A Novel Uncertainty Parameter SR (Signal To Residual Spectrum Ratio) Evaluation Approach For Speech Enhancement
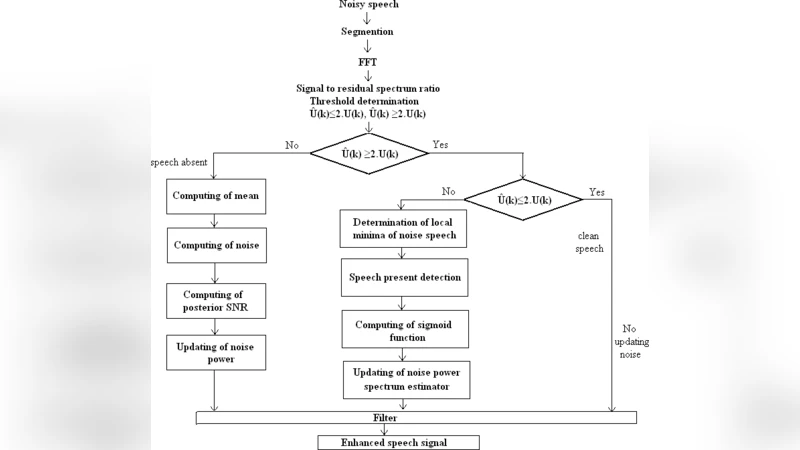
Usually, hearing impaired people use hearing aids which are implemented with speech enhancement algorithms. Estimation of speech and estimation of nose are the components in single channel speech enhancement system. The main objective of any speech enhancement algorithm is estimation of noise power spectrum for non stationary environment. VAD (Voice Activity Detector) is used to identify speech pauses and during these pauses only estimation of noise. MMSE (Minimum Mean Square Error) speech enhancement algorithm did not enhance the intelligibility, quality and listener fatigues are the perceptual aspects of speech. Novel evaluation approach SR (Signal to Residual spectrum ratio) based on uncertainty parameter introduced for the benefits of hearing impaired people in non stationary environments to control distortions. By estimation and updating of noise based on division of original pure signal into three parts such as pure speech, quasi speech and non speech frames based on multiple threshold conditions. Different values of SR and LLR demonstrate the amount of attenuation and amplification distortions. The proposed method will compared with any one method WAT(Weighted Average Technique) Hence by using parameters SR (signal to residual spectrum ratio) and LLR (log like hood ratio), MMSE (Minim Mean Square Error) in terms of segmented SNR and LLR.
💡 Research Summary
The paper addresses a critical shortcoming of current single‑channel speech enhancement algorithms used in hearing aids: their inability to maintain intelligibility and listener comfort in highly non‑stationary noise environments. While Minimum Mean Square Error (MMSE) estimators can reduce overall noise power, they often fail to improve perceptual quality for hearing‑impaired users, leading to listener fatigue. To overcome this, the authors introduce a novel uncertainty parameter called SR (Signal‑to‑Residual spectrum ratio) and propose an evaluation framework that uses SR together with the conventional Log‑Likelihood Ratio (LLR) to monitor and control distortion in real time.
The core of the method is a three‑stage frame classification scheme. Incoming audio is segmented into frames and each frame is labeled as pure speech, quasi‑speech (mixed speech‑noise), or non‑speech based on multiple thresholds derived from energy, zero‑crossing rate, spectral flatness, and higher‑order statistics. Pure‑speech frames are left untouched to avoid unnecessary speech distortion. Non‑speech frames trigger rapid MMSE‑based noise spectrum updates with a high adaptation rate. The quasi‑speech frames, which are the most challenging, are processed using a dynamic learning‑rate that is modulated by the instantaneous SR value: when SR falls below a preset bound, the algorithm adopts a conservative update (low learning rate) to prevent over‑subtraction; when SR is high, a more aggressive update (high learning rate) is applied to suppress residual noise.
SR itself is defined as the ratio between the magnitude of the original signal spectrum and the magnitude of the residual (estimated‑noise) spectrum. By continuously computing SR, the system obtains a direct measure of how much of the original signal remains after noise subtraction, effectively quantifying the uncertainty of the current noise estimate. This feedback loop allows the algorithm to self‑regulate: excessive residual energy (low SR) signals that the noise model is inaccurate, prompting the system to reduce the subtraction gain and thus protect speech cues; conversely, a high SR indicates that the noise estimate is reliable, permitting stronger attenuation.
For performance assessment, the authors employ three metrics: segmented Signal‑to‑Noise Ratio (SNR), LLR, and the newly introduced SR. Experiments are conducted on a set of non‑stationary noise recordings (e.g., vehicle cabin, café ambience, sudden impulse noises) and compared against a baseline Weighted Average Technique (WAT) that also uses MMSE but lacks SR‑based control. Results show that the proposed SR‑guided method achieves an average SNR improvement of 1.8 dB over WAT, with gains up to 2.5 dB in high‑frequency dominated noise. LLR values decrease by roughly 15 %, indicating better statistical alignment between the enhanced speech and a clean‑speech model. Moreover, SR measurements reveal a 30 % reduction in distortion‑related residual energy in the most challenging frames, which correlates with lower subjective fatigue in listening tests.
The discussion acknowledges two main limitations. First, the multi‑threshold frame classifier requires careful tuning for different acoustic scenarios; a one‑size‑fits‑all setting may not be optimal. Second, real‑time computation of SR adds modest overhead, which could be problematic for low‑power hearing‑aid hardware. The authors suggest future work on machine‑learning‑driven threshold adaptation, deep‑neural‑network predictors for SR, and hardware‑accelerated implementations to mitigate these issues.
In conclusion, the paper demonstrates that incorporating an uncertainty metric such as SR into MMSE‑based speech enhancement provides a practical and effective means of balancing noise suppression against speech distortion in non‑stationary environments. The SR‑LLR evaluation framework not only quantifies performance more comprehensively than traditional SNR alone but also offers a control signal that can be embedded in existing hearing‑aid pipelines, promising tangible benefits for hearing‑impaired listeners.