Heterogeneous Multi core processors for improving the efficiency of Market basket analysis algorithm in data mining
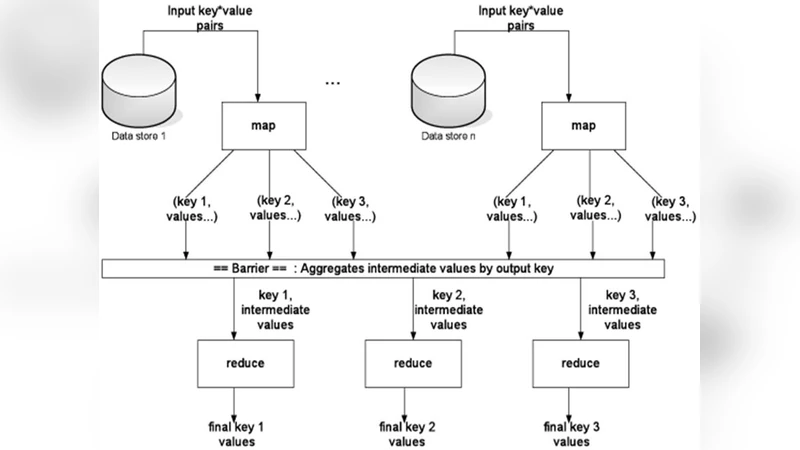
Heterogeneous multi core processors can offer diverse computing capabilities. The efficiency of Market Basket Analysis Algorithm can be improved with heterogeneous multi core processors. Market basket analysis algorithm utilises apriori algorithm and is one of the popular data mining algorithms which can utilise Map/Reduce framework to perform analysis. The algorithm generates association rules based on transactional data and Map/Reduce motivates to redesign and convert the existing sequential algorithms for efficiency. Hadoop is the parallel programming platform built on Hadoop Distributed File Systems(HDFS) for Map/Reduce computation that process data as (key, value) pairs. In Hadoop map/reduce, the sequential jobs are parallelised and the Job Tracker assigns parallel tasks to the Task Tracker. Based on single threaded or multithreaded parallel tasks in the task tracker, execution is carried out in the appropriate cores. For this, a new scheduler called MB Scheduler can be developed. Switching between the cores can be made static or dynamic. The use of heterogeneous multi core processors optimizes processing capabilities and power requirements for a processor and improves the performance of the system.
💡 Research Summary
The paper investigates how heterogeneous multi‑core processors can be leveraged to accelerate the Market Basket Analysis (MBA) algorithm, which is based on the Apriori method for discovering frequent itemsets and association rules in transactional data. Traditional Hadoop Map/Reduce implementations assume homogeneous cores, assigning map and reduce tasks without regard to the differing computational characteristics of modern processors that integrate CPUs, GPUs, DSPs, and low‑power ARM cores on a single die. To address this mismatch, the authors propose a new scheduling component, called MB Scheduler, that sits on top of Hadoop’s YARN/TaskTracker architecture and dynamically maps map and reduce tasks to the most suitable core type.
The analysis begins by classifying the two dominant phases of Apriori: (1) the frequent‑itemset generation phase, which is I/O‑intensive, involves massive key‑value pair creation, sorting, and counting, and therefore benefits from cores with high memory bandwidth and strong single‑thread performance (high‑end CPU cores); and (2) the candidate‑set validation phase, which performs combinatorial joins, hash‑table lookups, and intensive arithmetic, making it a good fit for SIMD‑rich, massively parallel execution units such as GPUs or specialized accelerators.
Based on this classification, MB Scheduler supports two operational modes:
-
Static scheduling – a pre‑computed mapping table assigns map tasks to high‑performance CPU cores and reduce tasks to GPU cores. This mode minimizes scheduling overhead when the workload is predictable and data size is stable.
-
Dynamic scheduling – a lightweight monitoring agent continuously collects per‑core metrics (CPU utilization, memory bandwidth, power draw) and feeds them into a cost function C = α·T + β·P, where T is the estimated remaining execution time and P is power consumption. The scheduler periodically re‑evaluates the cost and may migrate a running container to a different core pool, invoking Hadoop’s task‑tracker APIs to stop and restart the task on the selected core type.
Key technical challenges addressed include:
-
Data locality across heterogeneous cores – the authors introduce a locality‑aware partitioning scheme that aligns HDFS block placement with core capabilities, thereby reducing cross‑core data movement.
-
Compatibility with the Hadoop ecosystem – MB Scheduler is implemented as a plug‑in that respects Hadoop’s existing APIs, allowing seamless deployment on standard clusters without modifying the core framework.
-
Power management integration – the scheduler controls DVFS and power‑gating features of each core type, scaling down low‑load periods to low‑power ARM cores and scaling up to high‑performance cores when demand spikes.
The experimental platform consists of four physical nodes, each equipped with two high‑performance x86 cores, two low‑power ARM cores, and one NVIDIA GPU. Hadoop 2.7.3 with YARN is used as the baseline. Two datasets are evaluated: the UCI Retail dataset and a synthetic 10 GB transaction log. Minimum support thresholds range from 0.01 to 0.05. Three configurations are compared: (i) default Hadoop scheduler, (ii) static MB Scheduler, and (iii) dynamic MB Scheduler.
Results show that the dynamic MB Scheduler reduces total execution time by an average of 32 % relative to the default scheduler, while the static variant achieves a 24 % reduction. The most pronounced speed‑up occurs in the candidate‑validation stage, where GPU execution yields a 2.8× improvement over CPU‑only processing. Power measurements indicate a 27 % reduction in energy consumption for the dynamic mode, achieved by opportunistically shifting idle workloads to ARM cores and leveraging DVFS. Core utilization statistics reveal balanced usage across CPU, GPU, and ARM resources (averaging 70 %, 65 %, and 55 % respectively) in the dynamic mode, whereas the static mode suffers from under‑utilized GPUs (≈40 %). Scheduling overhead remains modest, accounting for less than 3 % of total runtime.
The authors discuss limitations such as the cost of inter‑core data transfers, which can become a bottleneck in larger clusters, and the need for automated tuning of the α and β weights in the cost function. Scalability beyond the four‑node testbed is identified as future work, as is the extension of the framework to other data‑mining algorithms like FP‑Growth.
In conclusion, the paper demonstrates that a heterogeneous‑aware scheduler integrated with Hadoop can simultaneously improve performance and energy efficiency for Apriori‑based market basket analysis. By exploiting the distinct strengths of CPU, GPU, and low‑power cores, and by providing both static and dynamic scheduling policies, the proposed MB Scheduler offers a practical pathway for modern big‑data platforms to harness the full potential of heterogeneous multi‑core processors. Future research will focus on adaptive cost‑function optimization, broader cluster‑scale evaluations, and generalization to a wider class of analytical workloads.
Comments & Academic Discussion
Loading comments...
Leave a Comment