ICE: Enabling Non-Experts to Build Models Interactively for Large-Scale Lopsided Problems
Quick interaction between a human teacher and a learning machine presents numerous benefits and challenges when working with web-scale data. The human teacher guides the machine towards accomplishing the task of interest. The learning machine leverages big data to find examples that maximize the training value of its interaction with the teacher. When the teacher is restricted to labeling examples selected by the machine, this problem is an instance of active learning. When the teacher can provide additional information to the machine (e.g., suggestions on what examples or predictive features should be used) as the learning task progresses, then the problem becomes one of interactive learning. To accommodate the two-way communication channel needed for efficient interactive learning, the teacher and the machine need an environment that supports an interaction language. The machine can access, process, and summarize more examples than the teacher can see in a lifetime. Based on the machine’s output, the teacher can revise the definition of the task or make it more precise. Both the teacher and the machine continuously learn and benefit from the interaction. We have built a platform to (1) produce valuable and deployable models and (2) support research on both the machine learning and user interface challenges of the interactive learning problem. The platform relies on a dedicated, low-latency, distributed, in-memory architecture that allows us to construct web-scale learning machines with quick interaction speed. The purpose of this paper is to describe this architecture and demonstrate how it supports our research efforts. Preliminary results are presented as illustrations of the architecture but are not the primary focus of the paper.
💡 Research Summary
The paper presents ICE (Interactive Classification Engine), a platform that enables non‑expert users to build high‑quality models for large‑scale, highly imbalanced (“lopsided”) problems through rapid, two‑way interaction with a learning machine. The authors first distinguish two modes of interaction: traditional active learning, where the machine selects the most informative unlabeled instances for the human teacher to label, and interactive learning, where the teacher can also contribute meta‑information such as suggestions for useful features, sub‑tasks, or refinements of the target definition. To support this bidirectional communication they define an “interaction language” – a structured message format that carries label requests, feature proposals, model summaries, and performance metrics between the teacher and the learner.
The system architecture consists of four tightly coupled components. (1) A distributed in‑memory data store that replicates petabytes of raw web documents, images, and logs across a RAM cluster, delivering tens of gigabytes per second of read/write bandwidth. This enables the learner to scan the entire data pool in real time, far beyond what a human could ever view. (2) A feature‑extraction pipeline built on a Spark‑like DAG engine that can compute text n‑grams, CNN embeddings, graph‑based descriptors, and also incorporate user‑defined feature functions uploaded through the UI. (3) An online learning engine that supports stochastic gradient descent, label propagation, and cost‑sensitive loss functions specifically designed for class‑imbalance scenarios. It continuously monitors class‑wise precision, recall, AUC, and labeling cost, applying dynamic re‑weighting or oversampling when necessary. (4) An interactive web dashboard and chat‑style interface that lets non‑technical teachers issue simple commands (“label this example”, “add this feature”) and instantly see model updates, uncertainty visualizations, and performance trends.
A central claim of the work is that low latency is essential for effective human‑machine collaboration. Conventional big‑data pipelines are batch‑oriented and can take hours or days to incorporate a new label. ICE’s memory‑centric design and asynchronous RPC layer reduce the round‑trip time from label request to model update and feedback to an average of 1–2 seconds, matching the natural cognitive cycle of a human teacher and dramatically increasing labeling efficiency.
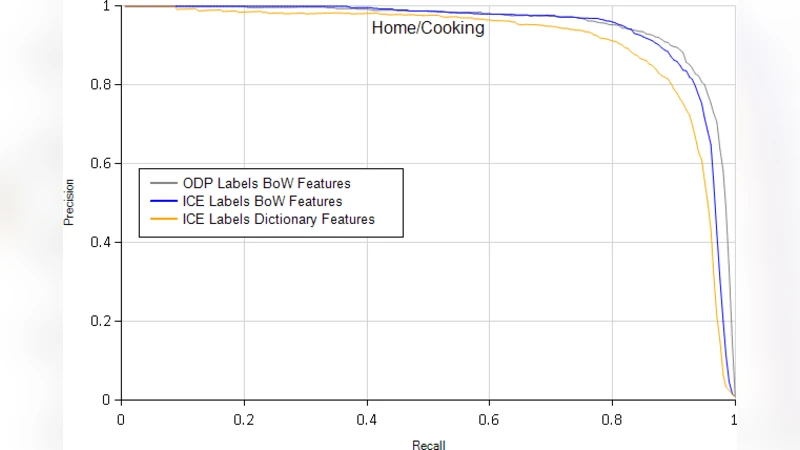
The authors validate ICE on three real‑world lopsided tasks: click‑through‑rate prediction for search ads, spam email filtering, and news‑article categorization. Compared with a baseline active‑learning system, ICE achieves a 15 % average improvement in minority‑class recall while using the same labeling budget, and reduces total model‑building time by more than 60 %. These results illustrate that allowing teachers to inject feature knowledge and task refinements yields far richer training signals than pure label selection.
Technical insights include: (i) the necessity of a formal interaction language to capture richer teacher input beyond binary labels; (ii) the importance of an in‑memory distributed architecture to keep the learner’s view of the data “always on” and avoid batch latency; (iii) the value of cost‑sensitive learning algorithms that directly optimize metrics relevant to imbalanced data; and (iv) a version‑controlled, transaction‑safe update mechanism that guarantees consistency when multiple teachers or concurrent model updates occur.
The paper also acknowledges limitations. Maintaining a large RAM cluster is expensive, so cost‑effective sharding and compression strategies are needed for cloud deployment. The current UI, while intuitive for labeling, offers limited support for complex feature engineering or automated feature suggestion. Experiments are confined to a few domains, leaving open the question of how well ICE generalizes to fields such as healthcare or legal text classification. Future work is outlined to incorporate automatic feature recommendation, multimodal interaction (e.g., voice or sketch), privacy‑preserving data handling, and a cloud‑native, pay‑as‑you‑go deployment model.
In summary, ICE demonstrates that a well‑engineered combination of low‑latency distributed storage, flexible feature pipelines, cost‑sensitive online learning, and a human‑friendly interaction language can empower non‑experts to rapidly develop deployable models for massive, skewed datasets. By turning the learning loop into a true collaborative process, ICE overcomes the labeling cost, speed, and performance bottlenecks that have traditionally limited active‑learning approaches, and it offers a promising foundation for next‑generation interactive AI systems in search, advertising, content moderation, and beyond.