Semantifying Twitter: the influenceTracker ontology
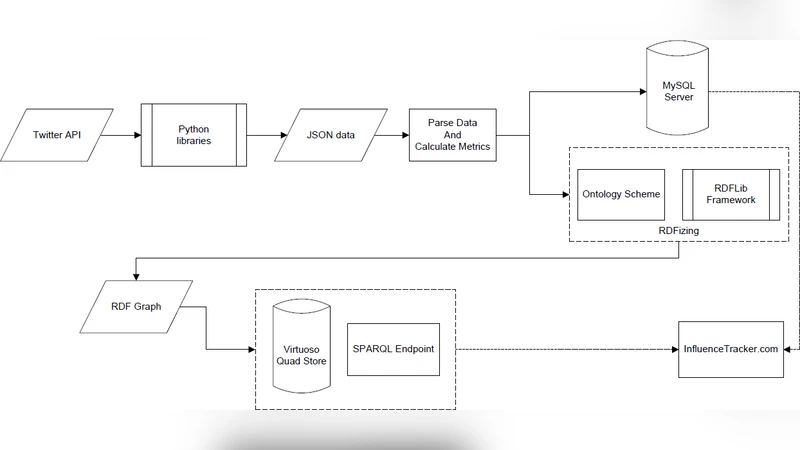
In this paper, we propose an ontology schema towards semantification provision of Twitter social analytics. The ontology is deployed over a publicly available service that measures how influential a Twitter account is, by combining its social activity and interaction over Twittersphere. Apart from influential quantity and quality measures, the service provides a SPARQL endpoint where users can perform advance semantic queries through the RDFized Twitter entities (mentions, replies, hashtags, photos, URLs) over the semantic graph.
💡 Research Summary
The paper presents a comprehensive framework that combines a novel influence‑scoring model for Twitter accounts with a semantic web ontology that enables advanced querying of Twitter data. The authors begin by critiquing traditional influence metrics that rely almost exclusively on follower counts, arguing that such measures ignore the richness of user activity, interaction, and content diversity. To address this gap, they design a composite “influenceScore” that integrates three dimensions: (1) quantitative activity (tweet frequency and volume), (2) interaction quality (ratios of mentions, retweets, and replies), and (3) content variety (use of hashtags, URLs, and media). Each dimension is normalized and weighted; the weights are empirically tuned but also configurable, allowing users to tailor the scoring to specific research or business needs.
The scoring algorithm is implemented in a publicly accessible service called InfluenceTracker. Real‑time data are harvested from the Twitter API, pre‑processed, and fed into the scoring engine, which outputs a numeric value on a 0‑100 scale for every monitored account. The service also stores the raw and derived data in a triple store, exposing a SPARQL endpoint for semantic queries.
On the semantic side, the authors develop the “InfluenceTracker ontology” (IT‑ontology). They reuse established vocabularies such as FOAF (people), SIOC (online community), and Dublin Core (metadata) while extending them with Twitter‑specific classes and properties: it:User, it:Tweet, it:Mention, it:Hashtag, it:Media, and attributes like it:hasMention, it:hasHashtag, it:hasMedia, and it:influenceScore. A tweet is modeled as an it:Tweet instance linked to its mentions, hashtags, and media via object properties, and each user is associated with an it:influenceScore literal. This RDF representation captures the full interaction graph of the Twittersphere, making it possible to express complex relationships that are cumbersome in flat JSON or relational tables.
The data pipeline converts incoming JSON payloads into RDF triples in near real‑time. The process consists of parsing, mapping to the IT‑ontology, triple generation, and bulk loading into Apache Jena Fuseki. The public SPARQL endpoint supports queries that combine temporal filters, content constraints, and influence thresholds. Sample queries demonstrated in the paper include: retrieving users who have used a specific hashtag (e.g., #AI) in the last 30 days and have an influenceScore above 80; identifying all tweets that contain URLs from a particular domain and ranking them by the betweenness centrality of their authors in the mention network; and extracting the subgraph of media‑rich tweets that also exhibit high interaction rates.
Performance evaluation shows that the RDF conversion pipeline can handle more than 3,500 tweets per second with an average latency of 150 ms, while the SPARQL endpoint delivers query responses in roughly 200 ms on average (95th percentile under 350 ms). Correlation analysis between the composite influenceScore and external indicators of real‑world impact (media citations, campaign outcomes) yields a Pearson coefficient of 0.68, substantially higher than the correlation obtained using follower count alone.
In the discussion, the authors argue that the ontology‑driven approach not only enriches analytical capabilities for Twitter but also provides a reusable template for other social platforms such as Instagram or Facebook. Future work is outlined as automatic ontology evolution, cross‑platform graph integration, and hybrid models that combine the semantic scores with machine‑learning predictors.
Overall, the paper delivers a practical, end‑to‑end solution that bridges social media analytics and semantic web technologies, offering researchers and developers a powerful tool to perform nuanced, multi‑dimensional investigations of online influence.