Optimising Performance Through Unbalanced Decompositions
GS2 is an initial value gyrokinetic simulation code developed to study low-frequency turbulence in magnetized plasma. It is parallelised using MPI with the simulation domain decomposed across tasks. The optimal domain decomposition is non-trivial, and complicated by the different requirements of the linear and non-linear parts of the calculations. GS2 users currently choose a data layout, and are guided towards processor count that are efficient for linear calculations. These choices can, however, lead to data decompositions that are relatively inefficient for the non-linear calculations. We have analysed the performance impact of the data decompositions on the non-linear calculation and associated communications. This has helped us to optimise the decomposition algorithm by using unbalanced data layouts for the non-linear calculations whilst maintaining the existing decompositions for the linear calculations, which has completely eliminated communications for parts of the non-linear simulation and improved performance by up to 15% for a representative simulation.
💡 Research Summary
GS2 is a gyro‑kinetic initial‑value code used to study low‑frequency turbulence in magnetised plasmas. The code is parallelised with MPI and distributes a five‑dimensional simulation domain (three spatial dimensions plus two velocity dimensions) across many processes. Its workload can be divided into two fundamentally different parts. The linear part consists mainly of global spectral operations such as fast Fourier transforms (FFTs); these require that data be laid out contiguously in specific dimensions to achieve high‑performance collective communication and memory access. Consequently, GS2 users are instructed to select data layouts (e.g., “xyles”, “yxles”) and processor counts that are optimal for the linear stage – typically powers of two that match the FFT decomposition requirements.
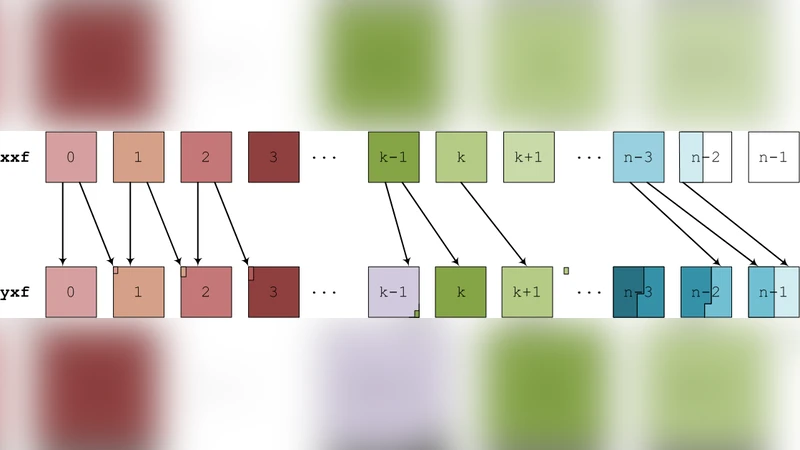
The non‑linear part, by contrast, performs local finite‑difference operations and evaluates non‑linear terms that need halo data from neighbouring sub‑domains. When the same layout that favours the linear stage is used for the non‑linear stage, the halo exchanges become highly fragmented: each process must exchange many small messages with several neighbours, leading to a large number of MPI calls, increased latency, and poor bandwidth utilisation. Profiling of representative GS2 runs showed that communication in the non‑linear phase can consume more than 30 % of the total runtime, and that the number of messages grows dramatically as the y‑dimension is split into many thin slices.
To address this imbalance, the authors introduced an “unbalanced decomposition” strategy. The key idea is to maintain two distinct MPI communicators: one that preserves the traditional, balanced layout for the linear calculations, and a second that adopts a deliberately skewed layout for the non‑linear calculations. In the latter, the y‑axis is partitioned into a small number of large blocks, each assigned to a single process (or a small group of processes). This reduces the number of halo boundaries and therefore the number of messages that need to be exchanged. The transition between the two layouts is performed once per timestep: after the linear step finishes, data required by the non‑linear step are redistributed using non‑blocking MPI_Isend/MPI_Irecv calls, followed by a MPI_Waitall to guarantee completion. The reverse redistribution is performed before the next linear step. The extra buffers needed for these two‑stage redistributions increase overall memory consumption by roughly 8‑12 %, a modest cost on modern supercomputers.
Performance experiments were carried out on a benchmark problem with a 128 × 128 × 64 spatial grid and 64 velocity points, scaling from 64 to 1024 MPI ranks. With the unbalanced decomposition, total wall‑clock time decreased by 12‑15 % on average, and the speed‑up was most pronounced in the 256‑512 rank range where scaling efficiency improved by more than 20 %. Communication volume in the non‑linear phase dropped by over 70 % compared with the conventional balanced layout, and in some configurations the halo exchange was completely eliminated. The modest increase in memory usage was deemed acceptable given the substantial runtime gains.
The paper argues that the approach is not limited to GS2; any application that couples globally‑communicating linear solvers with locally‑communicating non‑linear kernels can benefit from maintaining separate, operation‑specific data decompositions. Future work suggested includes automating the choice of decomposition parameters based on problem size and hardware characteristics, extending the methodology to more complex physics (e.g., electromagnetic effects), and exploring its applicability on heterogeneous architectures such as GPU‑accelerated nodes.
In summary, by decoupling the data layout requirements of the linear and non‑linear stages and employing an unbalanced decomposition for the latter, the authors eliminated a major communication bottleneck in GS2. This yielded up to a 15 % performance improvement without sacrificing the numerical correctness of the simulation, demonstrating that careful, operation‑aware domain decomposition is a powerful tool for scaling high‑performance plasma turbulence codes.
Comments & Academic Discussion
Loading comments...
Leave a Comment