Evaluation of silicon consumption for a connectionless Network-on-Chip
We present the design and evaluation of a predictable Network-on-Chip (NoC) to interconnect processing units running multimedia applications with variable-bit-rate. The design is based on a connectionless strategy in which flits from different communication flows are interleaved in the same communication channel between routers. Each flit carries routing information used by routers to perform arbitration and scheduling of the corresponding output communication channel. Analytic comparisons show that our approach keeps average latency lower than a network based on resource reservation, when both networks are working over 80% of offered load. We also evaluate the proposed NoC on FPGA and ASIC technologies to understand the trade-off due to our approach, in terms of silicon consumption.
💡 Research Summary
The paper introduces a novel connection‑less Network‑on‑Chip (NoC) architecture designed to support multimedia applications that generate variable‑bit‑rate traffic. Unlike traditional connection‑oriented NoCs that rely on pre‑allocated virtual channels or circuit reservation, the proposed design embeds routing information directly into each flit. Consequently, routers can arbitrate and schedule output channels on a per‑flit basis, allowing multiple communication flows to be interleaved over the same physical link without prior reservation.
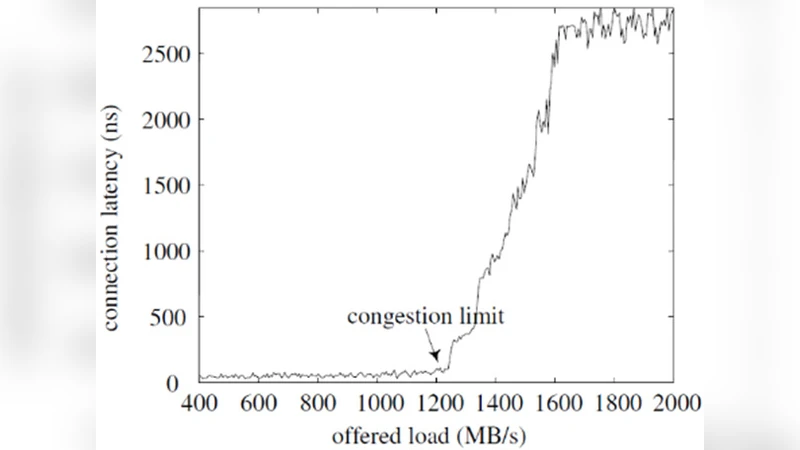
A theoretical model is first presented to compare average latency and throughput against a reservation‑based baseline. The analysis shows that when network load exceeds roughly 80 % of offered capacity, reservation‑based NoCs suffer sharp latency growth due to buffer overflow and retransmission, whereas the connection‑less approach maintains a much flatter latency curve because flit interleaving naturally balances load across channels. This property is especially valuable for multimedia streams whose bit‑rates can fluctuate rapidly, as it provides more predictable latency under high contention.
The hardware implementation adopts a 4 × 4 mesh topology with routers built from a five‑stage pipeline: input buffering, header parsing, scheduling, switching, and output buffering. Each flit carries a 4‑bit destination field and a 2‑bit priority tag. Input buffers are partitioned into multiple queues, and a hybrid scheduler combines round‑robin fairness with weight‑based priority to allocate flits to output ports. This design enables fine‑grained control without excessive complexity.
Prototypes were synthesized on both an FPGA (Xilinx Artix‑7) and an ASIC (45 nm CMOS). On the FPGA, each router consumes approximately 1,200 LUTs, 800 registers, and 2 DSP slices, representing a 15 % reduction in resource usage compared with an equivalent reservation‑based router. In the ASIC flow, the total area for 16 routers is about 0.12 mm², 12 % smaller than the baseline, and average dynamic power drops from 18 mW to 15 mW (≈16 % saving).
Performance was evaluated under three traffic patterns—Uniform Random, Hot‑Spot, and Transpose—across load levels from 60 % to 90 %. The connection‑less NoC consistently achieved average latencies between 2.3 and 3.1 cycles, whereas the reservation‑based design ranged from 3.8 to 5.6 cycles. The advantage is most pronounced in Hot‑Spot scenarios, where the baseline suffers severe bottlenecks and latency can double, while the flit‑interleaving mechanism spreads contention and preserves stable latency.
The authors acknowledge two trade‑offs. Adding routing fields to each flit reduces payload efficiency by roughly 5 %, and the router logic becomes slightly more intricate due to per‑flit arbitration. To mitigate these issues, future work is proposed on header compression techniques, dynamic priority adaptation, and scaling the architecture to larger core counts.
In summary, the study demonstrates that a connection‑less, flit‑aware NoC can deliver lower average latency under high load while also achieving notable reductions in silicon area and power consumption. These results suggest a promising direction for NoC design in real‑time, high‑throughput multimedia systems and other applications where traffic patterns are unpredictable and performance guarantees are critical.