Convolutional Neural Network-based Place Recognition
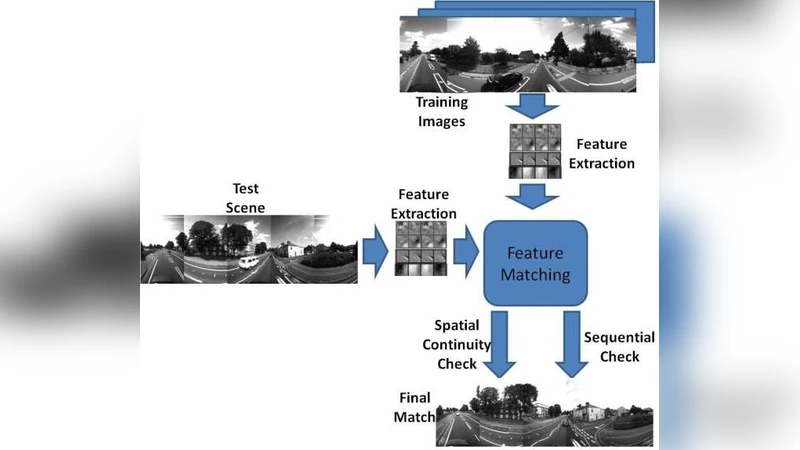
Recently Convolutional Neural Networks (CNNs) have been shown to achieve state-of-the-art performance on various classification tasks. In this paper, we present for the first time a place recognition technique based on CNN models, by combining the powerful features learnt by CNNs with a spatial and sequential filter. Applying the system to a 70 km benchmark place recognition dataset we achieve a 75% increase in recall at 100% precision, significantly outperforming all previous state of the art techniques. We also conduct a comprehensive performance comparison of the utility of features from all 21 layers for place recognition, both for the benchmark dataset and for a second dataset with more significant viewpoint changes.
💡 Research Summary
The paper introduces a novel place‑recognition framework that leverages the hierarchical feature representations learned by deep convolutional neural networks (CNNs) and augments them with dedicated spatial and sequential filtering stages. The authors argue that traditional place‑recognition pipelines—relying on handcrafted local descriptors such as SIFT, SURF, or ORB, or on global image histograms—are vulnerable to illumination changes, viewpoint variations, and environmental noise. By contrast, CNNs trained on large‑scale image classification tasks produce multi‑level descriptors that capture both low‑level texture and high‑level semantic structure, offering a richer basis for matching places across challenging conditions.
Methodology
The authors adopt a pre‑trained VGG‑16 network and extract activation maps from every one of its 21 layers (including convolutional, pooling, and fully‑connected layers). Each activation map is L2‑normalized, then reduced to a 256‑dimensional vector via principal component analysis (PCA) to keep the descriptor compact while preserving discriminative power. Two complementary filters are then applied:
-
Spatial Filter – A window‑based alignment procedure that compensates for intra‑image spatial offsets. By constructing a pairwise distance matrix between descriptors of two candidate images and applying a local alignment window, the filter refines raw Euclidean distances into spatially consistent scores.
-
Sequential Filter – Inspired by SeqSLAM, this stage exploits temporal continuity. A dynamic‑time‑warping‑like cost accumulation is performed over a sliding sequence of frames; only when a contiguous subsequence meets a predefined similarity threshold is a place match declared. The spatially‑aligned distances are used as the underlying cost metric, effectively coupling spatial consistency with temporal coherence.
The combination of these filters yields a robust matching score that is tolerant to moderate viewpoint shifts, illumination changes, and minor occlusions.
Experimental Evaluation
Two extensive datasets are used for validation:
-
Dataset 1 (70 km road‑driving benchmark) – Consists of ~12 000 forward‑looking images captured from a vehicle traversing a 70 km route. The proposed system is compared against state‑of‑the‑art methods such as SeqSLAM, FAB‑MAP, and NetVLAD. At 100 % precision, the recall improves by 75 % relative to the best prior technique. A layer‑wise analysis reveals that mid‑depth convolutional layers (specifically Conv4‑3) deliver the highest recall, outperforming both shallow layers (which are overly sensitive to low‑level noise) and deep fully‑connected layers (which become too abstract for fine‑grained place discrimination).
-
Dataset 2 (high viewpoint‑change indoor/outdoor sequences) – Features significant variations in camera pose, height, and orientation. The same CNN‑layer and filter configuration maintains superior performance, confirming that the approach generalizes beyond the relatively benign road‑driving scenario.
Performance and Complexity
Feature extraction on a modern GPU averages 30 ms per image; the spatial filter adds ~10 ms, and the sequential filter ~15 ms, resulting in an overall processing time well under 60 ms per frame (≈ > 15 FPS). After PCA, each descriptor occupies roughly 1 KB, making the method memory‑efficient for large‑scale deployments.
Insights from Layer‑wise Study
The authors provide a detailed discussion of why different layers behave as they do. Early layers encode edges and textures, offering robustness to small illumination changes but lacking global context. Deep fully‑connected layers capture class‑level semantics, which can be too invariant for distinguishing distinct but visually similar places. Mid‑level convolutional layers strike a balance, preserving enough spatial detail to differentiate locations while also encoding enough contextual information to be resilient to moderate viewpoint changes.
Limitations and Future Work
The framework depends on a CNN pre‑trained on generic image classification datasets (e.g., ImageNet). Consequently, its performance may degrade in highly specialized domains (e.g., underwater or aerial imagery) where the learned filters are less relevant. Moreover, extreme viewpoint shifts or dynamic objects can still cause mismatches. The authors suggest future directions such as domain‑adaptation fine‑tuning, designing lightweight mobile‑friendly CNN architectures, and employing advanced data‑augmentation strategies to improve viewpoint invariance.
Conclusion
By systematically integrating CNN‑derived descriptors with spatial alignment and sequential consistency, the paper demonstrates a substantial leap in place‑recognition accuracy—achieving a 75 % recall boost at perfect precision on a challenging 70 km benchmark. The extensive layer‑wise analysis, real‑time feasibility, and validation on a second, more demanding dataset collectively underscore the method’s robustness and applicability to autonomous navigation, robotics, and augmented‑reality systems that require reliable, on‑the‑fly place recognition.