Quantitative Analysis of Genealogy Using Digitised Family Trees
Driven by the popularity of television shows such as Who Do You Think You Are? many millions of users have uploaded their family tree to web projects such as WikiTree. Analysis of this corpus enables us to investigate genealogy computationally. The study of heritage in the social sciences has led to an increased understanding of ancestry and descent but such efforts are hampered by difficult to access data. Genealogical research is typically a tedious process involving trawling through sources such as birth and death certificates, wills, letters and land deeds. Decades of research have developed and examined hypotheses on population sex ratios, marriage trends, fertility, lifespan, and the frequency of twins and triplets. These can now be tested on vast datasets containing many billions of entries using machine learning tools. Here we survey the use of genealogy data mining using family trees dating back centuries and featuring profiles on nearly 7 million individuals based in over 160 countries. These data are not typically created by trained genealogists and so we verify them with reference to third party censuses. We present results on a range of aspects of population dynamics. Our approach extends the boundaries of genealogy inquiry to precise measurement of underlying human phenomena.
💡 Research Summary
The paper leverages the massive, crowd‑sourced genealogical database provided by WikiTree to conduct a large‑scale, quantitative investigation of human demographic patterns. The authors extracted records for 6.67 million individuals spanning more than 160 countries, encoding each person’s birth and death dates, sex, birthplace, marriage information, and four basic relationship types (spouse, child, parent, sibling). Outliers such as implausibly long lifespans were replaced with missing values, and the dataset’s overall quality was cross‑validated against official census and mortality statistics from national agencies.
Using this cleaned corpus, the study first illustrates the power of the data by visualising name‑frequency trends. The popularity curve of “Wendy” mirrors the cultural diffusion of the Peter Pan story, while the ratio of unique given names per decade reveals low name diversity during the High Middle Ages and the Victorian era, suggesting that the desire for uncommon names is a relatively recent phenomenon. The authors also quantify inter‑generational naming: the proportion of sons named after their fathers peaked in the 16th century, whereas daughters named after mothers remained consistently lower (about 24 % of twin pairs share the same initial letter).
Birth‑related analyses show a clear upward shift in maternal age at first and last childbirth when plotted in ten‑year bins, reflecting broader socioeconomic changes such as increased education and access to contraception. To test Hellin’s Law, the authors examined 963 416 births recorded between 1800 and 1900, finding 10 246 twins (0.0106 %) and 128 triplets (0.00013 %). These frequencies closely match the classic 1/89 and 1/89² expectations, and twin gender ratios are essentially even (male‑male 32.7 %, female‑female 33.9 %, mixed 33.3 %).
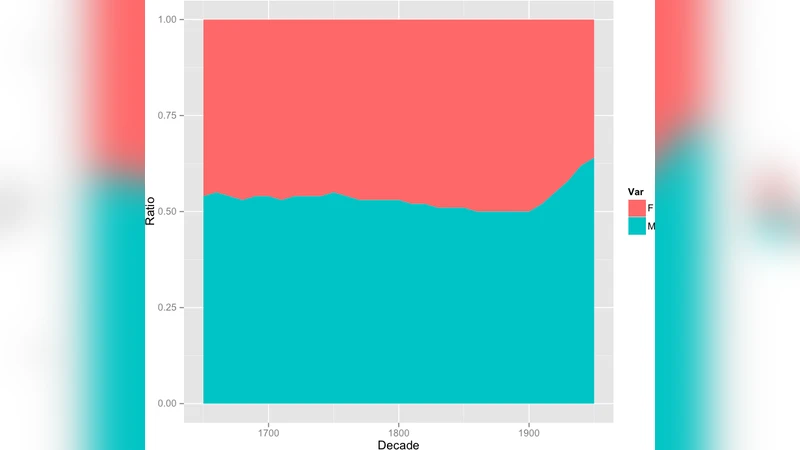
Sex‑ratio trends from 1650 to 1950 show a modest but steady rise in the proportion of female births. The authors acknowledge that this could stem partly from historical recording bias (male births more often documented) but also note that natural variations in sex ratios have been reported in the literature. Marriage‑age analysis confirms the long‑observed pattern that men marry later than women, and that average ages at first marriage have risen over the centuries, consistent with delayed family formation in modern societies.
Lifespan correlations provide further insight: the Pearson correlation between spouses’ ages at death is r = 0.224, while twin pairs exhibit r = 0.22, indicating that shared genetics and environment exert measurable influence on longevity. This empirical support aligns with prior sociological findings that marital stability can affect mortality risk.
The paper discusses several limitations. The dataset is self‑selected, heavily weighted toward Western populations, and lacks socioeconomic variables that would enable more nuanced causal inference. Relationship modeling is simplified to four categories, which may miss complex family structures such as step‑relationships or adoptions.
Finally, the authors outline future research avenues for computational genealogy. Potential projects include tracking immigration patterns via surname changes, overlaying lifespan data with economic or epidemic timelines to quantify the impact of wars, vaccinations, or public‑health interventions, assessing the demographic effects of major religious reforms, mapping geographic mobility of extended families, and integrating genetic disease detection by analysing intra‑family mortality clusters. By combining WikiTree data with other sources such as DNA databases or historical archives, scholars could generate a new class of evidence for social science, demography, and public‑health research.
Comments & Academic Discussion
Loading comments...
Leave a Comment