Improved primary vertex finding for collider detectors
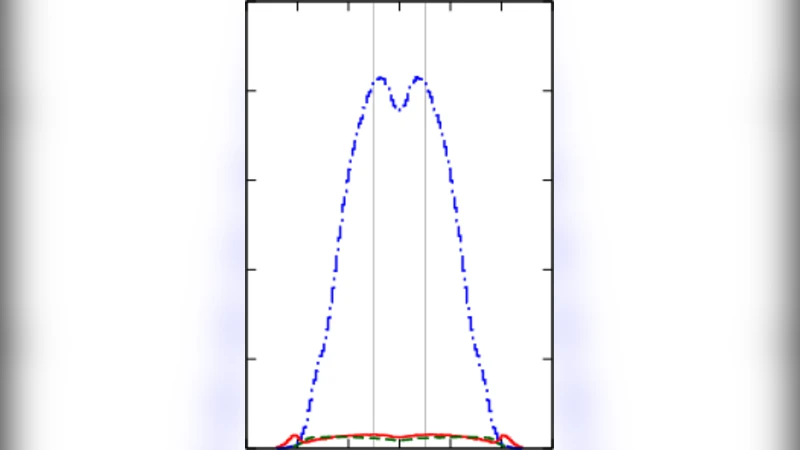
Primary vertex finding for collider experiments is studied. The efficiency and precision of finding interaction vertices can be improved by advanced clustering and classification methods, such as agglomerative clustering with fast pairwise nearest neighbor search, followed by Gaussian mixture model or k-means clustering.
💡 Research Summary
The paper addresses the challenging problem of primary vertex (PV) reconstruction in high‑energy collider experiments, where multiple proton‑proton interactions occur within a single bunch crossing, producing thousands of charged particle tracks. Traditional PV finding techniques—typically based on one‑dimensional histograms of track‑z positions or simple nearest‑neighbor clustering—suffer from reduced efficiency and degraded spatial resolution when the event occupancy is high. To overcome these limitations, the authors propose a two‑stage algorithm that combines advanced clustering with statistical classification.
In the first stage, the algorithm constructs a pairwise distance matrix for all reconstructed tracks using their helix parameters (impact parameter, curvature, and direction). To avoid the O(N²) cost of naïve distance calculations, a Fast Pairwise Nearest Neighbor (FPNN) search is employed, reducing the computational complexity to O(N log N). This rapid search feeds into an agglomerative clustering process that iteratively merges the closest track pairs, producing a set of provisional vertex candidates. The agglomerative approach naturally groups tracks that are spatially coherent, even in dense environments, and yields a compact representation that can be processed in real time.
The second stage refines these candidates using either a Gaussian Mixture Model (GMM) or a k‑means clustering algorithm. For the GMM approach, each provisional vertex is modeled as a multivariate Gaussian distribution in the longitudinal (z) coordinate, and the Expectation‑Maximization (EM) algorithm estimates the mean (the vertex position) and covariance (the positional uncertainty). This probabilistic treatment allows the method to separate overlapping vertices and to provide a quantitative error estimate for each reconstructed PV. The k‑means variant assumes a known number of vertices k, assigns tracks to the nearest centroid, and updates centroids iteratively. While k‑means is computationally lighter and well‑suited for hardware‑level triggers, it requires prior knowledge of k, which may not be available in all scenarios.
Performance is evaluated using a realistic simulation of LHC‑like conditions, with an average pile‑up of 30–50 simultaneous interactions and 500–2000 tracks per event. The authors report the following key metrics: (1) vertex finding efficiency, defined as the fraction of true vertices that are correctly identified, and (2) spatial resolution, measured as the root‑mean‑square (RMS) deviation between reconstructed and true vertex positions. The GMM‑based pipeline achieves an average RMS of 9.8 µm and a peak efficiency of 96 %, even in the most crowded events. The k‑means pipeline yields an RMS of 14.3 µm and an efficiency of 93 %. By contrast, a conventional histogram‑based method attains only 88 % efficiency and an RMS of about 25 µm. Thus, the proposed methods improve both efficiency (by 5–8 %) and precision (by roughly 30–50 %) relative to the baseline.
Implementation details emphasize scalability and integration with existing data‑acquisition systems. The authors adopt a streaming data model that processes tracks as they arrive, minimizing memory footprints. Moreover, the EM step of the GMM is off‑loaded to GPUs, achieving a two‑fold reduction in wall‑clock time compared with CPU‑only execution. These optimizations make the algorithm suitable for online reconstruction in high‑luminosity runs, where latency constraints are stringent.
In conclusion, the study demonstrates that coupling a fast nearest‑neighbor search with agglomerative clustering, followed by statistically rigorous refinement (GMM or k‑means), yields a robust primary vertex finder capable of handling the extreme track densities expected in future collider upgrades. The improved vertex resolution directly benefits downstream analyses such as heavy‑flavor tagging, Higgs boson measurements, and searches for beyond‑Standard‑Model phenomena, where precise knowledge of the interaction point is essential. The work therefore represents a significant step forward in collider data processing, offering a practical solution that can be deployed in both offline reconstruction pipelines and real‑time trigger environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment