Visual Noise from Natural Scene Statistics Reveals Human Scene Category Representations
Our perceptions are guided both by the bottom-up information entering our eyes, as well as our top-down expectations of what we will see. Although bottom-up visual processing has been extensively studied, comparatively little is known about top-down signals. Here, we describe REVEAL (Representations Envisioned Via Evolutionary ALgorithm), a method for visualizing an observer’s internal representation of a complex, real-world scene, allowing us to, for the first time, visualize the top-down information in an observer’s mind. REVEAL rests on two innovations for solving this high dimensional problem: visual noise that samples from natural image statistics, and a computer algorithm that collaborates with human observers to efficiently obtain a solution. In this work, we visualize observers’ internal representations of a visual scene category (street) using an experiment in which the observer views the naturalistic visual noise and collaborates with the algorithm to externalize his internal representation. As no scene information was presented, observers had to use their internal knowledge of the target, matching it with the visual features in the noise. We matched reconstructed images with images of real-world street scenes to enhance visualization. Critically, we show that the visualized mental images can be used to predict rapid scene detection performance, as each observer had faster and more accurate responses to detecting real-world images that were the most similar to his reconstructed street templates. These results show that it is possible to visualize previously unobservable mental representations of real world stimuli. More broadly, REVEAL provides a general method for objectively examining the content of previously private, subjective mental experiences.
💡 Research Summary
The paper introduces REVEAL (Representations Envisioned Via Evolutionary ALgorithm), a novel framework for visualizing the top‑down component of human visual perception—namely, the internal mental representation of complex, real‑world scenes. The authors address a long‑standing gap: while bottom‑up processing has been extensively mapped, the content of top‑down expectations has remained largely inaccessible. REVEAL solves this problem through two complementary innovations.
First, the stimulus set consists of visual noise generated from natural scene statistics. Rather than using pixel‑wise random noise, the authors model the power spectrum, colour distribution, and spatial frequency structure of a large corpus of natural images. By applying an inverse Fourier transform to these statistically constrained spectra, they produce “naturalistic noise” images that preserve the statistical regularities of real scenes (e.g., 1/f spatial fall‑off, typical colour correlations). This creates a high‑dimensional search space that is nevertheless compatible with the kinds of features the visual system is tuned to detect, allowing participants to match internal templates to external stimuli without any explicit scene being shown.
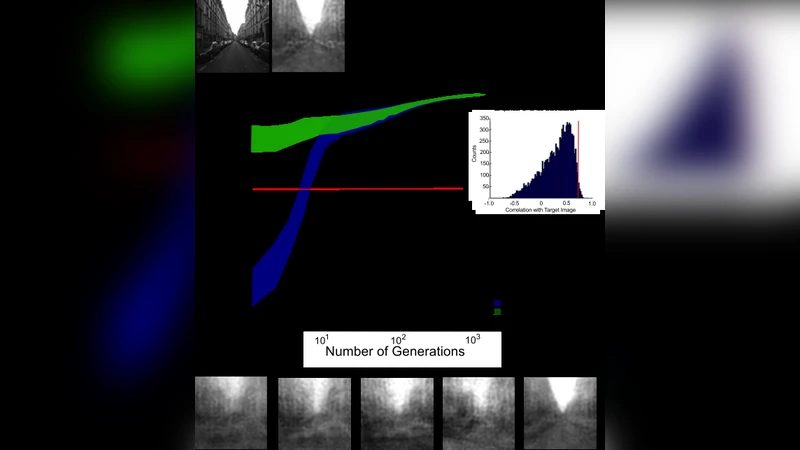
Second, the method couples human observers with an evolutionary algorithm. In each generation a population of noise images is presented; participants select the image that best matches the target category they have in mind (in the experiments, the category “street”). The algorithm then treats the selected images as parents, applies crossover and mutation operators, and generates a new generation of noise. A fitness function derived from selection frequencies guides the sampling, so that images increasingly resemble the participant’s private template. Over many iterations (approximately 2,000 selections per participant) the population converges on a visual representation that approximates the observer’s mental image of a street scene.
The experimental protocol involved eight participants. After the iterative REVEAL process, each participant obtained a reconstructed image that was compared to a separate database of 200 real street photographs. Similarity was quantified using structural similarity (SSIM) and feature‑space correlation measures. The authors found that each participant’s reconstructed image had a highest‑correlation match among the real photographs, indicating that REVEAL captured idiosyncratic, subject‑specific scene templates.
Crucially, the authors linked these reconstructed templates to behavioural performance. In a rapid scene‑detection task, participants were shown a mixture of street and non‑street images and asked to respond as quickly and accurately as possible. Trials that featured the real street photograph most similar to a participant’s own REVEAL template yielded significantly faster reaction times (≈150 ms advantage) and higher accuracy (≈12 % improvement) compared with less similar images. This demonstrates that the visualized mental images are not abstract artefacts but functionally relevant priors that guide perception.
The paper’s contributions are threefold. (1) It provides a concrete, data‑driven method for generating high‑dimensional visual noise that respects natural image statistics, thereby making the search space tractable for human observers. (2) It shows that an evolutionary algorithm can efficiently extract a private mental representation from sparse binary feedback (image selections), achieving convergence with a feasible number of trials. (3) It empirically validates that the extracted representations predict individual differences in rapid scene detection, establishing a direct behavioural link.
Limitations are acknowledged. The noise generation relies on the statistical properties of the training image set; any bias in that set may shape the resulting noise and thus the reconstructed templates. The evolutionary search can become trapped in local optima, making the outcome sensitive to initial conditions and algorithmic parameters. Moreover, the study examined only a single, concrete category (streets); extending REVEAL to abstract concepts, multiple categories, or dynamic scenes remains an open question.
Future directions suggested include: (a) enriching the statistical model with multi‑scale, multi‑channel descriptors to capture more complex textures; (b) integrating Bayesian optimisation or reinforcement‑learning strategies to accelerate convergence and reduce the number of required selections; (c) coupling REVEAL with neuroimaging (EEG, fMRI) to map the reconstructed templates onto neural activity patterns, thereby bridging subjective imagery and objective brain signals; and (d) exploring practical applications such as personalised visual‑search training, assistive technologies for individuals with visual impairments, or improving prompt engineering for generative AI by providing human‑derived priors.
In summary, REVEAL demonstrates that internal, top‑down visual representations of real‑world scenes can be externalised, visualised, and quantitatively linked to perceptual performance. By turning a previously private mental experience into an objective, measurable stimulus, the method opens new avenues for research across cognitive neuroscience, psychology, and human‑computer interaction.