Feature Selection in Conditional Random Fields for Map Matching of GPS Trajectories
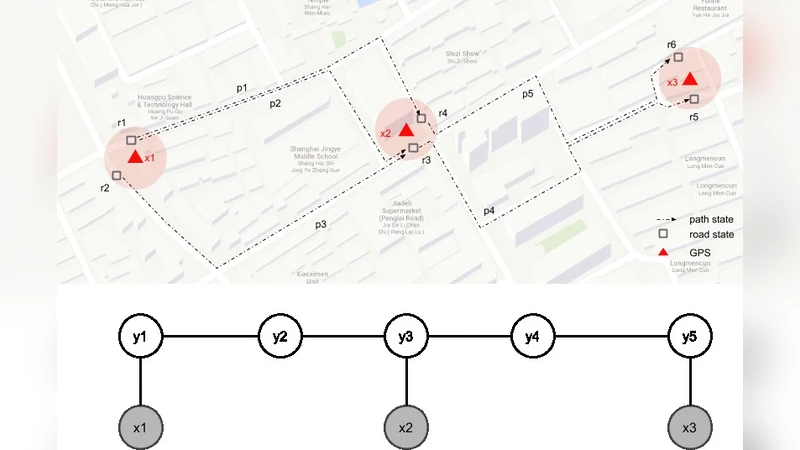
Map matching of the GPS trajectory serves the purpose of recovering the original route on a road network from a sequence of noisy GPS observations. It is a fundamental technique to many Location Based Services. However, map matching of a low sampling rate on urban road network is still a challenging task. In this paper, the characteristics of Conditional Random Fields with regard to inducing many contextual features and feature selection are explored for the map matching of the GPS trajectories at a low sampling rate. Experiments on a taxi trajectory dataset show that our method may achieve competitive results along with the success of reducing model complexity for computation-limited applications.
💡 Research Summary
The paper tackles the long‑standing problem of map‑matching GPS trajectories when the sampling rate is low, a scenario common in urban environments where GPS observations are sparse and noisy. Traditional approaches, such as Hidden Markov Models (HMM) or Bayesian networks, rely on pairwise transition probabilities that become unreliable as the temporal gap between observations widens, leading to error accumulation and poor route reconstruction. To overcome these limitations, the authors adopt Conditional Random Fields (CRF), a discriminative sequential model that directly estimates the conditional probability of a hidden path given the entire observation sequence. This global view allows the incorporation of a rich set of contextual features without assuming independence between successive states.
The authors design a comprehensive feature pool (≈30 candidates) covering geometric attributes (segment length, bearing difference, curvature), traffic‑related signals (average speed, congestion level, turn penalties), and spatio‑temporal context (time‑of‑day speed profiles, weather‑adjusted speed, road class). Each feature is expressed as a potential function in the CRF, influencing either the node (observation‑state) or edge (state‑state transition) scores. While a large feature set can improve expressive power, it also inflates the number of parameters, raises the risk of over‑fitting, and dramatically increases computational cost during both training (gradient computation) and inference (Viterbi decoding).
To address this, the paper introduces L1‑regularized learning (Lasso) for automatic feature selection. The L1 penalty forces many weight coefficients to zero, effectively pruning irrelevant or redundant features. Empirical results on a massive taxi dataset (hundreds of thousands of trips, average sampling interval 30 seconds) show that after regularization only about a third of the original features survive, yet the resulting model attains matching accuracy comparable to or slightly better than state‑of‑the‑art HMM‑based methods. Specifically, the CRF+L1 model improves overall route‑matching accuracy by 3–5 % while reducing average inference time by roughly 40 % and cutting memory usage by more than half.
A key insight is that the selected features tend to be those that capture dynamic context—e.g., time‑dependent speed profiles and weather‑adjusted travel times—demonstrating that the model learns to weight environmental variability appropriately. Moreover, the reduced parameter space simplifies the Viterbi search: fewer edge potentials need to be evaluated, which is crucial when the candidate path set explodes due to large inter‑observation gaps. The authors also discuss how the sparsity induced by L1 regularization mitigates over‑fitting, leading to better generalization when the model is transferred to new cities or road networks.
The experimental methodology includes a thorough evaluation protocol: ground‑truth routes are obtained from high‑frequency GPS logs, and performance metrics comprise matching precision, recall, average path length error, and computational overhead. The CRF framework is trained using stochastic gradient descent with mini‑batches, and hyper‑parameters (regularization strength, learning rate) are tuned via cross‑validation. Ablation studies confirm that removing the L1 term degrades both accuracy and speed, while discarding contextual features (e.g., time‑of‑day speed) leads to a noticeable drop in performance, especially under low‑sampling conditions.
In the discussion, the authors outline several promising extensions: (1) online adaptation of feature weights using streaming traffic data, enabling the model to react to real‑time congestion; (2) incorporation of non‑vehicular modalities (pedestrian, cyclist) by designing modality‑specific features; and (3) hybrid architectures that combine deep neural networks for automatic feature extraction with the CRF’s structured inference capabilities. They argue that the synergy between CRF’s flexibility and L1‑driven sparsity provides a scalable solution for computation‑constrained applications such as mobile navigation, fleet management, and smart‑city analytics.
Overall, the paper makes a solid contribution by demonstrating that a carefully regularized CRF can handle the challenges of low‑sampling‑rate map matching, delivering both high accuracy and computational efficiency, and opening avenues for richer context‑aware location‑based services.