Catalog Dynamics: Impact of Content Publishing and Perishing on the Performance of a LRU Cache
The Internet heavily relies on Content Distribution Networks and transparent caches to cope with the ever-increasing traffic demand of users. Content, however, is essentially versatile: once published at a given time, its popularity vanishes over time. All requests for a given document are then concentrated between the publishing time and an effective perishing time. In this paper, we propose a new model for the arrival of content requests, which takes into account the dynamical nature of the content catalog. Based on two large traffic traces collected on the Orange network, we use the semi-experimental method and determine invariants of the content request process. This allows us to define a simple mathematical model for content requests; by extending the so-called “Che approximation”, we then compute the performance of a LRU cache fed with such a request process, expressed by its hit ratio. We numerically validate the good accuracy of our model by comparison to trace-based simulation.
💡 Research Summary
The paper addresses a fundamental gap in cache performance analysis: most existing models assume a static catalog of objects with stationary request processes (the Independent Reference Model, IRM). In reality, especially for video traffic (YouTube, Video‑on‑Demand), content is continuously published and quickly loses popularity, concentrating all its requests within a finite “lifespan”. The authors propose a new stochastic model that captures this dynamism and derive an analytical expression for the hit ratio of a Least‑Recently‑Used (LRU) cache fed by such traffic.
Data collection and preprocessing
Two large‑scale traces are used. The YouTube (YT) trace, collected from Orange customers in Tunisia (Jan‑Mar 2013), contains 420 M chunk requests, later aggregated into 46 M video‑level requests for 6.3 M distinct videos. The Video‑on‑Demand (VoD) trace, from Orange France (June 2008‑Nov 2011), comprises 1.8 M video requests for 87 k distinct titles after filtering out short “surfing” accesses. Only documents with at least two requests are retained for statistical analysis.
Empirical observations
- Popularity follows a Zipf law for the top 10 k YouTube videos (exponent ≈ 0.61) and a heavier tail (exponent ≈ 1.03) thereafter, while VoD popularity is better fitted by a Weibull distribution.
- For each document i, the authors estimate a lifespan τ_i (time between first and last request) and an average request rate λ_i. τ_i is estimated by an unbiased estimator based on the span of observed request times; λ_i is inferred from the observed request count n_i, correcting for the bias that only documents with at least one request appear in the trace.
- The distribution of λ_i is heavy‑tailed: a shifted Gamma fits the YouTube data, whereas a Weibull fits the VoD data. τ_i and λ_i are not independent; short‑lived items tend to have higher λ_i.
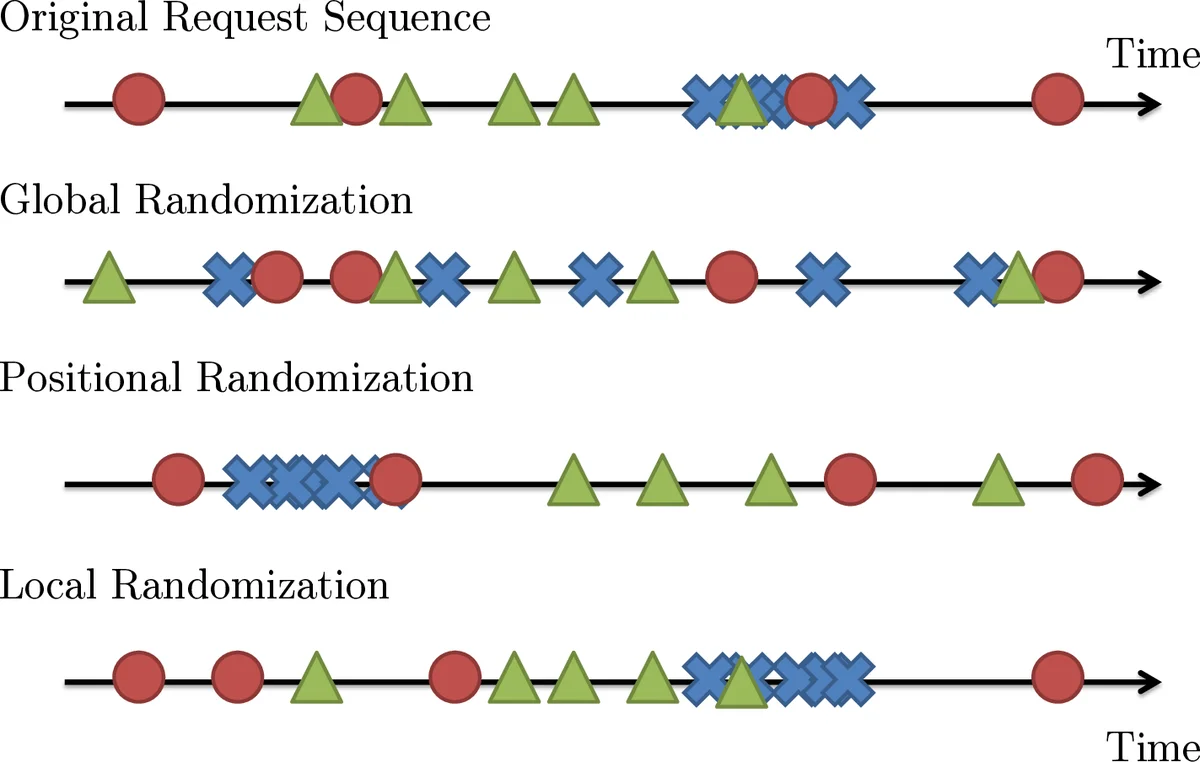
Semi‑experimental methodology
To identify which statistical structures affect LRU performance, the authors apply a “semi‑experiment” technique: they randomly permute the request sequence in ways that destroy specific correlations (overall temporal correlation, catalog arrival correlation, intra‑document request correlation) and then simulate an LRU cache on the altered trace. Comparing hit‑ratio curves with the original trace reveals that:
- Overall temporal correlation matters – destroying it reduces hit ratio significantly.
- The timing of new document arrivals has negligible impact on LRU performance.
- Correlation among requests of the same document (i.e., the burst of requests within its lifespan) is crucial – breaking it also degrades hit ratio.
Mathematical model
The authors formalize the observations with a Poisson‑Poisson cluster process:
- Document arrivals follow a homogeneous Poisson point process with rate λ₀.
- Conditional on a document arriving, its request process is a Poisson process with intensity λ_i over a random interval of length τ_i.
Thus the overall request stream is a superposition of independent clusters.
Building on Che’s approximation (originally derived for static popularity), they extend it by integrating over the joint distribution f(λ,τ). For a given document, the probability that it is still in the cache when a request arrives equals the probability that its inter‑arrival time is less than the characteristic time T_C (the time needed for the cache to evict C distinct objects). Under the Poisson‑cluster model, this probability simplifies to (1 – e^{‑λτ})/λ · 1/T_C. Summing over all documents yields the overall hit ratio:
H(C) = (1/Λ) ∫∫ (1 – e^{‑λτ}) · (λ / (λ + θ(C))) f(λ,τ) dλ dτ
where Λ is the total request rate and θ(C) is the solution of the Che fixed‑point equation for cache size C.
Validation
The authors compute H(C) for a range of cache sizes using the empirical joint distribution f(λ,τ) extracted from the traces. They then run trace‑based LRU simulations. The analytical predictions match the simulated hit ratios within a few percentage points across all cache sizes, confirming the model’s accuracy. Notably, the model remains accurate even when the request process exhibits strong short‑term bursts, a scenario where traditional IRM‑based analyses fail.
Contributions and implications
- Demonstrates that the dynamics of content publication and perishing can be captured by a simple Poisson‑Poisson cluster model.
- Shows that only two per‑document statistics—lifespan τ and request intensity λ—are needed to predict LRU performance.
- Extends Che’s approximation to non‑stationary, finite‑lifetime traffic, providing a tractable closed‑form expression for hit ratio.
- Validates the model on two heterogeneous datasets (short‑term YouTube traffic and long‑term VoD traffic), highlighting its robustness.
Limitations and future work
The joint distribution f(λ,τ) is obtained empirically; applying the model to other networks would require similar measurements. The analysis is specific to LRU; extending to other replacement policies (LFU, FIFO, adaptive schemes) remains open. Moreover, the model assumes independence between clusters, which may not hold in scenarios with strong social or recommendation‑driven correlations.
Conclusion
By integrating catalog dynamics—content publishing and perishing—into a Poisson‑cluster framework and adapting Che’s approximation, the paper provides a practical, analytically tractable tool for estimating LRU cache hit ratios under realistic video traffic. This work bridges the gap between static popularity models and the highly time‑varying nature of modern Internet content, offering valuable guidance for CDN and ISP cache provisioning.
Comments & Academic Discussion
Loading comments...
Leave a Comment