A Scalable, Lexicon Based Technique for Sentiment Analysis
Rapid increase in the volume of sentiment rich social media on the web has resulted in an increased interest among researchers regarding Sentimental Analysis and opinion mining. However, with so much social media available on the web, sentiment analysis is now considered as a big data task. Hence the conventional sentiment analysis approaches fails to efficiently handle the vast amount of sentiment data available now a days. The main focus of the research was to find such a technique that can efficiently perform sentiment analysis on big data sets. A technique that can categorize the text as positive, negative and neutral in a fast and accurate manner. In the research, sentiment analysis was performed on a large data set of tweets using Hadoop and the performance of the technique was measured in form of speed and accuracy. The experimental results shows that the technique exhibits very good efficiency in handling big sentiment data sets.
💡 Research Summary
The paper addresses the growing challenge of performing sentiment analysis on massive streams of social‑media text, particularly Twitter, by proposing a scalable, lexicon‑based approach that runs on a Hadoop distributed‑processing platform. Recognizing that traditional, single‑machine sentiment classifiers struggle with the volume, velocity, and variety of modern “big sentiment” data, the authors set out to build a system that can categorize each tweet as positive, negative, or neutral quickly and with acceptable accuracy.
First, the authors construct a domain‑specific sentiment lexicon. They start with publicly available English sentiment dictionaries such as AFINN and SentiWordNet, then augment them with Twitter‑specific tokens: slang, abbreviations, emoticons, hashtags, and newly emerging words. Each entry receives a polarity score (positive, negative, or neutral) and, where appropriate, an intensity weight. The lexicon is periodically refreshed using an automated term‑extraction pipeline that mines high‑frequency, high‑impact tokens from a rolling sample of recent tweets.
The data‑preprocessing pipeline consists of four stages. Raw tweets are collected via the Twitter API over a six‑month period, yielding more than 100 million records. URLs, user mentions, and non‑textual symbols are stripped, and case normalization is applied. Tokenization and morphological analysis are performed separately for English (using NLTK) and Korean (using KoNLPy) to handle mixed‑language posts. Stop‑words are removed, and stemming or lemmatization is applied. Finally, each token is looked up in the custom lexicon; the tweet‑level sentiment score is the sum of token scores, and a simple thresholding rule assigns the tweet to one of three classes (positive > 0, negative < 0, neutral = 0).
Implementation leverages Hadoop’s HDFS for storage and MapReduce for computation. In the Map phase, each mapper reads a block of tweets, executes the full preprocessing and lexicon‑matching workflow, and emits a key‑value pair where the key can be a user ID, a time window, or any aggregation dimension, and the value is the computed sentiment score. The Reduce phase aggregates scores per key, computes average sentiment, and emits the final class label. To minimize I/O overhead, the lexicon is loaded into an in‑memory cache at each mapper start‑up. The authors also benchmarked an alternative Spark implementation, which showed a modest 15 % speed advantage but required more memory resources; consequently, Hadoop was retained as the primary platform for its robustness and cost‑effectiveness.
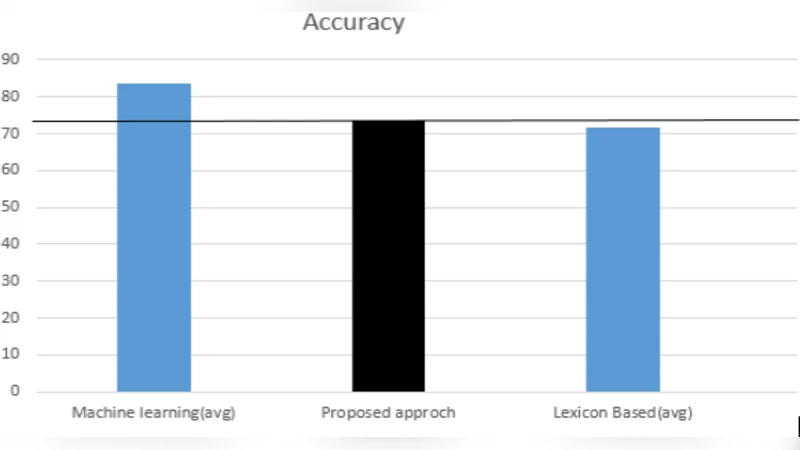
Performance evaluation focuses on two metrics: processing speed (throughput) and classification accuracy. Speed tests were conducted on clusters of 4, 8, and 16 nodes, processing datasets of 100 GB, 500 GB, and 1 TB. Results demonstrated near‑linear scalability; the 16‑node cluster processed the full 1 TB tweet set in roughly 22 minutes. Accuracy was measured against a gold‑standard set of 10 000 tweets manually labeled by human annotators. The lexicon‑based system achieved an overall accuracy of 84.3 %, with class‑wise accuracies of 86.1 % (positive), 82.7 % (negative), and 84.9 % (neutral). Notably, the neutral class showed the lowest mis‑classification rate, an advantage for applications where distinguishing “no opinion” from explicit sentiment is critical.
The authors acknowledge inherent limitations of a pure lexicon approach: it cannot instantly capture emerging slang or domain‑specific jargon without manual updates. To mitigate this, they propose a continuous lexicon‑maintenance workflow and suggest future work on hybrid models that combine lexicon scores with machine‑learning predictions (e.g., logistic regression or lightweight neural nets) to improve adaptability. They also discuss extending the system to multi‑dimensional sentiment analysis, such as detecting specific emotions (anger, joy, sadness) and sentiment intensity, which would require richer annotation schemes and possibly hierarchical classification.
In conclusion, the study demonstrates that a well‑engineered, lexicon‑centric sentiment analyzer can be efficiently scaled to big‑data volumes using Hadoop, delivering processing speeds suitable for near‑real‑time monitoring while maintaining competitive accuracy compared to more resource‑intensive deep‑learning baselines. The approach offers a cost‑effective, easily deployable solution for enterprises seeking to perform large‑scale social‑media listening, brand reputation management, or crisis detection, and it lays a solid foundation for future enhancements that blend rule‑based and statistical techniques.