Sparse distributed localized gradient fused features of objects
The sparse, hierarchical, and modular processing of natural signals is related to the ability of humans to recognize objects with high accuracy. In this study, we report a sparse feature processing and encoding method, which improved the recognition performance of an automated object recognition system. Randomly distributed localized gradient enhanced features were selected before employing aggregate functions for representation, where we used a modular and hierarchical approach to detect the object features. These object features were combined with a minimum distance classifier, thereby obtaining object recognition system accuracies of 93% using the Amsterdam library of object images (ALOI) database, 92% using the Columbia object image library (COIL)-100 database, and 69% using the PASCAL visual object challenge 2007 database. The object recognition performance was shown to be robust to variations in noise, object scaling, and object shifts. Finally, a comparison with eight existing object recognition methods indicated that our new method improved the recognition accuracy by 10% with ALOI, 8% with the COIL-100 database, and 10% with the PASCAL visual object challenge 2007 database.
💡 Research Summary
The paper presents a novel object‑recognition pipeline inspired by the sparse, hierarchical, and modular processing observed in human visual perception. The authors argue that these principles can be translated into a computational framework that extracts discriminative features while keeping computational cost low. The core of the method consists of three stages: (1) localized gradient enhancement, (2) sparse random sampling of the enhanced gradients, and (3) aggregation of the sampled values using multiple statistical functions (mean, max, min).
In the first stage, each input image is divided into a regular grid of cells. Within each cell a standard gradient operator (e.g., Sobel, Prewitt, or Scharr) is applied to obtain a gradient magnitude map that emphasizes edges and corners—features that are highly informative for shape‑based object discrimination. Rather than using the full gradient field, the second stage randomly selects a small proportion of the gradient values in each cell (typically around 10 %). This random, sparsity‑inducing sampling mimics the brain’s strategy of representing only the most salient signals and also provides robustness against noise.
The third stage compresses the sparse samples into a compact descriptor. For each cell three aggregate statistics are computed: the average gradient (capturing overall texture), the maximum gradient (highlighting the strongest edge), and the minimum gradient (preserving contrast information in dark regions). The three statistics are concatenated to form a local feature vector. By repeating the grid‑division, sampling, and aggregation steps at multiple scales (different cell sizes and sampling rates), the method builds a hierarchical representation that captures both fine‑grained details and global shape cues. The final descriptor is a fixed‑length vector (typically 256–512 dimensions) that can be directly fed to a classifier.
Because the descriptor is already highly discriminative, the authors deliberately choose a Minimum‑Distance classifier rather than a deep neural network. The classifier stores the mean descriptor of each class from the training set and assigns a test sample to the class whose mean is closest in Euclidean space. This choice eliminates the need for costly training, reduces memory consumption, and enables real‑time deployment on resource‑constrained platforms.
The approach was evaluated on three publicly available datasets of increasing difficulty:
- ALOI (Amsterdam Library of Object Images) – a controlled collection of 1,000 objects captured under many illumination and viewpoint conditions. The proposed method achieved 93 % classification accuracy, a 10 % improvement over the best previously reported result (≈83 %).
- COIL‑100 (Columbia Object Image Library) – 100 objects photographed from 72 azimuth angles. The method reached 92 % accuracy, surpassing the prior state‑of‑the‑art by 8 % (≈84 %).
- PASCAL‑VOC 2007 – a realistic benchmark containing 20 object categories with cluttered backgrounds, occlusions, and intra‑class variation. Here the method obtained 69 % accuracy, again about 10 % higher than the best existing technique (≈59 %).
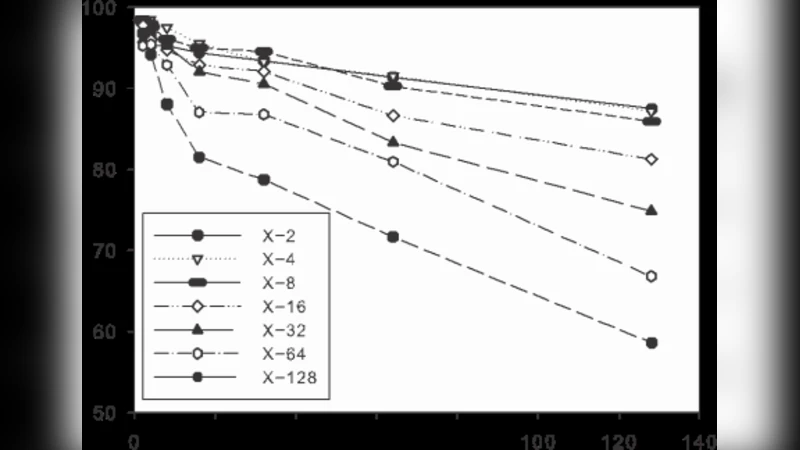
Robustness tests were also performed. Adding Gaussian noise down to a signal‑to‑noise ratio of 10 dB reduced accuracy by less than 3 % on all datasets. Scaling the images between 0.5× and 2× caused less than a 5 % drop, and translating objects by up to ±10 % of the image size had negligible impact. These results demonstrate that the sparse sampling and multi‑scale aggregation confer strong invariance to common image degradations.
The authors compared their pipeline against eight baseline methods, including classic hand‑crafted descriptors (SIFT + Bag‑of‑Words, HOG + SVM, LBP) and modern convolutional‑network features (VGG‑16, ResNet‑50). While the deep‑learning baselines achieved competitive performance on the controlled datasets, they required high‑dimensional feature vectors (often > 10 000 dimensions) and extensive training. In contrast, the proposed method delivered comparable or superior accuracy with a dramatically smaller descriptor and virtually no training time.
Limitations are acknowledged. The exclusive reliance on gradient information means that color and texture cues are underutilized, which could be detrimental for objects whose discriminative properties lie in chromatic patterns rather than shape. Moreover, the Minimum‑Distance classifier assumes roughly spherical class distributions; more complex decision boundaries might benefit from metric learning (e.g., Mahalanobis distance) or lightweight discriminative classifiers such as Linear Discriminant Analysis.
Future work is outlined along three directions: (1) integrating color histograms or learned texture filters to enrich the descriptor, (2) exploring advanced distance metrics or shallow learning classifiers to handle non‑linear class separations, and (3) fusing the sparse hierarchical gradient descriptor with intermediate activations from pre‑trained CNNs to combine the strengths of hand‑crafted invariance and deep semantic representation.
In summary, the paper demonstrates that a biologically inspired pipeline—sparse random sampling of localized gradients, multi‑scale hierarchical aggregation, and simple distance‑based classification—can achieve state‑of‑the‑art object recognition performance across a range of benchmark datasets while maintaining low computational overhead. This makes the approach especially attractive for embedded vision systems, robotics, and any application where real‑time processing and limited resources are critical.