A Method for Stopping Active Learning Based on Stabilizing Predictions and the Need for User-Adjustable Stopping
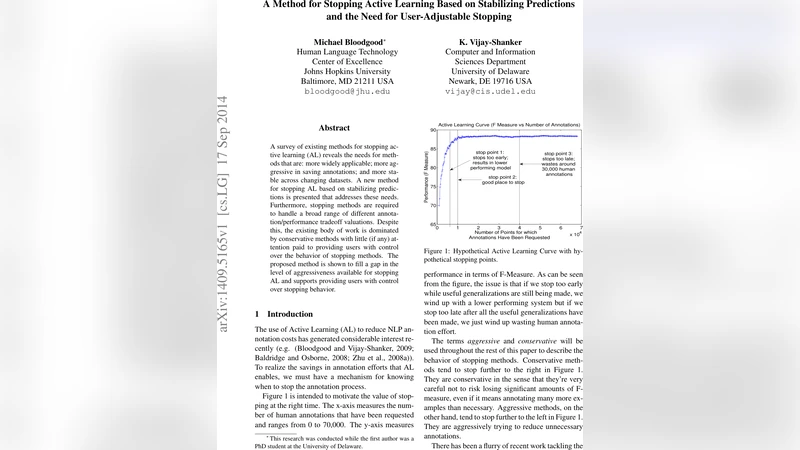
A survey of existing methods for stopping active learning (AL) reveals the needs for methods that are: more widely applicable; more aggressive in saving annotations; and more stable across changing datasets. A new method for stopping AL based on stabilizing predictions is presented that addresses these needs. Furthermore, stopping methods are required to handle a broad range of different annotation/performance tradeoff valuations. Despite this, the existing body of work is dominated by conservative methods with little (if any) attention paid to providing users with control over the behavior of stopping methods. The proposed method is shown to fill a gap in the level of aggressiveness available for stopping AL and supports providing users with control over stopping behavior.
💡 Research Summary
The paper addresses a fundamental problem in active learning (AL) for natural‑language processing: determining the optimal point at which to stop requesting human annotations. While AL can dramatically reduce labeling costs, an ill‑timed stop either wastes annotation effort (if stopped too late) or harms model performance (if stopped too early). Existing stopping criteria suffer from three major drawbacks: (1) limited applicability – many methods only work with specific learners (e.g., SVMs) or require particular batch‑size settings; (2) conservatism – they tend to stop far to the right on learning curves, thus saving few annotations; and (3) instability – performance varies wildly across datasets, sometimes stopping far too early or far too late.
To overcome these issues, the authors propose a novel “Stabilizing Predictions” (SP) stopping criterion. The central hypothesis is that when a model’s predictions on a set of unlabeled examples (the “stop set”) have stabilized, the model’s performance on the true task has also converged. SP therefore monitors successive models during AL and measures the agreement of their predictions on the stop set. Rather than using raw percent agreement, which is sensitive to chance agreement, the authors adopt Cohen’s Kappa statistic, which corrects for expected agreement by chance. In preliminary development experiments a Kappa threshold of 0.99 proved robust across datasets, and the authors use this value as the default without any per‑dataset tuning.
A second innovation is the notion of “longevity”: instead of requiring a single pair of consecutive models to exceed the Kappa threshold, SP averages the Kappa values over a sliding window of the k most recent model pairs (k=3 in the default configuration). This guards against transient spikes in agreement that could otherwise trigger premature stopping. Both the Kappa intensity cutoff and the window size are exposed to the user, providing explicit control over how aggressive or conservative the stopping behavior should be. Raising the Kappa cutoff or increasing the window size makes the method more conservative; lowering them makes it more aggressive.
The experimental evaluation covers a broad spectrum of tasks and datasets: binary spam detection (SpamAssassin, TREC‑spam), multi‑label Reuters‑21578, 20 Newsgroups, WebKB, and the GENIA biomedical NER corpus. All experiments use linear SVMs as the base learner (with a maximum‑entropy variant in a small sub‑section) and the standard “closest‑to‑hyperplane” query strategy. Batch sizes are 20 for small corpora and 200 for larger ones, with initial seed sets of 100 or 1 000 instances. The authors compare SP against several representative prior methods: LS2008 (gradient of performance estimates), SC2000 (margin exhaustion), V2008 (confidence drop), and ZWH2008 (multi‑criteria stopping).
Results (summarized in Table 1) show that SP consistently requires the fewest annotation queries while maintaining F‑measure scores that are comparable to, or even higher than, those achieved by the other methods. In many cases the other methods either waste large numbers of annotations (e.g., LS2008 on spam datasets) or suffer catastrophic early stops that dramatically reduce performance (e.g., V2008 on the NER‑Protein task). Moreover, SP exhibits remarkable stability: it never catastrophically fails on any of the tested datasets, whereas each competing method fails on at least one dataset. Sensitivity analyses demonstrate that a stop‑set size of 2 000 examples provides a good trade‑off between computational overhead and representativeness; larger stop sets yield diminishing returns, while smaller ones increase variance.
The paper concludes that the SP criterion fills a gap in the spectrum of AL stopping strategies by offering (a) broad applicability (it works with any learner that can produce predictions, not just margin‑based models), (b) aggressive annotation savings without sacrificing performance, (c) robust stability across diverse domains, and (d) user‑adjustable parameters that let practitioners tailor the aggressiveness to their specific cost‑performance trade‑offs. The authors argue that such flexibility is essential for real‑world deployment of active learning pipelines, where annotation budgets and quality requirements vary widely. Future work is suggested on adaptive stop‑set construction, dynamic tuning of Kappa thresholds, and integration with cost‑sensitive learning frameworks.
Comments & Academic Discussion
Loading comments...
Leave a Comment