Towards a Virtual Data Centre for Classics
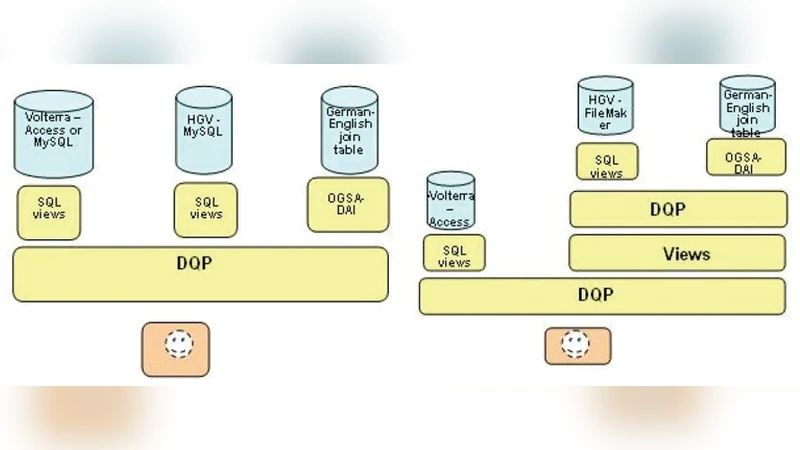
The paper presents some of our work on integrating datasets in Classics. We present the results of various projects we had in this domain. The conclusions from LaQuAT concerned limitations to the approach rather than solutions. The relational model followed by OGSA-DAI was more effective for resources that consist primarily of structured data (which we call data-centric) rather than for largely unstructured text (which we call text-centric), which makes up a significant component of the datasets we were using. This approach was, moreover, insufficiently flexible to deal with the semantic issues. The gMan project, on the other hand, addressed these problems by virtualizing data resources using full-text indexes, which can then be used to provide different views onto the collections and services that more closely match the sort of information organization and retrieval activities found in the humanities, in an environment that is more interactive, researcher-focused, and researcher-driven.
💡 Research Summary
The paper reports on a series of experiments aimed at building a “virtual data centre” for the discipline of Classics, where scholars routinely work with a heterogeneous mix of structured catalogues (prosopographies, chronologies, geographic gazetteers) and large volumes of unstructured textual material (primary source texts, commentaries, translations). The authors first describe the LaQuAT project, which adopted the Open Grid Services Architecture – Data Access and Integration (OGSA‑DAI) framework and a conventional relational database model. LaQuAT proved effective for what the authors term “data‑centric” resources: the relational schema could enforce integrity constraints, support complex joins, and deliver fast SQL/XQuery responses. However, when the same infrastructure was applied to “text‑centric” resources, several problems emerged. The rigid schema forced the authors to fragment or pre‑process the texts, leading to loss of contextual information and making it difficult to support full‑text search, linguistic annotation, or semantic linking. Moreover, the OGSA‑DAI pipeline lacked the flexibility to incorporate ontological reasoning or to expose the nuanced relationships that are central to humanities scholarship (e.g., concept co‑occurrence across centuries, inter‑author influence).
In contrast, the gMan project approached integration from a virtualization perspective. Instead of forcing all data into a relational model, gMan built a full‑text index (using Apache Lucene/Solr) for each collection while preserving the original documents unchanged. A lightweight metadata layer, expressed in Dublin Core plus project‑specific extensions, was attached to each indexed item. Researchers could issue keyword, phrase, or regular‑expression queries, and the system would return hits together with the surrounding textual context and the associated metadata (author, date, provenance). This design aligns closely with the exploratory, discovery‑driven workflow typical of classicists, who often need to trace the usage of a term across disparate corpora, compare stylistic patterns between authors, or map textual references onto geographic or chronological axes. Because the indexing service is decoupled from the underlying storage, adding new datasets simply requires re‑indexing and updating the metadata catalogue, giving the architecture a high degree of scalability and adaptability.
The comparative evaluation highlights complementary strengths. LaQuAT excels where strict data integrity, transactional guarantees, and complex relational queries are required—situations common for curated catalogues and reference datasets. gMan shines when the primary research activity is full‑text exploration, semantic retrieval, or the generation of ad‑hoc views that combine textual evidence with provenance information. The authors argue that a hybrid solution, integrating both a relational back‑end for structured assets and a full‑text indexing layer for unstructured corpora, would provide the most robust virtual data centre for Classics.
To realize such a hybrid environment, the paper proposes three technical pillars: (1) a unified metadata ontology, ideally built on CIDOC‑CRM and extended to capture domain‑specific concepts such as “epigraphic genre” or “literary motif”; (2) an automated ETL pipeline that can ingest both tabular data (into the relational store) and raw texts (into the indexing engine), applying linguistic preprocessing (tokenisation, lemmatisation, part‑of‑speech tagging) as needed; and (3) a researcher‑centric front‑end that offers visual dashboards, query builders, and export facilities, allowing scholars to compose complex queries without writing code. The authors also outline future work, including the construction of a knowledge graph to support semantic queries, the integration of machine‑learning models for topic modelling and author attribution, and the adoption of interoperable harvesting protocols (e.g., OAI‑PMH) to facilitate cross‑institutional data sharing.
In sum, the paper demonstrates that while a pure relational approach (as embodied by LaQuAT) is insufficient for the text‑heavy reality of classical studies, a full‑text virtualisation strategy (as embodied by gMan) can deliver the flexibility and researcher‑oriented services needed. By combining the two, a truly virtual data centre can be built—one that preserves the scholarly rigor of structured catalogues while empowering classicists to explore, link, and analyse the vast corpus of ancient texts in a manner that is both interactive and scalable.