Network histograms and universality of blockmodel approximation
In this article we introduce the network histogram: a statistical summary of network interactions, to be used as a tool for exploratory data analysis. A network histogram is obtained by fitting a stochastic blockmodel to a single observation of a net…
Authors: Sofia C. Olhede, Patrick J. Wolfe
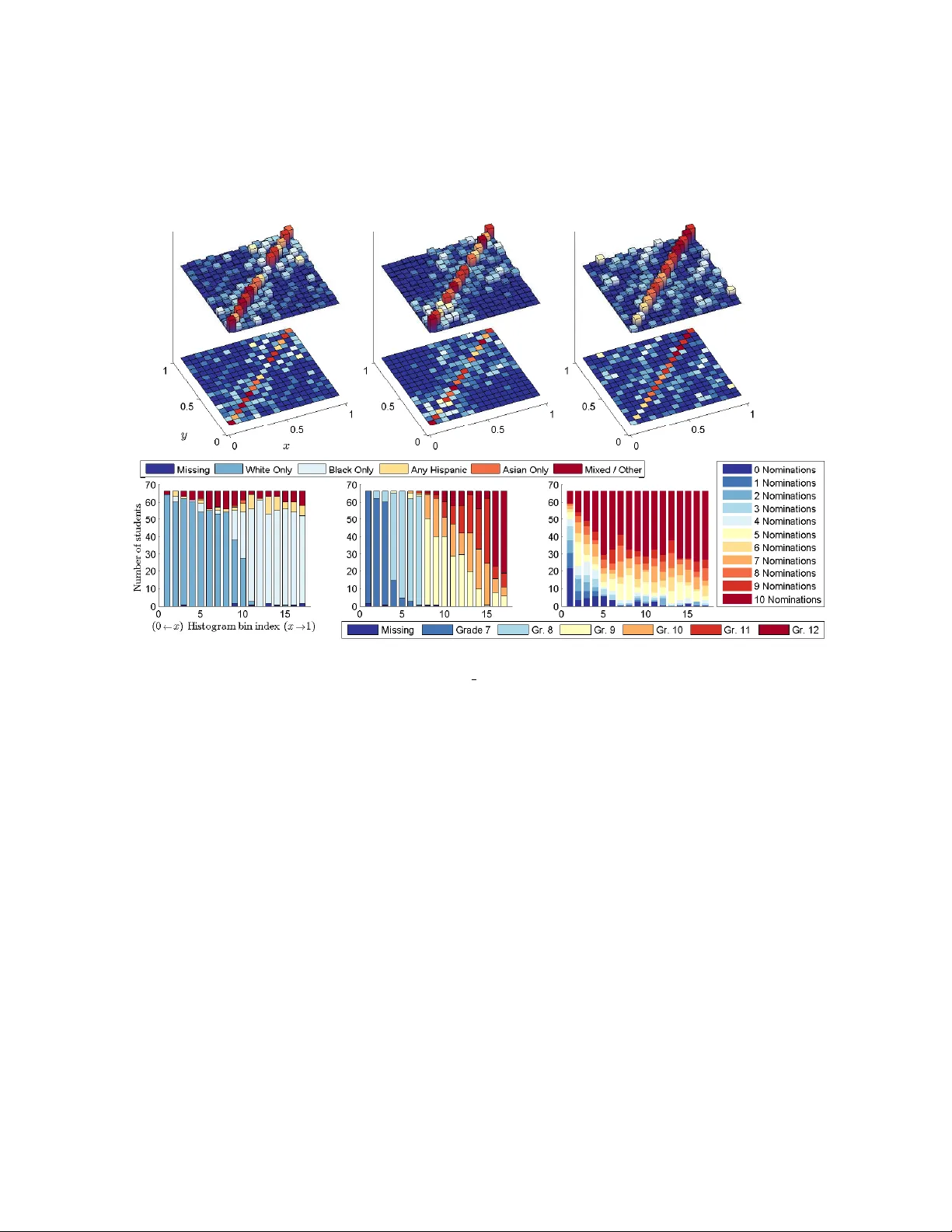
Net w ork histograms and univ ersalit y of blo c kmo del appro ximation Sofia C. Olhede and P atrick J. W olfe July 27, 2018 Abstract In this article w e introduce the netw ork histogram: a statistical sum- mary of net work interactions, to b e used as a to ol for exploratory data analysis. A netw ork histogram is obtained by fitting a sto chastic blo c k- mo del to a single observ ation of a net work dataset. Blo c ks of edges pla y the role of histogram bins, and communit y sizes that of histogram band- widths or bin sizes. Just as standard histograms allo w for v arying band- widths, different blo c kmo del estimates can all b e considered v alid rep- resen tations of an underlying probability mo del, sub ject to bandwidth constrain ts. Here we provide methods for automatic bandwidth selection, b y which the netw ork histogram approximates the generating mechanism that gives rise to exchangeable random graphs. This makes the blo c k- mo del a universal net work represen tation for unlab eled graphs. With this insigh t, we discuss the in terpretation of netw ork communities in ligh t of the fact that many differen t comm unity assignmen ts can all give an equally v alid representation of suc h a netw ork. T o demonstrate the fidelity- v ersus-interpretabilit y tradeoff inherent in considering differen t num b ers and sizes of communities, we analyze tw o publicly av ailable netw orks— p olitical weblogs and student friendships—and discuss ho w to interpret the net work histogram when additional information related to node and edge lab eling is present. Key w ords: Communit y detection, exchangeable random graphs, graphons, nonparametric statistics, statistical netw ork analysis, stochastic block- mo dels The purp ose of this article is to introduce the netw ork histogram—a non- parametric statistical summary obtained b y fitting a stochastic blo c kmo del to a single observ ation of a netw o rk dataset. A key p oin t of our construction is that it is not necessary to assume the data to ha ve b een generated b y a blo c kmo del. This is crucial, since net works provide a general means of describing relation- ships b et ween ob jects. Giv en n ob jects under study , a total of n 2 pairwise relationships are p ossible. When only a small fraction of these relationships are presen t—as is often the case in mo dern high-dimensional data analysis across scien tific fields—a netw ork representation simplifies our understanding of this dep endency structure. 1 One fundamen tal characterization of a netw ork comes through the iden tifi- cation of comm unity structure [1], corresponding to groups of no des that exhibit similar connectivit y patterns. The canonical statistical mo del in this setting is the sto c hastic blo c kmo del [2]: it p osits that the probability of an edge b et w een an y tw o netw ork no des depends only on the communit y groupings to which those no des b elong. Grouping no des together in this wa y serves as a natural form of dimensionality reduction: as n grows large, we cannot retain an arbi- trarily complex view of all p ossible pairwise relationships. Describing how the full set of n ob jects in terrelate is then reduced to understanding the interactions of k n communities. Studying the prop erties of fitted blo ckmodels is thus imp ortan t [3, 4]. Despite the p opularit y of the blockmodel, and its clear utility , scientists hav e observ ed that it often fails to describ e all the structure presen t in a net work [5, 6, 7, 8]. Indeed, as a netw ork b ecomes larger, it is no longer reasonable to assume that a ma jorit y of its structure can b e explained by a blo c kmo del with a fixed n umber of blo c ks. Extensions to the blo c kmo del hav e focused on capturing additional v ariabilit y , for example through mixed comm unity membership [5] and degree correction [6, 9]. Ho wev er, the simplest and most natural metho d of extending the descriptiveness of the blo c kmo del is to add blo cks, so that k gro ws with n . As more and more blo c ks are fitted, we exp ect an increasing degree of structure in the data to b e explained. The natural questions to ask then are many: What happ ens as we fit more blo c ks to an arbitrary netw ork dataset, if the true data-generating mec hanism is not a blo c kmo del? A t what rate should w e increase the n umber of blo c ks used, dep ending on the v ariability of the net work? W e discuss these and other questions in this article. W e will stipulate how the dimension k of the fitted blo c kmo del should b e allo wed to increase with the size n of the netw ork. This increase will b e dic- tated by a tradeoff b et ween the sparsit y of the netw ork and its heterogeneity or smo othness. If one assumes that a k -comm unity blo c kmo del is the actual data- generating mechanism, then theory has already b een developed which allows k to gro w with n [10, 11, 12], and metho ds hav e b een suggested for c ho osing the num ber of blo c ks based on the data [13, 14]. General theory for the case when the blo c kmo del is merely appr oximating the observed net work structure is nascen t, with [15] treating the case of dense bipartite graphs with a fixed n umber of blo c ks, and [16] establishing the first suc h results for the setting of relev ance here. 1 F rom sto c hastic net w orks to histograms 1.1 A simple sto c hastic netw ork mo del W e enco de the relationships b et ween n ob jects using n 2 binary random v ari- ables. Eac h of these v ariables indicates the presence or absence of an edge b et w een tw o no des, and can b e collected into an n × n adjacency matrix A , suc h that A ij = 1 if nodes i and j are connected, and A ij = 0 otherwise, with 2 A ii = 0. This yields what is kno wn as a simple random graph. Mo dels for unlab eled graphs are strongly related to the statistical notion of exchangeabilit y , a fundamental concept describing random v ariables w hose ordering is without information. T o relate to exchangeable v ariables, we app eal to the Aldous–Ho o ver theorem [3], and model our net work hierarc hically using three comp onen ts: 1. A fixed, symmetric function f ( x, y ) termed a graphon [18], which behav es lik e a probability densit y function for 0 < x, y < 1; 2. F or each n , a random sample ξ of n uniform random v ariables { ξ 1 , . . . , ξ n } whic h will serve to index the graphon f ( x, y ); and 3. F or each n , a deterministic scaling constant ρ n > 0, sp ecifying the ex- p ected fraction of edges n 2 − 1 E P i
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment