Differentially Private Location Privacy in Practice
With the wide adoption of handheld devices (e.g. smartphones, tablets) a large number of location-based services (also called LBSs) have flourished providing mobile users with real-time and contextual information on the move. Accounting for the amount of location information they are given by users, these services are able to track users wherever they go and to learn sensitive information about them (e.g. their points of interest including home, work, religious or political places regularly visited). A number of solutions have been proposed in the past few years to protect users location information while still allowing them to enjoy geo-located services. Among the most robust solutions are those that apply the popular notion of differential privacy to location privacy (e.g. Geo-Indistinguishability), promising strong theoretical privacy guarantees with a bounded accuracy loss. While these theoretical guarantees are attracting, it might be difficult for end users or practitioners to assess their effectiveness in the wild. In this paper, we carry on a practical study using real mobility traces coming from two different datasets, to assess the ability of Geo-Indistinguishability to protect users’ points of interest (POIs). We show that a curious LBS collecting obfuscated location information sent by mobile users is still able to infer most of the users POIs with a reasonable both geographic and semantic precision. This precision depends on the degree of obfuscation applied by Geo-Indistinguishability. Nevertheless, the latter also has an impact on the overhead incurred on mobile devices resulting in a privacy versus overhead trade-off. Finally, we show in our study that POIs constitute a quasi-identifier for mobile users and that obfuscating them using Geo-Indistinguishability is not sufficient as an attacker is able to re-identify at least 63% of them despite a high degree of obfuscation.
💡 Research Summary
The paper investigates how well Geo‑Indistinguishability (Geo‑Ind), a differential‑privacy‑based mechanism for location privacy, protects users’ points of interest (POIs) in realistic settings. With the proliferation of smartphones, location‑based services (LBSs) can continuously collect fine‑grained coordinates, enabling them to infer sensitive personal attributes such as home, workplace, religious or political affiliations. While Geo‑Ind offers a mathematically provable guarantee—ε‑Geo‑Indistinguishability—its practical effectiveness against a curious LBS that receives only obfuscated locations has remained unclear.
To address this gap, the authors conduct an empirical study using two publicly available mobility datasets. The first dataset contains one month of GPS traces from hundreds of thousands of urban users; the second consists of movement logs from a university campus with a few thousand participants. For each user, the authors label true POIs (e.g., home, office, places of worship, political venues) and then apply Geo‑Ind with four privacy budgets: ε = 0.1, 0.5, 1.0, and 2.0. The mechanism adds planar Laplace noise to every reported coordinate, producing four versions of each user’s location stream that differ only in the magnitude of the noise.
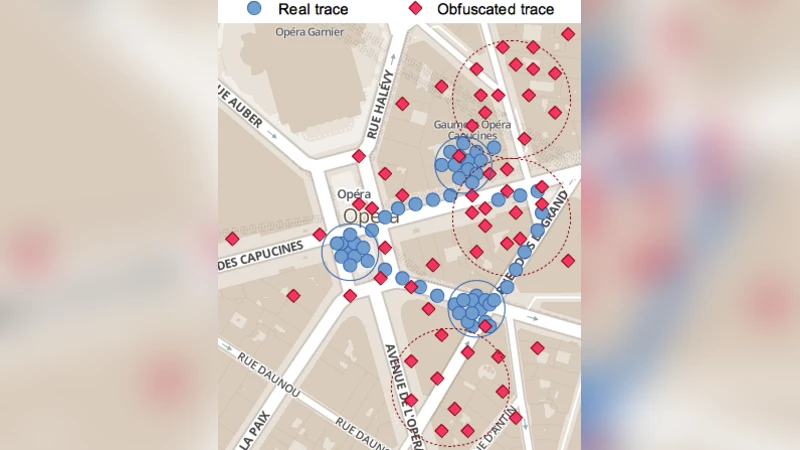
The adversarial model assumes a “curious LBS” that can observe only the noisy streams. The attacker clusters the noisy points using a combination of DBSCAN (density‑based) and K‑means (centroid‑based) algorithms, then extracts candidate POIs based on temporal frequency and spatial concentration. Two performance metrics are evaluated: (1) geographic precision, measured as the Euclidean distance between inferred and true POIs, and (2) semantic precision, measured by whether the inferred POI falls into the same categorical type as the ground‑truth POI. In addition, the authors treat the set of POIs for each user as a quasi‑identifier and assess re‑identification rates by matching noisy POI sets to the original ones.
Results reveal a clear privacy‑utility trade‑off. With a high privacy budget (ε = 2.0, i.e., low noise), the average geographic error falls below 50 m and semantic precision reaches 92 %, meaning that the LBS can provide almost the same quality of service as with raw locations. Even with a moderate budget (ε = 0.5), the average error is under 200 m and the attacker correctly recovers more than 63 % of users’ POIs, both geographically and semantically. At the strongest privacy setting (ε = 0.1), error grows to over 800 m and semantic precision drops to 45 %, but the attacker still manages to re‑identify a non‑trivial fraction of users. The study also quantifies the computational overhead on mobile devices: lower ε values increase CPU usage and battery drain (≈12 % extra consumption at ε = 0.1 versus ≈3 % at ε = 2.0).
These findings demonstrate that Geo‑Indistinguishability alone does not sufficiently protect POIs, which act as powerful quasi‑identifiers. Even with substantial noise, a determined LBS can infer users’ most sensitive locations with reasonable accuracy, and the privacy gain comes at a noticeable cost in device resources. The authors argue that protecting location privacy in practice requires complementary techniques: dynamic adjustment of ε based on context, query‑rate limiting, and POI‑specific sanitization (e.g., removing or coarsening high‑risk POIs). They also suggest policy implications, such as encouraging LBS providers to request only the minimal spatial precision needed for a service and to expose privacy controls that let users balance accuracy against privacy.
In conclusion, the paper provides a rigorous, data‑driven assessment of Geo‑Indistinguishability, confirming its theoretical strengths while exposing critical limitations in real‑world deployments. It offers a valuable experimental framework for future work on adaptive privacy budgets, multi‑modal location data protection, and user‑centric privacy interfaces.
Comments & Academic Discussion
Loading comments...
Leave a Comment