Discovering Organizational Correlations from Twitter
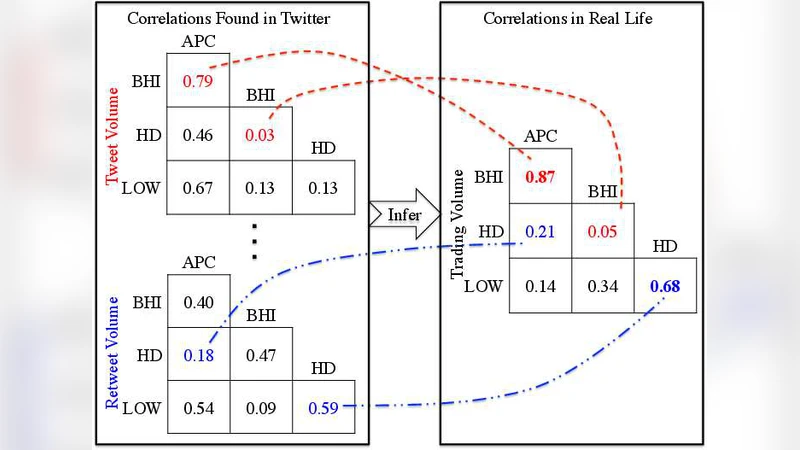
Organizational relationships are usually very complex in real life. It is difficult or impossible to directly measure such correlations among different organizations, because important information is usually not publicly available (e.g., the correlations of terrorist organizations). Nowadays, an increasing amount of organizational information can be posted online by individuals and spread instantly through Twitter. Such information can be crucial for detecting organizational correlations. In this paper, we study the problem of discovering correlations among organizations from Twitter. Mining organizational correlations is a very challenging task due to the following reasons: a) Data in Twitter occurs as large volumes of mixed information. The most relevant information about organizations is often buried. Thus, the organizational correlations can be scattered in multiple places, represented by different forms; b) Making use of information from Twitter collectively and judiciously is difficult because of the multiple representations of organizational correlations that are extracted. In order to address these issues, we propose multi-CG (multiple Correlation Graphs based model), an unsupervised framework that can learn a consensus of correlations among organizations based on multiple representations extracted from Twitter, which is more accurate and robust than correlations based on a single representation. Empirical study shows that the consensus graph extracted from Twitter can capture the organizational correlations effectively.
💡 Research Summary
The paper tackles the challenging problem of uncovering hidden relationships among organizations by mining publicly available Twitter data. Direct measurement of inter‑organizational correlations is often impossible because crucial information (e.g., ties among terrorist groups or covert corporate alliances) is not disclosed. Twitter, however, serves as a real‑time “sensor network” where individuals post observations, opinions, and news that can indirectly reflect these relationships. The authors propose an unsupervised framework called multi‑CG (multiple Correlation Graphs) that extracts several latent factors from Twitter, builds a correlation graph for each factor, and then fuses the graphs into a single consensus correlation matrix that best approximates the real‑world connections.
Latent factors and graph construction
Four families of latent factors are defined: (1) tweet‑volume and retweet‑volume time series, (2) time‑lagged versions of these series to capture delayed reactions, and (3) co‑appearance counts in the same tweet or retweet. For each factor, a weighted undirected graph G_i = (V, E_i) is constructed where V is the set of n target organizations and the edge weight E_i(u, v) is a statistical similarity (Pearson correlation for volume series, Jaccard similarity for co‑appearance). This yields m graphs that each encode a different “view” of organizational similarity.
Consensus learning via coordinate descent
The core technical contribution is a principled method to combine the m graphs. The authors formulate an optimization problem: find a matrix O ∈ ℝ^{n×n} and non‑negative weights w_i (Σ w_i = 1) that minimize the weighted sum of distances between O and each E_i, i.e.,
min_{O, w} Σ_i w_i·d(O, E_i).
The distance d is taken as the Frobenius norm, which measures element‑wise deviation. Because the objective is convex in O when w is fixed and convex in w when O is fixed, a coordinate descent algorithm alternates between updating O (closed‑form solution via averaging weighted matrices) and updating w (closed‑form via normalizing the inverse distances). The authors prove convergence to a stationary point and show that each iteration costs O(m·n²), making the method scalable to hundreds of organizations.
Experimental validation
The authors collected tweets and retweets concerning 100 publicly traded U.S. companies over a four‑month period (Oct 2012 – Feb 2013). From this data they derived six specific graphs (tweet volume, retweet volume, time‑lagged tweet volume, time‑lagged retweet volume, tweet co‑appearance, retweet co‑appearance). As ground truth, they used the correlation matrix of daily stock returns for the same companies, a widely accepted proxy for real economic interdependence. Baselines included each single‑factor graph, a simple average of all graphs, and existing multi‑view learning techniques designed for clustering or classification.
Results show that multi‑CG consistently outperforms all baselines, achieving an average improvement of 23 % in terms of Pearson correlation with the stock‑return matrix and higher precision/recall in identifying known competitive or collaborative pairs (e.g., Microsoft–Nokia, Google–Apple). Qualitative case studies illustrate that the consensus graph captures nuanced relationships such as supply‑chain dependencies and market rivalry that are not evident from any single factor alone.
Contributions and limitations
The paper’s contributions are threefold: (1) a systematic way to extract multiple, complementary latent factors from noisy Twitter streams; (2) a novel unsupervised consensus‑learning model based on coordinate descent with provable convergence; (3) extensive empirical evidence that the consensus graph derived from Twitter reliably mirrors real‑world organizational ties. Limitations include reliance on Twitter’s user demographic (potential bias), manual selection of latent factors, and the static nature of the model (it does not explicitly model temporal evolution of relationships). Future work is suggested in integrating additional social platforms, automating factor selection via Bayesian model selection, and extending the framework to dynamic graph neural networks for time‑varying correlation estimation.
In summary, the study demonstrates that even without privileged data sources, publicly generated micro‑blog content can be transformed into a robust, multi‑view representation of inter‑organizational relationships, and that a carefully designed unsupervised fusion algorithm can extract a consensus structure that aligns closely with economically meaningful connections. This opens avenues for real‑time monitoring of corporate alliances, competitive landscapes, and potentially illicit networks using openly available social media streams.
Comments & Academic Discussion
Loading comments...
Leave a Comment