A Review of CUDA, MapReduce, and Pthreads Parallel Computing Models
The advent of high performance computing (HPC) and graphics processing units (GPU), present an enormous computation resource for Large data transactions (big data) that require parallel processing for robust and prompt data analysis. While a number of HPC frameworks have been proposed, parallel programming models present a number of challenges, for instance, how to fully utilize features in the different programming models to implement and manage parallelism via multi-threading in both CPUs and GPUs. In this paper, we take an overview of three parallel programming models, CUDA, MapReduce, and Pthreads. The goal is to explore literature on the subject and provide a high level view of the features presented in the programming models to assist high performance users with a concise understanding of parallel programming concepts and thus faster implementation of big data projects using high performance computing.
💡 Research Summary
The paper provides a comparative review of three widely used parallel programming models—CUDA, MapReduce, and POSIX Threads (Pthreads)—with the aim of helping high‑performance computing (HPC) practitioners select the most appropriate model for big‑data and scientific‑computing projects. After a brief introduction that frames the growing need for heterogeneous computing resources (CPU + GPU) in modern data‑intensive workloads, the authors devote separate sections to each model, describing its architectural foundations, programming abstractions, memory management strategies, and typical application domains.
In the CUDA section, the authors explain the GPU’s SIMT (single‑instruction‑multiple‑thread) execution model, the hierarchy of threads, warps, blocks, and grids, and the four‑level memory hierarchy (global, shared, constant, texture). They discuss performance‑critical issues such as memory‑transfer overhead between host and device, occupancy, warp divergence, and the use of high‑level libraries (cuBLAS, cuFFT, Thrust). The analysis emphasizes that CUDA excels at compute‑bound kernels (e.g., dense linear algebra, image processing) but incurs development costs related to device‑specific code, debugging, and data movement.
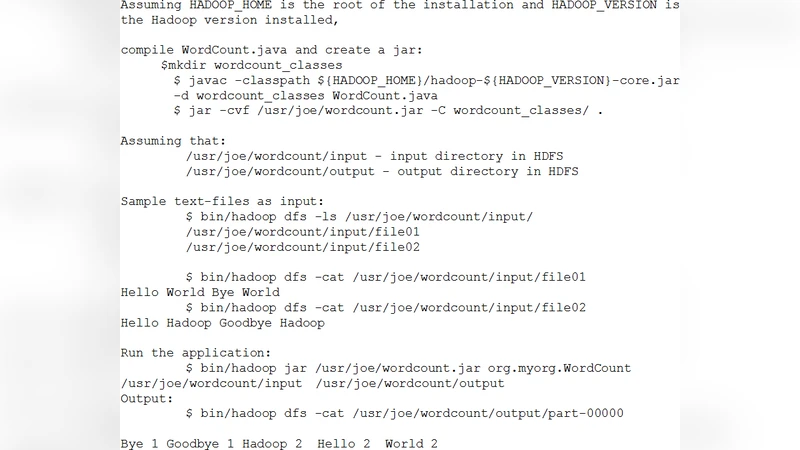
The MapReduce portion focuses on the batch‑oriented, key‑value processing paradigm pioneered by Google and realized in the open‑source Hadoop ecosystem. The authors outline the Map, Shuffle, and Reduce phases, the role of HDFS for data locality, YARN for resource scheduling, and auxiliary tools such as Hive and Pig. They note MapReduce’s strengths in fault tolerance, linear scalability across commodity clusters, and suitability for log analysis, indexing, and ETL pipelines, while also pointing out its limitations for iterative algorithms, low‑latency streaming, and fine‑grained synchronization.
The Pthreads section reviews the POSIX thread library, detailing thread creation, synchronization primitives (mutexes, condition variables, barriers), and the importance of memory consistency models on multicore CPUs. The paper highlights Pthreads’ flexibility for low‑level, latency‑sensitive applications and its steep learning curve due to potential race conditions, deadlocks, and the need for careful profiling (gprof, perf).
A comparative matrix then evaluates the three models across dimensions such as programming difficulty, execution environment (single node, cluster, GPU), scalability, memory‑management complexity, debugging support, and typical use cases. The authors conclude that CUDA is optimal for GPU‑accelerated, compute‑intensive kernels; MapReduce shines in large‑scale batch processing with built‑in fault tolerance; and Pthreads is best for fine‑grained, real‑time parallelism on CPUs.
Importantly, the paper advocates hybrid approaches: using Pthreads for preprocessing on the CPU, off‑loading heavy kernels to CUDA, and embedding CUDA tasks within a MapReduce workflow (e.g., via Hadoop Streaming or Spark’s GPU support). Such combinations can exploit the strengths of each model while mitigating their weaknesses, leading to higher overall throughput in complex pipelines.
The final sections discuss limitations of the current study—primarily reliance on literature review and a limited set of benchmark experiments—and outline future work, including extensive cross‑platform performance evaluations, integration with emerging standards like SYCL/OneAPI, and exploration of serverless or cloud‑native parallel models. Overall, the paper serves as a concise yet thorough guide for engineers and researchers seeking to navigate the landscape of parallel programming models in the era of big data and heterogeneous HPC systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment