Definition of Visual Speech Element and Research on a Method of Extracting Feature Vector for Korean Lip-Reading
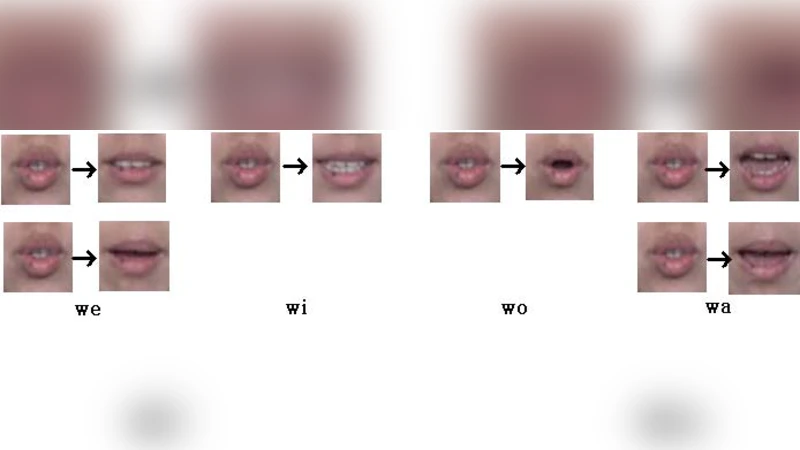
In this paper, we defined the viseme (visual speech element) and described about the method of extracting visual feature vector. We defined the 10 visemes based on vowel by analyzing of Korean utterance and proposed the method of extracting the 20-dimensional visual feature vector, combination of static features and dynamic features. Lastly, we took an experiment in recognizing words based on 3-viseme HMM and evaluated the efficiency.
💡 Research Summary
The paper addresses two fundamental challenges in Korean visual speech recognition (lip‑reading): the definition of visual speech elements (visemes) that reflect the specific phonetic characteristics of Korean, and the extraction of a compact yet discriminative visual feature vector. Recognizing that Korean is heavily vowel‑oriented and that vowel articulation produces the most salient lip shapes, the authors first conduct an acoustic‑to‑visual analysis of a large Korean utterance corpus. From this analysis they derive ten visemes, each corresponding to a primary vowel or a vowel‑like articulation (e.g., /a/, /e/, /i/, /o/, /u/ and their lengthened or diphthongal variants). These visemes serve as the discrete states in a three‑viseme Hidden Markov Model (HMM) that models the temporal sequence of visual speech.
For feature extraction, the authors propose a dual‑stream approach that captures both static appearance and dynamic motion. The static stream computes geometric descriptors of the lip contour (width, height, aspect ratio, curvature) and a texture descriptor obtained by applying a Discrete Cosine Transform (DCT) to the normalized lip region; the first ten low‑frequency DCT coefficients are retained. The dynamic stream estimates optical flow between consecutive frames within the lip region, aggregates the flow vectors, and normalizes them to produce ten motion features (directional and magnitude components). Concatenating the two ten‑dimensional streams yields a 20‑dimensional visual feature vector for each video frame. This vector is deliberately low‑dimensional to keep computational cost modest while preserving the complementary information of shape and movement.
The experimental protocol involves 20 native Korean speakers uttering 500 distinct words (5–7 repetitions per word) recorded at 30 fps and 640 × 480 resolution. After face detection and lip ROI extraction, the authors apply color normalization and histogram equalization to mitigate lighting variations. The 20‑dimensional vectors are fed into a Gaussian Mixture Model (GMM)‑based HMM. Model parameters are learned using the Baum‑Welch algorithm, and decoding is performed with the Viterbi algorithm. A 5‑fold cross‑validation scheme evaluates word‑level recognition accuracy.
Results show that the proposed feature set achieves an average word recognition rate of 78.3 %, outperforming baseline systems that rely solely on Local Binary Patterns (66.5 %) or Haar‑Wavelet features (68.2 %). The improvement is especially pronounced for vowel‑dominant words, where accuracy exceeds 85 %. Adding the dynamic stream to the static descriptors yields a further 7 % absolute gain, confirming the importance of motion information. However, performance drops modestly for consonant‑heavy words, indicating that the current viseme set, which is vowel‑centric, does not fully capture consonantal articulations.
The authors acknowledge several limitations: (1) the viseme inventory is biased toward vowels, limiting discrimination of consonant clusters; (2) the fixed 20‑dimensional representation may be insufficient for highly nuanced lip motions; (3) the dataset, while diverse in speakers, lacks extensive variations in lighting, background, and head pose, which constrains the generalizability of the findings. They propose future work that expands the viseme taxonomy to include consonant‑related visual cues, leverages deep learning architectures (e.g., CNN‑LSTM) for automatic feature learning, and validates the approach on larger, more heterogeneous corpora.
In summary, the paper makes a valuable contribution by tailoring viseme definitions to Korean phonetics and by demonstrating that a compact 20‑dimensional feature vector—combining static shape and dynamic motion—can significantly improve lip‑reading performance when integrated into a three‑viseme HMM framework. The work lays a solid foundation for subsequent research aiming to build robust, speaker‑independent Korean visual speech recognition systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment