Reinforcement Learning Based Algorithm for the Maximization of EV Charging Station Revenue
This paper presents an online reinforcement learning based application which increases the revenue of one particular electric vehicles (EV) station, connected to a renewable source of energy. Moreover, the proposed application adapts to changes in th…
Authors: Stoyan Dimitrov, Redouane Lguensat
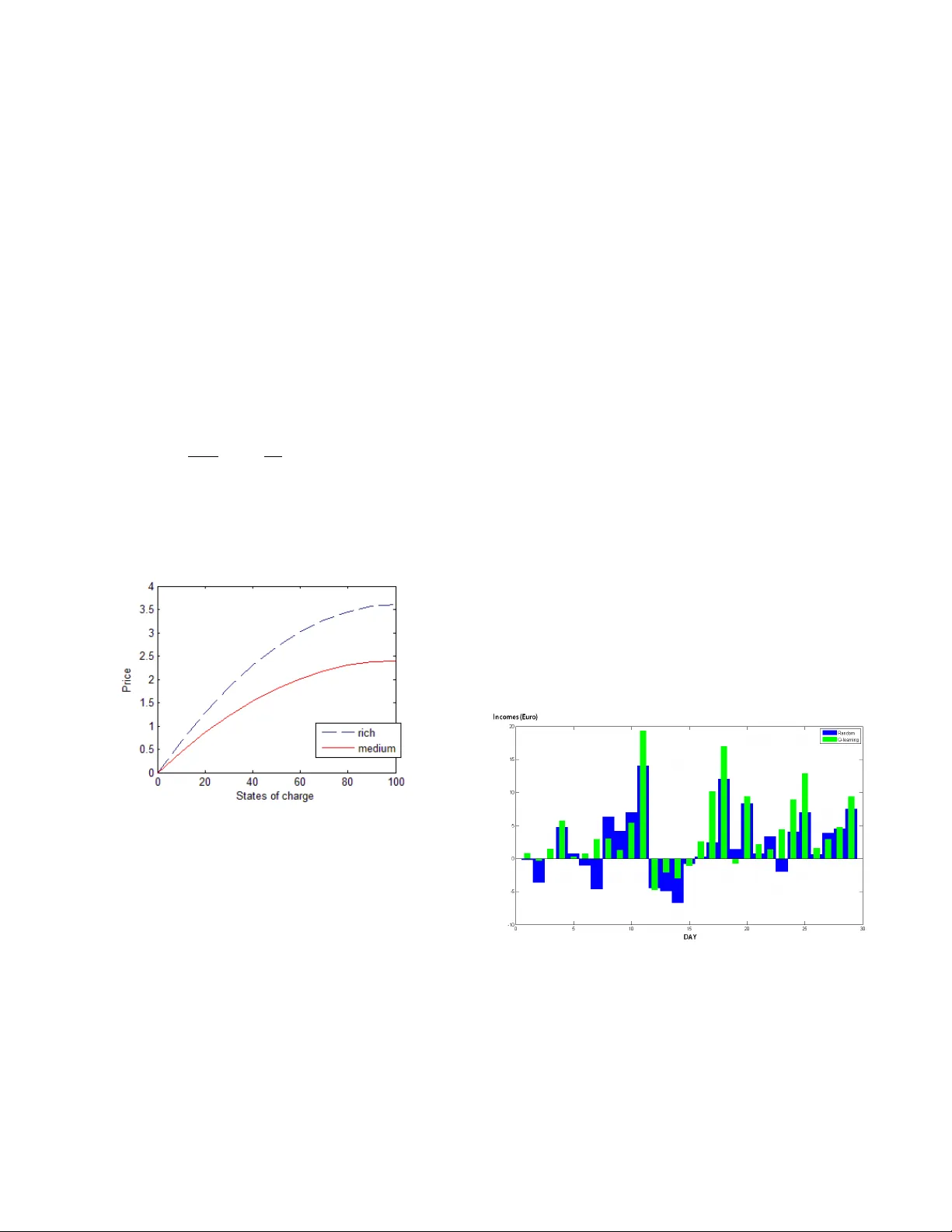
1 Reinforcement Learning Based Algorithm for the Maximization of EV Char ging Station Re v enue Stoyan Dimitrov , PHD student, Sofia University Redouane Lguensat, Student, T elecom Br etagne Abstract —This paper presents an online reinf orcement learn- ing based application which increases the rev enue of one particu- lar electric vehicles (EV) station, connected to a renewable source of ener gy . Moreo ver , the proposed application adapts to changes in the trends of the station’ s average number of customers and their types. Most of the parameters in the model are simulated stochastically and the algorithm used is the Q-learning algorithm. A computer simulation was implemented which demonstrates and confirms the utility of the model. Index T erms —Reinfor cement learning, electric vehicles, charg- ing stations, renewable energy , Q-learning I . I N T RO D U C T I O N O NE of the problems that hinders widespread use of electric vehicles (EV) is ”range anxiety”, users fear that their vehicle will stop in the middle of nowhere, because of the low battery lev el. The batteries of these plug-in hybrid electric vehicles are to be charged at home from a standard outlet or on a corporate car park. These extra electrical loads hav e an impact on the distribution grid such as power losses and voltage deviations. A mass domestic charging means that the v ehicles are char ged instantenously when they are plugged in or after a fixed start delay . This uncoordinated power consumption on a local scale can lead to grid problems[1]. This f act explains increasing concerns with char ging stations and it has led many researchers to work on theoretical models of the functioning of these stations. In our case, we present a model of an EV charging station, together with an allocation mechanism for its resources. The aim is to maximize station’ s rev enue taking into consideration fluctuations of electricity price during the day . W e named our algorithm SAEDS (Station Automated Elec- tricity Distribution System). It is based on the area of machine learning called reinforcement learning. The goal of SAEDS is to learn how good are the different decisions of the station in the different states that it could be. This is performed in the so-called ”learning phase”. After the end of this phase, the application uses the already learned information to distribute electricity supply among the plugged-in vehicles. EV charging stations are connected to the electrical grid, which often means that their electricity comes from fossil- fuel power stations or nuclear power plants. In our model, it is assumed that the EV station is connected to a rene wable source of ener gy . The fact, that the amount of electricity receiv ed from this source needs prediction, makes the model more complex. The complexity of the cosidered problem justifies the use of Machine Learning algorithm, instead of alternav e approaches. Sections II and III speaks about the literature we ha ve used and about the theory behind the Q-learning method, respectiv ely . Sections IV contains the details of the model we consider and the algorithm we use to solve it. Section V describes the results of the computer simulation, created to test SAEDS. The conclusion is stated in section VI. I I . R E L A T E D W O R K This work is very similar to those of O’Neill et al. in [2]. There, they present an online learning application for residential demand response that uses Q-learning to learn the behavior of the consumers and to make optimal energy consumption decisions. W e noticed that the same approach can be applied in the context of electric vehicles charging, viewing on the charging station as one big household, which wants to minimize its expenses, or equiv alently , to maximize its incomes. The clients of the station, with their v ehicles, play the same role as the electrical devices of the household in [2]. Whether a vehicle or a household device will be plugged in at a particular moment is determined probabilistically in both papers. Another related publication (V alogianni et al. [6]) proposes a smart charging algorithm that uses Q-learning trained on real world data to learn the individual household consumption behavior . Additionally , an EV charging algorithm is proposed which maximizes individual welfare and reduces the indi vidual energy expenses. Making the best energy consumption decisions was the purpose of several existing papers, which consider Demand Response systems[3]. Ho wev er , few of them use reinforcement learning. Reinforcement learning has appeared in numerous books such as ”Handbook of Brain Theory and Neural Networks” by Barto[4], and ”Introduction to Reinforcement Learning” by Sutton and Barto[5], which we hav e used because it gi ves detailed information on the subject and the algorithms used. The main idea behind reinforcement learning and more specifically the Q-learning algorithm is described in the next section. I I I . R E I N F O R C E M E N T L E A R N I N G : Q - L E A R N I N G Reinforcement learning is a method used to solve problems, formulated as Markov Decision Processes (MDP). It consists of performing a set of experiences which result in positiv e or negati ve r ewar ds in order to optimize an objective function. In these types of problems, an active decision-making agent is confronted with an en vironment, in which it aims to achiev e a goal, despite its lack of knowledge of the environment.. The agent’ s actions affect the future state of the en vironment, 2 so the purpose is to make the agent dev elop a policy , which would point him to the action, giving the best reward at each particular stage. Q-learning, a reinforcement learning technique was first introduced by W atkins in 1989 [7]. The algorithm makes use of a value iteration update. The value, called a Q-function value, is the expected utility of making a particular decision in a particular state. Thus, Q is a function ov er pairs of states and actions of the agent, who takes the decisions. The updating of a Q-value is performed by taking the old value and making a correction based on the ne w information learned. The algorithm is proved to be con vergent under certain conditions and giv es optimal policy for finite MDP . Let’ s denote with s - a state of the system( s’ for the state following s ) and with a - an action, which the agent could do. For every state, there exists a set of possible actions. Below , the actions a and a’ belongs to the possible sets of actions for states s and s’ , respectiv ely . At each step, the agent choose an action for which the Q-value, Q(s,a), is maximized(the agent follows a decision policy derived from Q). The algorithm is as follows: Algorithm 1 Q-learning algorithm (Sutton and Barto 1998) Initialize Q(s,a) arbitrary , for each addmisible state-action pair (s,a); For each episode: Initialize s with some state of the system. For each step of episode: · Choose an action a from the possible actions in the state s , using policy derived from Q · T ake action a , observe the rew ard r and the next state s’ · Update the Q-value: Q ( s, a ) ← − Q ( s, a ) + α [ r + γ max a 0 Q ( s 0 , a 0 ) − Q ( s, a )] s ← − s’ Here, α and γ are parameters, which reflects the learning rate of the algorithm. In our particular case, one day will corresponds to one episode and an hour to a step of episode. The reward r will be the sum that the station earns at the current hour of the day . I V . D E S C R I P T I O N O F T H E M O D E L W e are going to describe the details in the station’ s state representation, as well as the Q-Learning based application which controls the supply decisions of our EVs station, connected to a renew able source of energy . A. Some pr eliminary assumptions • Discrete time t 1 = 1 , 2 .., T . W e take T=24. The vehicles arriv e dynamically to the station and ev ery arri ving vehicle can start the recharging process as early as the beginning of the next hour interval. The station is observed over sev eral number of days. • The station has k slots and a maximum number of M participating vehicles (charging or waiting to be charged at any giv en moment). W e can thing that the station has M parking places in total, and at every single time maximum k of the v ehicles on them can be supplied. • When an EV arrives at the station, its driver , which represent the client, states his type which is a function of the vehicle’ s state of charge (SOC). This function giv es the amount of money that the client is ready to pay if his car’ s battery reaches the different states of charge (for example 5 Euros for SOC=10% and 15 Euros for SOC=20%). Knowing a client’ s type f ( x ) and his vehicle’ s initial SOC x 1 , the intermediate price he is going to pay , in order for his car to have S O C = x 2 can be easily calculated: f ( x 2 ) − f ( x 1 ) . For examples of client’ s type function, see Figure 2 in the next section. • Other information that the station recei ve is the Time T o Leav e (TTL) of the coming vehicle, i.e. after how many hours the client will expect his vehicle to be ready . • Additionally , we assume that a renew able source of energy is connected to the station, which supplies the station with variable amount of energy r ( t ) at each particular t (it is unknown before the moment t ). The transportation costs are neglected (the cost of transporting the energy from the rene wable source to the station slots). Moreov er , the station can b uy an additional amount of electricity from the grid at any specific time at price p ( t ) which also varies. Fig. 1. An EV charging station connected to the grid and to a renewable energy source B. The model SAEDS is going to learn the typical total energy demand of the station’ s customers in the different hours of the day . This approach takes advantage of the fact that the number of clients and their energy consumption at a particular time of the day would be similar each day (weekdays and weekends are not considered separately). The learning approach has to be applied with the help of a big Markov chain with state: Ω ( t ) = [ t 1 , USERS ( t ) , r ( t ) , p ( t )] , (1) where: 3 1) t 1 ∈ [1 .. 24] is the hour of the current day . t is the total number of hours elapsed from the beginning of the first day of the learning phase. In fact, t 1 is the remainder of t , when divided to 24. 2) The data structure USERS(t) consists of 3 column vec- tors of size M - TTL(t), SOC(t) and T ypes(t). - The times to leav e are integers between 1 and ttl max (the upper limit which we have set is 12). - SOCs are measured in percents of the full capacity of the battery . W e took 10 possible lev els- 0,10,20,..100. W e assume that every vehicle uses battery with the same capacity . - For T ypes, we ha ve taken fixed number of functions, chosen in advance. The particular functions that we hav e used are described in the next section. 3) r ( t ) is the amount of rene wable energy at time t . It is also discretized. 4) p ( t ) is the price per unit of extra energy that the station can buy from the grid at time t . W e have a queue of customers vehicles that is updated dy- namically with time.The occurrence of EV arriv als is modeled with non-homogeneous P oisson pr ocess i.e. the number of arriv als in the time interval (a, b], giv en as N(b)-N(a), follows a Poisson distribution with associated parameter λ a,b : P [( N ( b ) − N ( a )) = k ] = e − λ a,b . ( λ a,b ) k k ! , k = 0 , .., n (2) Thus, the number of arriving customers z ( t ) ∼ P o ( λ t,t +1 ) . Here, the rate λ t,t +1 , t ∈ 1 , 2 , ... 23 which is the av erage number of arriving vehicles during the interval of time [t,t+1], will hav e to be estimated by monitoring station data from the past. T T L i ( t ) , S O C i ( t ) and T y pes i ( t ) , i=1,2,..,M represent the characteristics of the i-th vehicle in the queue at time t . At any giv en time t , the vectors TTL, SOC and T ypes must be updated as follows: First, when new vehicles arri ve, if there are vacant spots among the M places in the station, priority is giv en on a first-come, first-served basis. After that the online application takes an action. The space of the application’ s possible actions at time t is formed from all of the vectors u ( t ) , where u i ( t ) = 0 , 10 or 100 − S O C i ( t ) . The station has k slots in total, so each possible action vector u ( t ) , must have no more than k nonzero components (10 or 100 − S OC i ( t ) ). In other words, at any particular hour , the station can gives the energy equiv alence of 10% SOC or the maximally possible energy equivalence (this, complementing to 100%) to k or less electric vehicles. This means that our station allows two speed lev els of charging: normal charging, which succeed to charge 10% in one hour, and fast charging, which can charge fully any vehicle, again in one hour . The SOC vector must be updated as follo ws: S O C ( t ) = S O C ( t ) + u ( t ) (3) S O C ( t + 1) = 100 ∗ { S OC ( t ) / 100 } (4) In the latter equation, {} means fractional part. In fact, with this equation we nullify the SOCs of the charged vehicles. T imes to leav e decreases by 1, as we go from time t to t + 1 : T T L ( t + 1) = T T L ( t ) − ~ 1 (5) Finally , the vehicles, whose TTLs have become 0, must be remov ed. Additionally , at each point in time the array of users is sorted by TTL and if ties occur , by type. In other words, we assume that the array T T L ( t ) = [ ttl 1 ( t ) , ttl 2 ( t ) ..., ttl M ( t )] has non-decreasing elements for ev ery t and for e very sequence of ties T T L i ( t ) = T T L i +1 ( t ) = ..... = T T L j ( t ) we hav e T y pe i ( t ) ≤ T y pe i +1 ( t ) ≤ ..... ≤ T y pe j ( t ) . This detail gradually decreases the number of possible states of the system. In order to generate the initial SOCs of the newly arriving EVs, we use manually setted distrib ution, chosen according to the history of our station. The times to leav e (TTL) are dependent on t (for example when an EV comes at 17h, the probability of small deadline before the start of the evening at 20h will increase). For generation of TTLs of the ne wly arri ved EVs, we use normal distribution with different parameters for the different day hours. For r ( t ) and p ( t ) , real data is used, whose origin is described in the data description section. The objective function (the station’ s reward at any giv en moment) will be: Φ(Ω( t ) , u ( t )) = incomes − expenses incomes = X m ∈ M [ T y pe m ( t ) . ( S O C m ( t )+ u m ( t )) − T y pe m ( t ) .S O C m ( t )] expenses = p ( t ) . [( X m ∈ M u m ( t )) − r ( t )] W e have a value function ov er states V (Ω) which represents the profitability of the state Ω . V (Ω) = min u (Φ(Ω , u ) + E [ V (Ω 1 )]) (6) In the latter equation, (Ω 1 is the station’ s state, following (Ω . Q-learning is an on-line, reinforcement learning method, which approximates the value of the function V (Ω) . Q- learning estimates the v alue of a Q-function for each state- action pair (Ω , u ) and V (Ω) = min u Q (Ω , u ) (7) In summary , the Markov chain will hav e states in the form of Ω . The transitional probabilities depend on { r ( t ) , p ( t ) } and are unknown. Let us describe the essence of the Q-learning algorithm: • At k = 0, initialize Q k (Ω , u ) for ev ery state-action pair (Ω , u ) and select initial state Ω . • Choose u = argmin Q k (Ω , u ) with probability 1 − α t , else let u be a random exploratory action(uniformly selected). • Carry out action u. Let the next state be Ω 0 , and the cost be Φ(Ω , u ) . Update the Q-values as follows: Q k +1 (Ω , u ) = (1 − β k ) .Q k (Ω , u ) + β k . (Φ(Ω , u ) + min u Q (Ω 0 , u )) (8) 4 Here, β k and α t are some probabilities chosen in ad- vanced. • Set the current state to Ω 0 , increment k and go to step 2. V . C O M P U T E R S I M U L A T I O N A. Users’ type function Users’ types are defined by customer’ s willingness to pay in order to have their vehicle charged if their initial SOC is 0%. The price that the user pay is the difference between the price of the SOC they want to reach and their initial SOC. In the simulation, we consider two types of users: the so called rich type of users and medium type of users. W e model their types’ function by an utility function represented by the quadratic function (9). This family of functions was choosen, because users pay less money for each extra 10% level of charging. In fact, this functions belongs to the family of sigmoid functions, which are widely used in practice. f ( x ) = ( max 100 (2 x − 1 100 x 2 ) if 0 ≤ x ≤ 100 max if x > 100 (9) The v ariable max refers to the price of fully charging an initially empty v ehicle. Example curves are sho wn in the figure below , where max rich = 3 . 6 and max medium = 2 . 4 Fig. 2. Users’ types B. Data description T wo categories of data were used - renewable energy data and pricing data. 2.1 Renew able energy As explained before, we suppose that the station is connected to a wind energy generator (wind turbine for example) and has a solar panel. W e need data about the average wind generation from a wind energy generator at hourly slots of the day . This data can be found on R ´ eseau de transport d’ ´ electricit ´ e (R TE) France website [8] and is provided as an Excel file. The data is about wind generation across France. For the sake of consistency , we divided all the numbers by 4058 (the number of wind turbines in France in 2012)[9]. For the solar panel generation, we assume that the EV charging station has a 10 m 2 solar panel which is capable of generating an av erage of 1000 kWh per year in France[9]. In order to calculate the amount of electricity per hour, we assume that solar panel generation follows a normal distribution. The generation peak is assumed to occur at 1.30 p.m. 2.2 Pricing The R TE France website also provides data about electricity prices at half hourly slots. W e take into account this data in our model by taking the average price at ev ery hour . C. Simulation parameters and r esults A comparison between the income (in euro) of a small EV station using SAEDS and the income of a station making random decisions at each point in time is depicted on the graph below . The income w as measured for 29 consecuti ve days after a training period with data for 190 days, repeated 40 times. The results sho ws that the income increases by 81 percents, which is a good result, in spite of the fact that the purely random strategy can be easily beaten with the set problem formulation. Howe ver , such a percentage is an evidence for a high learning effect. As a result of previous executions of the program, we have receiv ed slightly lower results, in the range of 40 to 80 percents of income increasing. Parameter values that were used to obtain these results are: M = 5 , k = 3 and the 2-type functions already described(rich and medium). For r(t) and p(t)- for simplicity , we took only two possible values- high and low . For α and β (parameters of the learning process) were taken linear by t functions. Fig. 3. Income (in euro) comparison between an EV station which uses our algorithm (green), and an EV station that uses random decisions (blue). V I . C O N C L U S I O N W e tried to apply an already existing approach [2] of learn- ing an optimal decision policy , but in the context of electric vehicles charging. There are sev eral similarities between the problem, formulated in [2] and the study formulated in our paper , which portended good final results. After implementing the model on a computer , it was observed that our algorithm outperformed the most trivial one (uniform distribution ov er 5 each possible decision, on every step). The increase of the station’ s incomes in the range 40-80% shows that using this learning approach is meaningful. W e can conclude that the proposed learning scheme per- forms at a satisfying level. Nev ertheless, the model can be adjusted in order to mimic reality more closely . Probably , some of the numerical parameters in the algorithm can be adjusted more precisely , in order to receive bigger increase of the incomes. Howe ver , the utility of the proposed learning scheme is obvious. R E F E R E N C E S [1] K.Clement-Nyns, E.Haesen, J.Driesen, ”The Impact of Charging Plug- In Hybrid Electric V ehicles on a Residential Distribution Grid”, Power Systems, IEEE Transactions on, V ol.25 , Issue: 1, Dec. 2009 . [2] D. ONeill, M. Lev orato, A.J. Goldsmith and U. Mitra, ”Residential De- mand Response Using Reinforcement Learning” IEEE SmartGridComm, Oct. 2010, Gaithersburg, Maryland, USA. [3] S. Borenstein, M. Jaske, and A. Rosenfeld, ”Dynamic pricing, advanced metering, and demand response in electricity markets, ” UC Berkeley: Center for the Study of Energy Markets , Oct. 2002. [Online]. A vailable: http://www .escholarship.org/uc/item/11w8d6m4 [4] A. G. Barto, Reinforcement Learning, in handbook of Brain Theory and Neural Networks, M.A. Arbib (Ed.), Cambridge: MIT Press, 1994. [5] Richard S. Sutton and Andrew G. Barto. 1998. Introduction to Reinforce- ment Learning (1st ed.). MIT Press, Cambridge, MA, USA. [6] K onstantina V alogianni, W olfgang Ketter , John Collins, ”Smart Charging of Electric V ehicles using Reinforcement Learning”, AAAI Publications, W orkshops at the T wenty-Sev enth AAAI Conference on Artificial Intel- ligence. [7] W atkins, C.J.C.H. (1989). Learning from Delayed Rewards. PhD thesis, Cambridge University , Cambridge, England. [8] W ind power generation forecast, Rte France http://clients.rte- france.com/ lang/an/visiteurs/vie/previsions eoliennes.jsp [9] Planetoscope, information about wind generation and solar genera- tion in France: http://www .planetoscope.com/eolienne/804-production- d electricite-eolienne-en-france.html and http://www .planetoscope.com solaire/4-production-d-electricite-solaire-photov oltaique-en-france.html
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment