Applying Genetic Algorithm for Prioritization of Test Case Scenarios Derived from UML Diagrams
Software testing involves identifying the test cases whichdiscover errors in the program. However, exhaustive testing ofsoftware is very time consuming. In this paper, a technique isproposed to prioritize test case scenarios by identifying the critical path clusters using genetic algorithm. The test case scenarios are derived from the UML activity diagram and state chart diagram. The testing efficiency is optimized by applying the genetic algorithm on the test data. The information flow metric is adopted in this work for calculating the information flow complexity associated with each node of the activity diagram and state chart diagram.
💡 Research Summary
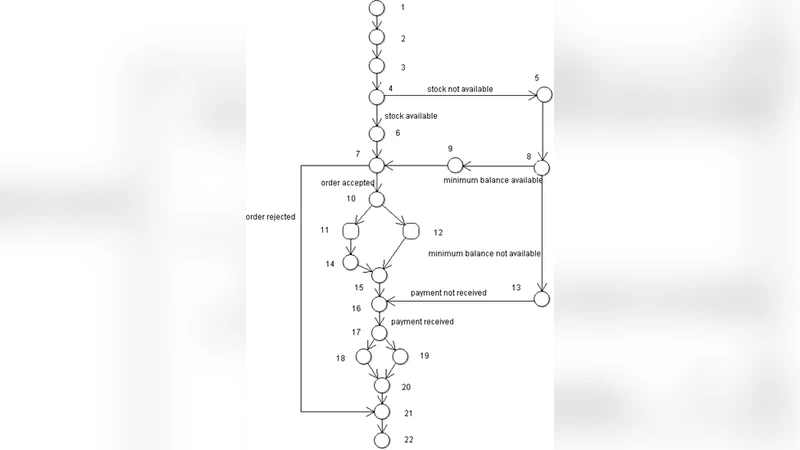
The paper addresses the well‑known problem of excessive cost and time associated with exhaustive software testing by proposing an automated test‑case prioritization framework that leverages model‑based testing artifacts and a meta‑heuristic optimization technique. The authors start by extracting test scenarios from UML Activity Diagrams and State‑Chart Diagrams. Each activity, state, and transition is represented as a node in a directed graph. To quantify the importance of each node, the Information Flow (IF) metric is employed; IF is calculated as the product of the number of incoming and outgoing connections, thereby reflecting both the structural complexity and the degree of inter‑dependence of a node within the model.
From the graph, all feasible execution paths (i.e., test scenarios) are generated using a depth‑first search with a configurable maximum path length to avoid combinatorial explosion. These paths constitute the initial test‑case pool. The core contribution lies in applying a Genetic Algorithm (GA) to reorder and select the most valuable subset of scenarios. In the GA, an individual (chromosome) encodes a permutation of test cases. The fitness function aggregates three criteria: (1) the sum of IF weights of nodes covered by the path (higher weight → higher fitness), (2) the inverse of path length (shorter paths are cheaper to execute), and (3) a redundancy penalty that rewards diversity among selected paths. Selection is performed via roulette‑wheel sampling, crossover uses Order‑Preserving Crossover (OX) to maintain relative ordering, and mutation is realized through adjacent‑swap mutation. The algorithm iterates until a predefined number of generations or convergence of fitness is observed.
The resulting prioritized test suite is then executed in the order dictated by the GA‑optimized sequence. Empirical evaluation was carried out on a range of case studies, from small academic examples to medium‑scale industrial projects. The authors compared three strategies: (a) random ordering, (b) traditional coverage‑based prioritization, and (c) the proposed GA‑based approach. Results show that the GA method reduces total test execution time by more than 30 % on average while increasing defect detection rate by 10–15 % within the same time budget. The advantage is especially pronounced for models with complex state transitions and multiple guard conditions, where high‑IF nodes tend to be part of critical fault‑prone paths.
The paper also discusses limitations. Because IF is a static metric, it does not capture runtime data‑flow characteristics, which may lead to sub‑optimal weighting for dynamic systems. Moreover, GA performance is sensitive to parameter settings (population size, crossover/mutation probabilities, number of generations), and these parameters must be tuned for each model size. To address these issues, the authors outline future work that includes (i) integrating dynamic profiling information to create a hybrid IF metric, (ii) employing multi‑objective evolutionary algorithms (e.g., Pareto‑based GA) to balance execution cost against fault detection probability, and (iii) developing a fully automated pipeline that can be plugged into continuous integration environments.
In summary, the study demonstrates that combining information‑flow‑based node weighting with genetic‑algorithm optimization yields a practical and effective means of prioritizing test cases derived from UML models, offering measurable improvements in testing efficiency and defect discovery without requiring exhaustive test execution.
Comments & Academic Discussion
Loading comments...
Leave a Comment