Optimal Demand Response Using Device Based Reinforcement Learning
Demand response (DR) for residential and small commercial buildings is estimated to account for as much as 65% of the total energy savings potential of DR, and previous work shows that a fully automated Energy Management System (EMS) is a necessary prerequisite to DR in these areas. In this paper, we propose a novel EMS formulation for DR problems in these sectors. Specifically, we formulate a fully automated EMS’s rescheduling problem as a reinforcement learning (RL) problem, and argue that this RL problem can be approximately solved by decomposing it over device clusters. Compared with existing formulations, our new formulation (1) does not require explicitly modeling the user’s dissatisfaction on job rescheduling, (2) enables the EMS to self-initiate jobs, (3) allows the user to initiate more flexible requests and (4) has a computational complexity linear in the number of devices. We also demonstrate the simulation results of applying Q-learning, one of the most popular and classical RL algorithms, to a representative example.
💡 Research Summary
The paper addresses demand response (DR) in residential and small commercial buildings, where DR potential accounts for up to 65 % of the total savings achievable by DR programs. Existing approaches typically require a fully automated energy management system (EMS) that relies on explicitly defined user‑dissatisfaction (disutility) functions and on user‑initiated requests only. The authors argue that these requirements are impractical: disutility functions are highly idiosyncratic and costly to obtain, many appliances operate without direct user commands, and the computational burden of existing formulations grows exponentially with the number of devices.
To overcome these limitations, the authors propose a novel EMS formulation that casts the rescheduling problem as a reinforcement‑learning (RL) task and decomposes it across device clusters. The key ideas are:
-
Learning User Dissatisfaction from Feedback – Instead of assuming a known disutility curve, the EMS collects occasional user evaluations of completed or cancelled jobs. These evaluations are used to infer a per‑device dissatisfaction function, eliminating the need for a priori modeling.
-
EMS‑Initiated Jobs – The system is allowed to start jobs autonomously (e.g., pre‑cooling a building when a low‑price window is forecast), expanding control beyond user‑initiated requests.
-
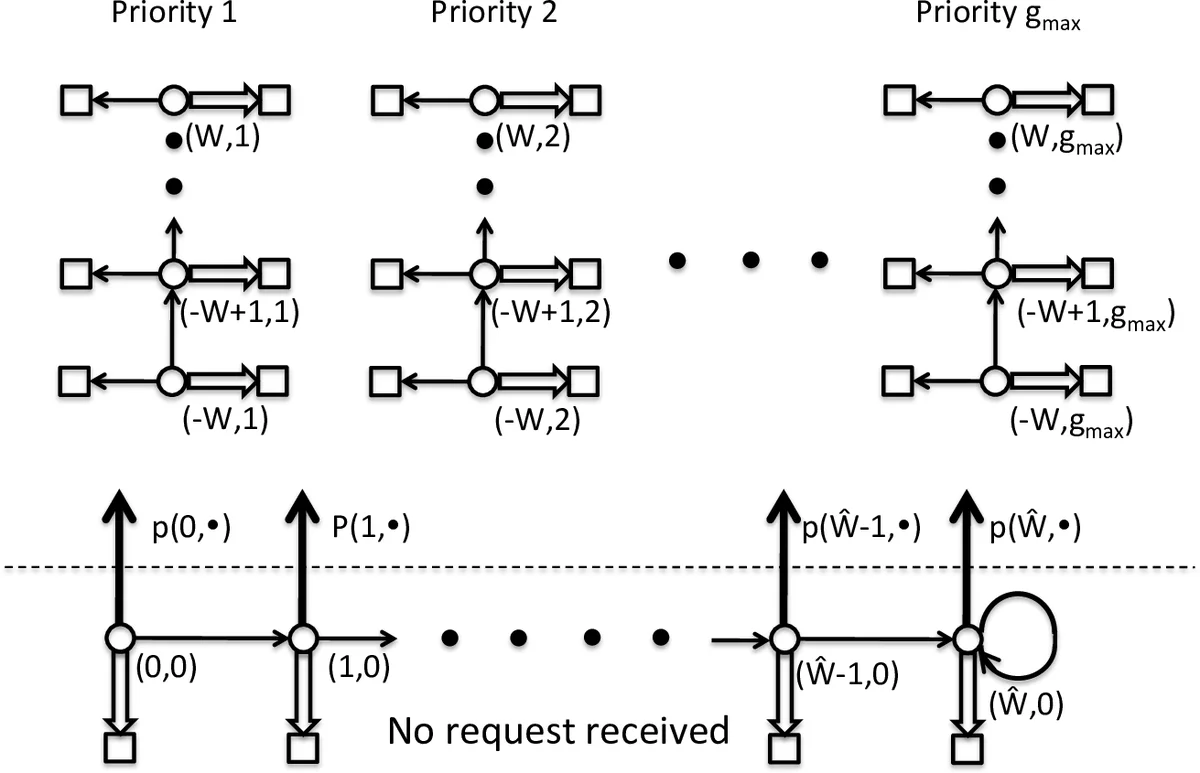
Additive Dissatisfaction Assumption – The total dissatisfaction at any time is approximated as the sum of device‑specific terms, (\bar U(t) \approx \sum_{n=1}^{N}\bar U(t,n)). This assumption, motivated by “decision fatigue,” enables the global optimization problem to be split into N independent Markov Decision Processes (MDPs), each associated with a device cluster. Consequently, the computational complexity scales linearly with the number of devices.
-
RL Formulation – The instantaneous cost combines electricity price, device energy consumption, and the weighted dissatisfaction term:
( \text{Cost}t = P_t \sum{n\in D(t)} C_n + \gamma \bar U(t) ).
States include the current time step, price forecasts, and the history of requests, cancellations, and device actions. Actions consist of executing, delaying, or cancelling a job.
The authors implement the simplest RL algorithm—Q‑learning—on a simulated environment containing multiple devices, each with a known energy consumption (C_n) and a request time window (W_n). Users submit requests characterized by device ID, request time, target time, and priority, and may later evaluate the outcome. The Q‑learning agents are trained independently for each device cluster. Simulation results show that the learned policies reduce electricity costs while keeping user dissatisfaction low, and that the policies converge after a reasonable number of episodes.
Contributions
- Elimination of explicit disutility modeling by leveraging user feedback.
- Introduction of EMS‑initiated, speculative jobs, increasing flexibility.
- Linear‑time scalability through device‑wise decomposition.
- New performance metrics comparing RL policies to both current user behavior and a prescient optimal benchmark.
Limitations and Future Work
- The additive dissatisfaction assumption may break down when devices interact (e.g., shared power‑capacity constraints).
- Q‑learning’s tabular approach does not scale to high‑dimensional state spaces; more advanced methods such as Deep Q‑Networks or policy‑gradient algorithms are needed.
- The paper provides only simulation evidence; real‑world pilot studies are required to validate the approach.
- Practical mechanisms for collecting user evaluations (frequency, interface design) are not detailed.
- Extensions to multi‑agent coordination, integration with price‑forecasting models, and handling of stochastic grid signals are suggested.
Overall, the work presents a promising direction for scalable, user‑centric demand response in low‑voltage buildings, demonstrating that device‑based reinforcement learning can reconcile cost savings with user comfort without demanding exhaustive prior modeling of user preferences.
Comments & Academic Discussion
Loading comments...
Leave a Comment