage I and II breast cancer. W e computed normalized expression levels for 13,876 genes for whic h at least one physical protein-protein in teraction was found in the BioGRID database [24], then fo cused on the top 2,000 genes with smallest p - v alue (according to a lik eliho od ratio test for a univ ari- ate logistic regression model) with resp ect to the tu- mor stages. W e then used the BioGRID gene interac- tion netw ork to compute pairwise similarities b etw een genes (features) as follo ws: Giv en the scale-free nature of the netw ork, w e first identified h ubs of the net work as those no des with total degree higher than 100. F or eac h gene i , w e then defined its netw ork profile f i as a 300-dimensional vector, where eac h component sp eci- fies the shortest path from that gene to a h ub. Our fea- ture similarity matrix, L = ΦΦ T , measures similarity b et w een genes i and j as L ij = exp −|| f i − f j || 2 /σ 2 where σ is set to 3, approximately the a v erage pairwise distance b et ween genes. Figure 2a and Figure 2b sho w that Bernoulli-DPP iden tifies gene sets significantly more diverse than all other methods, without compromising prediction ac- curacy . W e note that imposing DPP as an appro xi- mate p osterior leads to more diverse set than having DPP as prior in DPP-Bernoulli . W e also randomly select genes with low p -v alue to see if it leads to di- v erse set ( i.e., Random in Figure2b). Although AUC of Random is in the same range as the other metho d, the div ersity is b elo w Bernoulli-DPP and FS . SpikeSlab pro duces go od accuracy but the selected genes are ba- sically top genes according to p -v alue (not shown in the figure) and the gene set is not div erse. W e next assessed whether the diverse set of genes iden tified by Bernoulli-DPP pinp oin ts path wa ys in- v olved in breast cancer. W e first divided the 2,000 genes in to 410 communities [2] using the BioGRID net work. Based on 20 different cross-v alidation runs using all fiv e metho ds, we iden tified 18 communities within the net work that were selected more often (in at least 20% of the runs) by the Bernoulli-DPP than an y other metho d. W e found these DPP-preferred comm unities were enriched in genes related to cell cy- cle c heckpoints, metab olism, DNA repair, predicted breast cancer gene mo dules, and in teractors of sev eral kno wn cancer genes suc h as BR CA2, AA TF, ANP32B, HD AC1, and PRKDC, among others [25]. W e also observ ed enrichmen t in genes down-regulated in acti- v ated T-cells relative to naive T-cells and other im- m une cell types. Although the role of T-cells in tumor imm unity is not fully understo od, recen t work has im- plicated immune cell activity (and T-cell infiltration in general) with breast cancer surviv al [12, 22] and our results both support these findings and potentially widen the set of genes that may need to b e in vestigated further for anti-tumor prop erties. 4.2 Optimal Gridding of Spatial Pro cess Con volution Mo dels W e now demonstrate the method applied to a prob- lem in spatial statistics, namely constructing a non- stationary Gaussian pro cess (GP) mo del in a compu- tationally efficien t w ay . One w ay to construct a GP is to con volv e white noise x ( s ) b y a contin uous func- tion: z ( s ) = k ( s ) ∗ x ( s ) ( s ∈ Ω ⊂ R d ). The result- ing GP has co v ariance R Ω k ( u − d ) k ( u ) du . Higdon et al. [14] suggested to define z ( s ) to b e zero mean GP and instead of defining the cov ariance directly , deter- mine it implicitly through a latent white noise pro cess x ( s ) and smo othing kernel k ( s ). x ( s ) are restricted Man uscript under review (a) (b) 100 120 140 160 180 200 220 240 0 200 400 600 800 1000 1200 Number of Observations Sum of pair−wise Dist. of Grid points Bernoulli−DPP OMP Lasso eNet SpikeSlab DPP−Bernoulli (c) 100 120 140 160 180 200 220 240 4 6 8 10 12 14 16 18 20 22 24 Number of Observations MSE Bernoulli−DPP OMP Lasso eNet SpikeSlab DPP−Bernoulli (d) Figure 3: (a) and (b) show examples of gridding (white circles) and the prediction for Bernoulli-DPP and OMP . The grid p oin ts are spread out in b oth metho ds but OMP suffers from ov ersho oting (or undersho oting) prediction ( e.g., ov er California in (b)). (c) and (d) show the av erage of pairwise distance b etw een selected grid p oints and MSE resp ectiv ely for different num b er of measurements. Diversit y promoting metho ds ( i.e., Bernoulli-DPP , DPP-Bernoulli , OMP ) p erforms similarly in term of div ersity while DPP-related metho d are slightly b etter in term of MSE. SpikeSlab and eNet outp erform other metho ds in term of MSE but as shown in (c) the selected grid p oin ts are muc h closer to eac h other. OMP and DPP-related metho ds seem to hav e a better balance b et ween MSE and having distributed grids particularly for a large num b er of measurements. to b e nonzero at the spatial sites ω 1 , . . . , ω M ∈ Ω and eac h is drawn from N ( · ; 0 , σ 2 x ). The resulting GP is z ( s ) = P M j =1 x j k ( s − ω m ). One can view ω m as (ir- regularly spaced) grid p oin ts. Assuming z is observed with some noise, the problem is equiv alent to regres- sion, where feature selection is e quiv alent to finding the optimal lo cations for the spatial bases. Our ob jectiv e is to find the optimal gridding of spa- tial domain for prediction, while also ensuring a broad spread across the spatial domain. Each grid p oint co vers an areas but here in a 2-D domain. The grid p oin ts are the cen ters of the basis v ectors which are isotropic Gaussian bumps on three differen t scales. Notice that having spatially spread out basis func- tions b oils down to ha ving basis functions with lit- tle ov erlap. Hence diversit y may simply b e com- puted as the inner pro duct b et ween basis vectors, i.e. Φ = X . F or this exp erimen t, the temp era- ture is measured for the month of July at 476 sen- sors located across the United States. W e randomly c ho ose v arying n umber of sensors as a training set and ev aluate the p erformance on the left out sen- sors for all metho ds. This pro cedure was rep eated 20 times and we report the av erage p erformance (MSE) in Figure 3d. Figure 3c rep orts the av erage pair- wise distance b et ween the selected p oints. In term of MSE, b oth DPP-Bernoulli and Bernoulli-DPP per- form b etter than OMP and slightly b etter than Lasso but SpikeSlab outp erforms the other metho ds. How- ev er, as is evident in Figure (c), SpikeSlab do es not pro duce spread out grid p oints whic h w as the main ob- jectiv e. In contrast, DPP-Bernoulli , Bernoulli-DPP and OMP strike a go od balance b et ween prediction and div ersity . Examples of the reconstructions are shown in Figure 3a for Bernoulli-DPP and Figure3b for OMP . OMP tends to ov ersho ot in areas with few measurements – a trait also observed in the sim ulation (see the sup- plemen tary material). It is also interesting to see that when Φ = X having DPP as prior or approximate p osterior p erform similarly . 5 Conclusions In this paper, w e hav e prop osed a probabilistic metho d for diverse feature selection. W e prop osed to approxi- mate the p osterior distribution with DPPs as a com- putationally elegant wa y to encourage diversit y . Our approac h selects the most representativ e items in com- m unities of relev an t items. Similarit y b et ween items can b e enco ded through the inner pro duct b et ween features to discourage collinearit y (similar to OMP) or Man uscript under review ma y be defined based on side information ( e.g., Sec- tion 4.1). Our mo del therefore allows features and similarities to b e different ( Φ 6 = X ). When Φ = X , in the exp erimen ts in Section 4.2, using DPP as an ap- pro ximate p osterior p erforms similarly to using DPP as prior with mean-field approximation. While learning the parameters of DPPs is an activ e re- searc h area, we ha v e shown a computationally efficient strategy for learning the parameters in our v ariational approac h. As far as we kno w, our metho d is the first v ariational metho d used to learn the parameters of a DPP distribution. Our algorithm relies on sampling from the DPP , which in volv es a singular v alue decomp osition (SVD) in each iteration. SVD is not v ery stable for matrices with v ery large condition n umbers, hence it would b e inter- esting to explore other parametrization of DPPs, suc h as those in [1]. An alternative parametrization can hop efully impro ve the condition n umber of the opti- mal kernel matrix L and improv e the p erformance of the MAP approximation [10]. In conclusion, imposing DPP as an appro ximate pos- terior selects more diverse features without compro- mising the accuracy; further, it allows for sampling- based quantification of uncertaint y . If the p osterior distribution is multi-modal, sampling from the mo del can provide an alternative solution - something not p ossible with OMP . In fact, the simulated examples demonstrated that DPP is more robust than OMP (see supplemen t). A Algorithm for Posterior Appro ximation The Algorithm 1 can b e used to approximate the p osterior for both DPP-Bernoulli and Bernoulli-DPP . F or Bernoulli-DPP , w e set p ( γ ) = Q M m =1 α γ m (1 − α ) 1 − γ m . In case of DPP-Bernoulli , DPP and Bernoulli ( i.e., fully factorized p osterior) are deploy ed as the prior and the appro ximate posterior resp ectiv ely . W e just need to mo dify p ( γ ) = det([ L ] γ ) det( L + I ) and Φ = I . *Bibliograph y [1] R. H. Affandi, E. B. F o x, R. P . Adams, and B. T ask ar. Learning the Parameters of Determinantal Poin t Pro- cess Kernels, F ebruary 2014. [2] YY Ahn, JP Bagro w, and S Lehmann. Link comm uni- ties reveal multiscale complexity in net works. Natur e , 466(7307):761–764, 2006. [3] M. Beal and Z. Ghahramani. The v ariational Bay esian EM algorithm for incomplete data: with applica- tion to scoring graphical model structures. Bayesian Statistics , 7:1–10, 2003. Algorithm 1: V ariational Learning for Div erse V ari- able Selection Input : Similarit y features Φ , a function to compute/appro ximate the restricted marginal lik eliho o d p ( y | γ ), p ( γ ), initial cardinality of DPP κ , num b er of iterations: N . Output : Parameters of the p osterior ( q ): θ 1 Adjust exp ected cardinality of the DPP b y solving for θ 0 in P i e θ 0 λ i 1+ λ i e θ 0 = κ ; 2 Initialize θ = θ 0 l , L = e θ 0 / 2 ΦΦ T e θ 0 / 2 , and K = L ( L + I ) − 1 ; 3 Set ( C 1 ) ii = K ii , g 1 = C 1 ˜ θ , and ¯ C , ¯ g = 0 ; 4 for t ← 1 to N do 5 Dra w a set from current p osterior approximation DPP: γ ∗ t ∼ q ˜ θ t ; 6 Set ˆ g t = ˜ γ ∗ t log p ( y | γ ∗ t ) p ( γ ∗ t ) ; 7 Set ˆ C t = ˜ γ ∗ t ˜ γ ∗ t T or current estimate of K θ t ; 8 Set g t +1 = (1 − w ) g t + w ˆ g t ; 9 Set C t +1 = (1 − w ) C t + w ˆ C t ; 10 Solv e ˜ θ t +1 = C − 1 t +1 g t +1 ; 11 if t > N / 2 then 12 Set ¯ g = ¯ g + ˆ g t ; 13 Set ¯ C = ¯ C + ˆ C t ; 14 return θ = ¯ C − 1 ¯ g ; [4] P . Carb onetto, M. Stephens, et al. Scalable v aria- tional inference for Ba yesian v ariable selection in re- gression, and its accuracy in genetic asso ciation stud- ies. Bayesian Analysis , 7(1):73–108, 2012. [5] B. P Carlin and T. A Louis. Bayes and empiric al Bayes metho ds for data analysis . CRC Press, 2008. ISBN ISBN 1-58488-697-8. [6] A. Das and D. Kemp e. Submodular meets sp ectral: Greedy algorithms for subset selection, sparse ap- pro ximation and dictionary selection. arXiv pr eprint arXiv:1102.3975 , 2011. [7] S. F ortunato. Communit y detection in graphs. Physics R eports , 486(3):75–174, 2010. [8] M. Garcia-Closas, P . Hall, H. Nev anlinna, K. Poo- ley , J. Morrison, D. A Richesson, S. E Bo jesen, B. G Nordestgaard, C. K Axelsson, J. I Arias, et al. Hetero- geneit y of breast cancer asso ciations with five suscep- tibilit y lo ci by clinical and pathological characteristics. PL oS genetics , 4(4):e1000054, 2008. [9] Edward I George et al. Dilution priors: Com- p ensating for mo del space redundancy . In Bor- r owing Strength: The ory Powering Applic ations–A F estschrift for L awr enc e D. Br own , pages 158–165. In- stitute of Mathematical Statistics, 2010. [10] J. Gillenw ater, A. Kulesza, and B. T ask ar. Near- Optimal MAP Inference for Determinan tal Poin t Pro- cesses. In P eter L. Bartlett, F ernando C. N. Pereira, Christopher J. C. Burges, L´ eon Bottou, and Kilian Q. W einberger, editors, NIPS , pages 2744–2752, 2012. Man uscript under review [11] E. Grav e, G. Ob ozinski, F. Bach, et al. T race Lasso: a trace norm regularization for correlated designs. In NIPS , volume 2, page 5, 2011. [12] C et al. Gu-T rantien. CD4+ follicular help er T cell infiltration predicts breast cancer surviv al. J. Clin. Invest. , 123(7):2873–2892, 2013. [13] I. Guy on and A. Elisseeff. An introduction to v ari- able and feature selection. The Journal of Machine L earning R ese ar ch , 3:1157–1182, 2003. [14] D. Higdon. A process-conv olution approach to mo d- elling temp eratures in the North Atlan tic Ocean. En- vir onmental and Ec olo gic al Statistics , 5(2):173–190, 1998. [15] A. Honk ela, T. Raik o, M. Kuusela, M. T ornio, and J. Karhunen. Approximate Riemannian conjugate gradien t learning for fixed-form v ariational Ba yes. The Journal of Machine L e arning R ese ar ch , 9999:3235– 3268, 2010. [16] A. Kulesza and B. T ask ar. Determinan tal p oin t pro cesses for machine learning. arXiv pr eprint arXiv:1207.6083 , 2012. [17] I. Lee, U M. Blom, P . I W ang, J. Eun Shim, and E. M Marcotte. Prioritizing candidate disease genes b y netw ork-based b oosting of genome-wide asso cia- tion data. Genome r ese arch , 21(7):1109–1121, 2011. [18] T. J Mitchell and J. J Beauchamp. Bay esian v ariable selection in linear regression. Journal of the Americ an Statistic al Asso ciation , 83(404):1023–1032, 1988. [19] G. L Nemhauser, L. A W olsey , and M. L Fisher. An analysis of approximations for maximizing submo du- lar set functions - I. Mathematic al Pr ogr amming , 14 (1):265–294, 1978. [20] Cancer Genome Atlas Netw ork. Comprehensiv e molecular portraits of h uman breast tumours. Natur e , 490(7418):61–70, 2012. [21] Y. Chandra Pati, R. Rezaiifar, and PS Krishnaprasad. Orthogonal matching pursuit: Recursive function ap- pro ximation with applications to w av elet decomp osi- tion. In Signals, Systems and Computers, 1993. 1993 Confer ence R ec or d of The Twenty-Seventh Asilomar Confer ence on , pages 40–44. IEEE, 1993. [22] I Peguillet, M Milder, et al. High num b ers of dif- feren tiated effector CD4 T cells are found in patients with cancer and correlate with clinical response after neoadjuv ant therapy of breast cancer. Canc er R es. , 74(8):2204–2216, 2014. [23] T. Salimans and D. A. Knowles. Fixed-F orm V ari- ational Posterior Appro ximation through Sto c hastic Linear Regression. CoRR , abs/1206.6679, 2012. [24] C Stark, BJ Breitkreutz, T Reguly , L Bouc her, A Bre- itkreutz, and A T yers. BioGRID: a general rep ository for interaction datasets. Nucleic A cids R es. , 34(D): 535–539, 2006. [25] A Subramanian, P T amay o, VK Mo otha, S Mukher- jee, BL Eb ert, MA Gillette, A Paulo vich, SL P omeroy , TR Golub, ES Lander, and JP Mesirov. Gene set enric hment analysis: a knowledge-based approach for in terpreting genome-wide expression profiles. PNAS , 102(43):15545–15550, 2005. [26] R. Tibshirani. Regression shrink age and selection via the lasso. Journal of the R oyal Statistic al So ciety. Se- ries B (Metho dolo gic al) , pages 267–288, 1996. [27] J. A T ropp and A. C Gilb ert. Signal recov ery from random measurements via orthogonal matc hing pur- suit. Information The ory, IEEE T r ansactions on , 53 (12):4655–4666, 2007. [28] H. Zou and T. Hastie. Regularization and v ariable selection via the elastic net. Journal of the R oyal Sta- tistic al So ciety: Series B (Statistic al Metho dolo gy) , 67 (2):301–320, 2005.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment