Quantifying the benefits of vehicle pooling with shareability networks
Taxi services are a vital part of urban transportation, and a considerable contributor to traffic congestion and air pollution causing substantial adverse effects on human health. Sharing taxi trips is a possible way of reducing the negative impact of taxi services on cities, but this comes at the expense of passenger discomfort quantifiable in terms of a longer travel time. Due to computational challenges, taxi sharing has traditionally been approached on small scales, such as within airport perimeters, or with dynamical ad-hoc heuristics. However, a mathematical framework for the systematic understanding of the tradeoff between collective benefits of sharing and individual passenger discomfort is lacking. Here we introduce the notion of shareability network which allows us to model the collective benefits of sharing as a function of passenger inconvenience, and to efficiently compute optimal sharing strategies on massive datasets. We apply this framework to a dataset of millions of taxi trips taken in New York City, showing that with increasing but still relatively low passenger discomfort, cumulative trip length can be cut by 40% or more. This benefit comes with reductions in service cost, emissions, and with split fares, hinting towards a wide passenger acceptance of such a shared service. Simulation of a realistic online system demonstrates the feasibility of a shareable taxi service in New York City. Shareability as a function of trip density saturates fast, suggesting effectiveness of the taxi sharing system also in cities with much sparser taxi fleets or when willingness to share is low.
💡 Research Summary
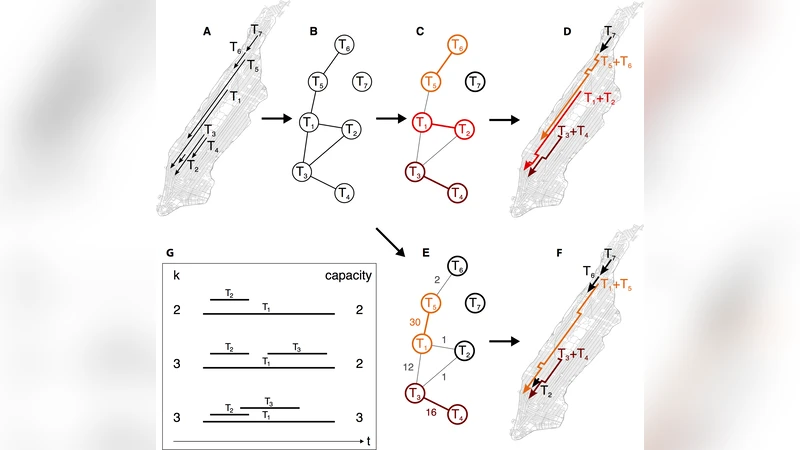
The paper tackles the pressing urban challenge of traffic congestion and air pollution by quantitatively assessing the potential of large‑scale taxi pooling. Rather than relying on small‑scale heuristics or dynamic pickup‑delivery formulations, the authors introduce a static graph‑theoretic construct called a “shareability network.” Each taxi request (origin, destination, start and end times) is represented as a node; an edge is drawn between two nodes if the two trips can be combined without exceeding a user‑defined maximum additional delay Δ and while respecting the natural order of pickups and drop‑offs. A second parameter, k, limits the number of trips that may share a single vehicle, reflecting vehicle capacity or policy constraints.
For k = 2 the network reduces to a simple undirected graph. The authors apply classical maximum‑matching algorithms to obtain (a) the largest possible number of shared trips (unweighted matching) and (b) the configuration that minimizes total travel time (weighted matching, where edge weights equal the extra distance or time incurred by sharing). When k > 2 the structure becomes a hyper‑graph; exact solutions become computationally prohibitive beyond k = 3, so the authors resort to heuristics for k = 3 and note that k ≥ 4 remains an open scalability problem.
The empirical backbone of the study is a massive 2011 New York City taxi dataset: 150 million trips performed by 13,586 licensed taxis within Manhattan, each with GPS‑derived pickup/drop‑off coordinates and timestamps. Travel times between arbitrary street intersections are estimated via a pre‑computed distance matrix and a simple heuristic, providing a realistic approximation of road‑network travel costs.
Two decision‑making scenarios are examined. The “Oracle” model assumes perfect foresight of all future requests, allowing a global optimum over the entire shareability network. Even with a modest Δ = 2 min, the Oracle predicts that nearly 100 % of trips could be paired, yielding a reduction of total vehicle‑kilometers by more than 40 %. The more realistic “Online” model restricts the decision horizon to a short time window δ = 1 min around each request, reflecting the latency constraints of real‑time e‑hailing apps. Despite this limitation, the Online model still achieves substantial benefits: with Δ = 5 min, roughly 30–40 % of trips can be shared, cutting total travel distance and time by about 30 %. Raising k to 3 further improves outcomes; at Δ = 10 min the total travel‑time reduction reaches ≈35 %.
A key insight is the rapid densification of the shareability network as Δ (or equivalently δ) grows, producing a hyperbolic saturation curve of the form f(x)=Kxⁿ/(1+Kxⁿ). This indicates that even in cities with far fewer taxis or lower willingness to share, a sizable fraction of trips remains shareable. The authors also translate shared‑trip counts into fleet‑size reductions: an 80 % shared‑trip rate corresponds to a ≈40 % decrease in active taxis, directly lowering fuel consumption and emissions by comparable margins. Moreover, fare splitting can make the service economically attractive to passengers.
From a computational perspective, the maximum‑matching for k = 2 runs in O(E√V) time; with modern distributed graph‑processing frameworks the authors demonstrate that networks containing over 150 million nodes and 100 billion edges can be processed within seconds, making real‑time deployment feasible. For k = 3, heuristic approaches still yield near‑optimal reductions, while k ≥ 4 remains computationally intractable with current methods.
In conclusion, the shareability‑network framework provides a rigorous, scalable tool for evaluating and designing city‑wide ride‑sharing systems. It quantifies the trade‑off between passenger inconvenience (Δ) and collective gains (reduced mileage, emissions, fleet size) and shows that substantial environmental and economic benefits are attainable even with modest tolerance for delay. The findings offer concrete, data‑driven evidence for policymakers and mobility providers to promote shared‑mobility services as a cornerstone of sustainable urban transport.
Comments & Academic Discussion
Loading comments...
Leave a Comment