A Fast Minimal Infrequent Itemset Mining Algorithm
A novel fast algorithm for finding quasi identifiers in large datasets is presented. Performance measurements on a broad range of datasets demonstrate substantial reductions in run-time relative to the state of the art and the scalability of the algorithm to realistically-sized datasets up to several million records.
💡 Research Summary
The paper introduces a novel algorithm, named K yiv, for mining minimal infrequent (or rare) itemsets in large categorical datasets. Minimal infrequent itemsets are those whose support does not exceed a user‑specified threshold τ and for which every proper subset has support greater than τ. Such itemsets are crucial for identifying quasi‑identifiers in statistical disclosure control, rare pattern discovery, and intrusion detection. The authors first formalize the problem, defining items as triples (value, column, row‑set) and distinguishing uniform items (present in every row) from τ‑infrequent items. In a preprocessing step, uniform items are removed and τ‑infrequent singletons are identified, dramatically shrinking the search space. The remaining items are partitioned into two groups: L A,τ, containing items with unique row‑sets, and ¯L A,τ, containing duplicates that share a row‑set with some item in L A,τ. Proposition 4.1 proves that replacing an item in a minimal τ‑infrequent set with its duplicate preserves minimality, allowing the algorithm to treat each equivalence class of duplicate items as a single representative.
K yiv employs a breadth‑first search (BFS) over itemset size, rather than the depth‑first strategies used by SUDA2 and MINIT. At each BFS level the algorithm computes the support set R I for candidate itemsets using highly optimized data structures: hash tables for quick row‑set lookup and bit‑vector intersections for set‑wise support calculation. Lemma 4.6 and Corollary 4.7 provide theoretical guarantees that the support test for minimality can be performed essentially at zero computational cost, because only the |I| − 1 immediate subsets (the support itemsets) need to be examined.
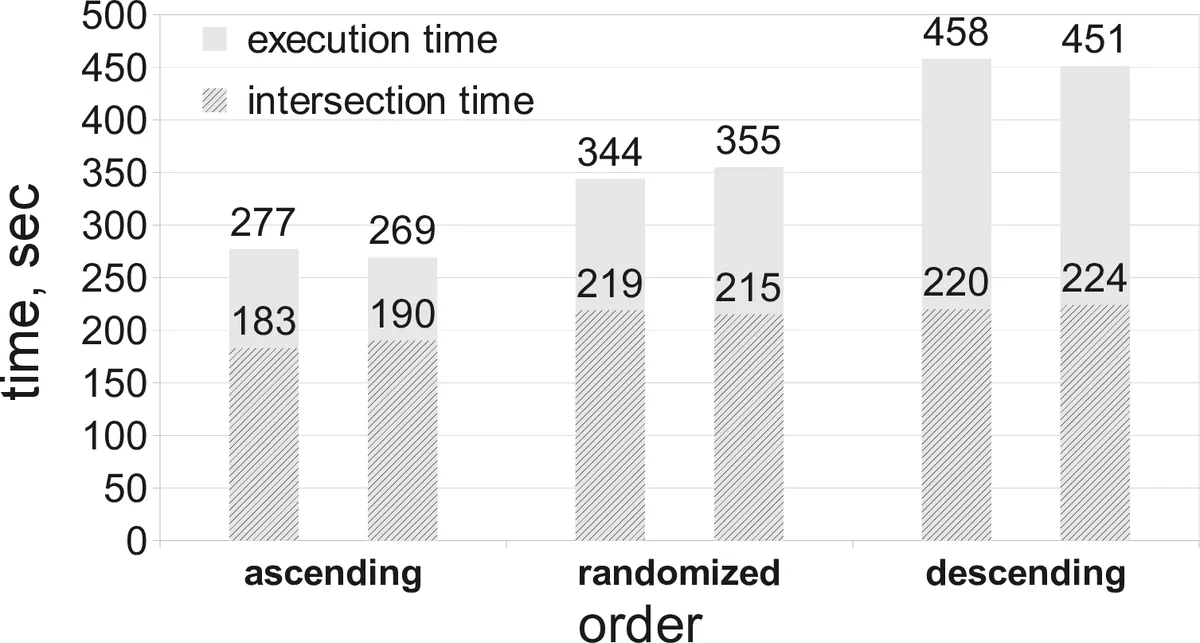
A major contribution is the parallel implementation. Candidate itemsets at a given BFS level are evenly partitioned among threads, and dynamic load‑balancing ensures that no single thread becomes a bottleneck—a problem that plagued earlier parallel depth‑first approaches such as SUDA2. The authors report near‑linear speed‑up up to the number of cores available on modern multi‑core machines.
Experimental evaluation covers synthetic datasets of varying density, the AOL web‑search log (over 3.5 million queries), and medical datasets. K yiv is compared against three state‑of‑the‑art algorithms: MINIT, SUDA2, and MIWI Miner. Results show speed‑ups ranging from an order of magnitude to nearly two orders of magnitude, while maintaining correctness. The algorithm scales to datasets with several million records, a size at which the competing methods either fail to finish or require prohibitive runtime. The trade‑off is higher memory consumption (approximately 2–5× that of the baselines), which the authors argue is acceptable given the continual growth of main‑memory capacities.
In summary, K yiv advances the field of infrequent itemset mining by delivering a dramatically faster, well‑balanced parallel algorithm with solid theoretical underpinnings. Its ability to efficiently enumerate minimal quasi‑identifiers makes it a valuable tool for privacy‑preserving data publishing, rare pattern discovery, and related domains where the identification of low‑support item combinations is essential.
Comments & Academic Discussion
Loading comments...
Leave a Comment