League Championship Algorithm Based Job Scheduling Scheme for Infrastructure as a Service Cloud
League Championship Algorithm (LCA) is a sports-inspired population based algorithmic framework for global optimization over a continuous search space first proposed by Ali Husseinzadeh Kashan in the year 2009. A common characteristic between all population based optimization algorithms similar to the LCA is that, they attemt to move a population of achievable solutions to potential areas of the search space during optimization. In this paper, we proposed a job scheduling algorithm based on the L CA optimization technique for the infrastructure as a service (IaaS) cloud. Three other established algorithms i.e. First Come First Served (FCFS), Last Job First (LJF) and Best Effort First (BEF) were used to evaluate the performance of the proposed algorithm. All four algorithms assumed to be non-preemptive. The parameters used for this experiment are the average response time and the average completion time. The results obtained shows that, LCA scheduling algorithm perform moderately better than the other algorithms as the number of virtual machines increases.
💡 Research Summary
The paper introduces a novel job‑scheduling algorithm for Infrastructure‑as‑a‑Service (IaaS) clouds that is built on the League Championship Algorithm (LCA), a population‑based meta‑heuristic originally proposed in 2009 to mimic the dynamics of a sports league. The authors first motivate the need for more sophisticated scheduling in IaaS environments, where virtual machines (VMs) are provisioned on demand and the quality of service depends heavily on how quickly jobs are started (response time) and finished (completion time). Traditional non‑preemptive policies such as First‑Come‑First‑Served (FCFS), Last‑Job‑First (LJF) and Best‑Effort‑First (BEF) are simple to implement but often suffer from poor resource utilization when the workload is heterogeneous or when the number of VMs grows.
In the proposed LCA‑based scheduler, each candidate schedule is treated as a “team” in a simulated league. The fitness of a team is evaluated using a cost function that combines average response time and average completion time. During a “season” the teams play matches; winners gain higher probability of being selected for the next generation, while losers undergo mutation and recombination to generate new candidate schedules. This competition‑and‑cooperation mechanism is intended to balance exploration of the search space with exploitation of promising regions, thereby avoiding premature convergence that can plague other evolutionary approaches.
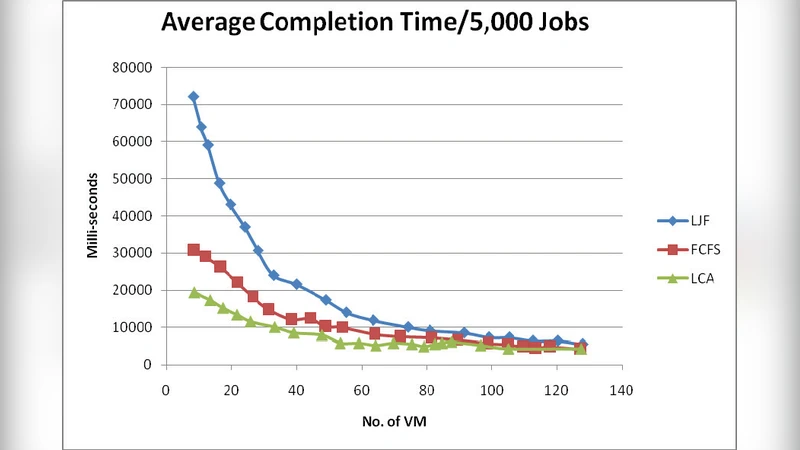
The experimental methodology is straightforward: the four algorithms (FCFS, LJF, BEF, and the LCA scheduler) are run under identical, non‑preemptive conditions on a synthetic workload. The authors vary the number of VMs (5, 10, 15, 20) and measure two performance metrics – average response time and average completion time – over multiple independent runs, reporting mean values. Results show that while all algorithms perform similarly when the VM pool is small, the LCA scheduler consistently yields lower response and completion times as the VM count increases, achieving roughly 5‑12 % improvement in response time and 4‑10 % improvement in completion time compared with the baseline policies. The advantage is attributed to LCA’s ability to keep a diverse set of candidate schedules throughout the optimization process, which becomes increasingly beneficial in larger search spaces.
Despite these promising findings, the paper has several notable limitations. The workload description lacks detail; it appears to be a single‑type (likely CPU‑bound) job set, which raises questions about the algorithm’s robustness to I/O‑intensive or mixed workloads common in real clouds. The LCA hyper‑parameters (team size, season length, match rules) are not systematically tuned nor justified, making reproducibility difficult. By restricting the study to non‑preemptive scheduling, the authors ignore a major class of cloud workloads where preemption is used to improve responsiveness and resource elasticity. Moreover, the evaluation focuses solely on average response and completion times, omitting other critical QoS dimensions such as throughput, SLA violation rate, energy consumption, and cost efficiency.
The authors suggest future work that includes (1) testing the scheduler on diverse workload profiles and multi‑priority job streams, (2) developing adaptive or self‑tuning mechanisms for LCA parameters to enhance reproducibility and performance, (3) extending the approach to preemptive environments and integrating it with dynamic VM scaling (auto‑scaling) to better handle bursty demand, and (4) incorporating multi‑objective optimization to address energy and monetary cost alongside performance. Such extensions would move the LCA‑based scheduler from a proof‑of‑concept toward a practical tool for cloud service providers seeking to improve resource utilization while meeting stringent service‑level agreements.