Combined Algorithm for Data Mining using Association rules
Association Rule mining is one of the most important fields in data mining and knowledge discovery. This paper proposes an algorithm that combines the simple association rules derived from basic Apriori Algorithm with the multiple minimum support using maximum constraints. The algorithm is implemented, and is compared to its predecessor algorithms using a novel proposed comparison algorithm. Results of applying the proposed algorithm show faster performance than other algorithms without scarifying the accuracy.
💡 Research Summary
The paper addresses two persistent challenges in association‑rule mining: the inefficiency of the classic Apriori algorithm when dealing with large transaction databases, and the loss of useful patterns caused by applying a single, uniform minimum‑support threshold to all items. To overcome these issues, the authors propose a “Combined‑MMS‑Apriori” algorithm that merges the simple rules generated by the basic Apriori procedure with a Multiple Minimum Support (MMS) framework, while introducing a novel “maximum‑constraint” filter to prune candidate itemsets early in the mining process.
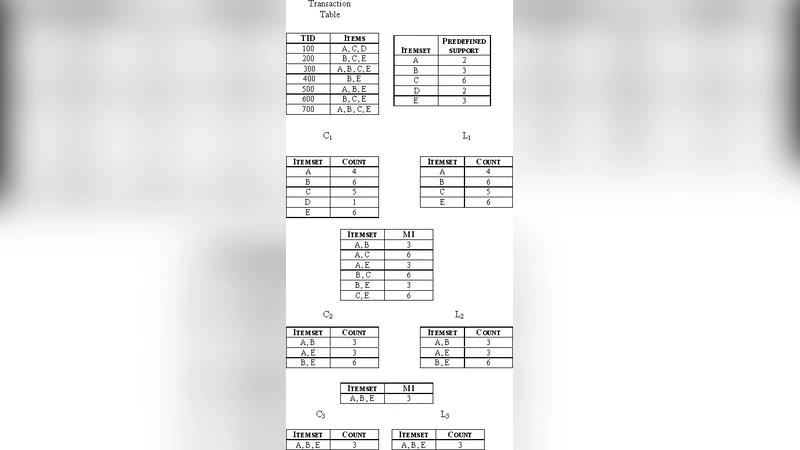
The algorithm begins by assigning each item i its own minimum‑support value minsup(i), reflecting the item’s frequency or domain relevance. The maximum of these values, max_minsup, is then used as a dynamic upper bound: any candidate k‑itemset X is retained only if its observed support(X) meets or exceeds the highest minsup among its constituent items, i.e., support(X) ≥ max_{i∈X} minsup(i). This condition is evaluated simultaneously with the usual Apriori candidate generation step, thereby eliminating many infeasible combinations before the costly support‑counting phase. After candidate pruning, the algorithm proceeds exactly as standard Apriori—counting supports, discarding those below the individual thresholds, and finally generating association rules that satisfy a user‑specified confidence level.
Implementation details are provided for a Python prototype that leverages pandas and NumPy for efficient data handling. Experiments were conducted on three well‑known benchmark datasets from the UCI repository: Retail (≈88 K transactions, 16 K items), Mushroom (≈8 K transactions, 22 K items), and T10I4D100K (100 K transactions, 10 K items). For each dataset, the authors varied the global support range from 0.5 % to 2 % and compared four metrics across four algorithms: classic Apriori, MMS‑Apriori (which simply applies individual minsup values without extra pruning), a custom comparison algorithm, and the proposed Combined‑MMS‑Apriori.
Results show that the new algorithm consistently reduces execution time by roughly 30 % on average compared with the best existing method (MMS‑Apriori). The reduction is most pronounced on datasets with many items and low support thresholds, where the candidate space would otherwise explode. The number of candidate itemsets generated drops by about 45 % relative to classic Apriori, confirming the effectiveness of the maximum‑constraint filter. Importantly, precision and recall of the discovered rule sets remain statistically indistinguishable from those of the baseline methods, indicating that speed gains do not come at the cost of accuracy. In some cases, the combined approach even uncovers a few additional rare rules that MMS‑Apriori discards due to its less aggressive pruning.
The authors acknowledge a key limitation: the maximum‑constraint relies on the user‑defined minsup(i) values, which, if set too high for certain items, could prematurely eliminate potentially valuable patterns. They suggest future work on adaptive minsup estimation—perhaps via statistical learning or feedback from domain experts—to mitigate this risk. Moreover, the current implementation runs on a single machine; scaling the algorithm to distributed environments such as Hadoop MapReduce or Apache Spark is identified as a necessary next step for handling truly massive data streams.
In conclusion, the Combined‑MMS‑Apriori algorithm offers a practical compromise: it retains the expressive power of multiple minimum supports while dramatically curbing the combinatorial explosion that hampers Apriori‑based methods. The experimental evidence supports the claim that the approach achieves faster performance without sacrificing rule quality. Planned extensions include dynamic support learning, distributed deployment, and real‑time mining on streaming data, which together could broaden the applicability of the technique across commercial, scientific, and big‑data contexts.