Are topic-specific search term, journal name and author name recommendations relevant for researchers?
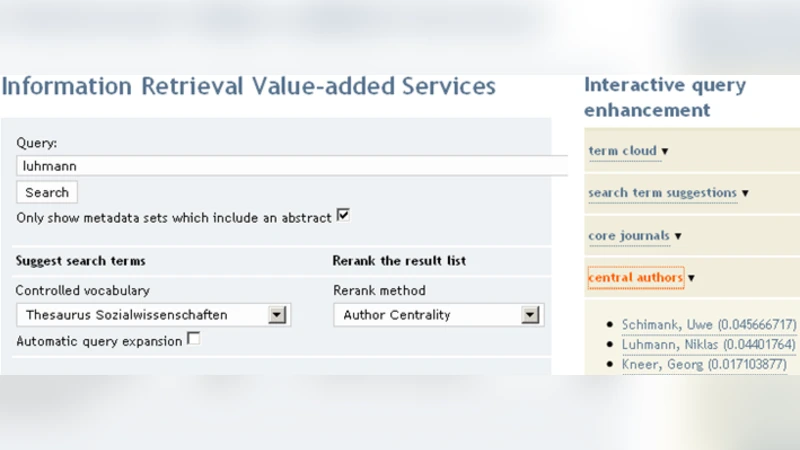
In this paper we describe a case study where researchers in the social sciences (n=19) assess topical relevance for controlled search terms, journal names and author names which have been compiled automatically by bibliometric-enhanced information retrieval (IR) services. We call these bibliometric-enhanced IR services Search Term Recommender (STR), Journal Name Recommender (JNR) and Author Name Recommender (ANR) in this paper. The researchers in our study (practitioners, PhD students and postdocs) were asked to assess the top n pre-processed recommendations from each recommender for specific research topics which have been named by them in an interview before the experiment. Our results show clearly that the presented search term, journal name and author name recommendations are highly relevant to the researchers’ topic and can easily be integrated for search in Digital Libraries. The average precision for top ranked recommendations is 0.75 for author names, 0.74 for search terms and 0.73 for journal names. The relevance distribution differs largely across topics and researcher types. Practitioners seem to favor author name recommendations while postdocs have rated author name recommendations the lowest. In the experiment the small postdoc group (n=3) favor journal name recommendations.
💡 Research Summary
The paper presents a case‑study evaluation of three bibliometric‑enhanced information‑retrieval (IR) services designed to assist researchers in the social sciences: a Search Term Recommender (STR), a Journal Name Recommender (JNR), and an Author Name Recommender (ANR). The authors first describe the technical construction of each recommender. STR extracts topic‑relevant keywords by combining TF‑IDF weighting with co‑citation analysis; JNR ranks journals using a hybrid of citation‑based impact measures and topical similarity; ANR identifies influential authors through a weighted author‑co‑citation network and PageRank‑style centrality. All three modules rely on a pre‑processed bibliographic corpus that includes citation links, author affiliations, and keyword metadata.
To assess practical relevance, the authors recruited 19 social‑science researchers representing three user groups: practitioners (7), PhD students (9), and post‑doctoral scholars (3). In a preliminary interview each participant defined one or more current research topics. For each topic the three recommenders generated the top‑5 items (search terms, journal titles, author names). Participants then rated the relevance of each recommendation on a 0–1 scale (binary relevance) which allowed the calculation of precision at various cut‑off points (P@1, P@3, P@5). The primary metric reported is average precision across all participants and topics.
Results show uniformly high relevance: ANR achieved an average precision of 0.75, STR 0.74, and JNR 0.73. Precision for the top‑1 recommendation was even higher (≈0.80 for all three), indicating that the highest‑ranked suggestion is almost always useful. However, relevance varied markedly across user types and topics. Practitioners gave the highest scores to author‑name recommendations (average 0.81), reflecting a need to quickly locate leading scholars in applied settings. Post‑docs, by contrast, rated author names lowest (average 0.62) and preferred journal recommendations (average 0.78), consistent with a focus on publication venue strategy. PhD students displayed a balanced pattern, with a slight preference for search‑term suggestions.
Topic‑level analysis revealed that some research areas (e.g., social network analysis) yielded high precision across all recommenders, while others (e.g., comparative cultural policy) produced lower scores for search terms (≈0.61). The authors attribute these differences to the density of bibliometric signals in the underlying corpus: well‑studied fields generate richer citation and keyword networks, enabling more accurate recommendations.
The study acknowledges several limitations. The sample size is modest, especially the post‑doc subgroup (n = 3), which restricts statistical generalisation. The preprocessing pipeline (e.g., synonym handling, author name disambiguation) is not described in sufficient detail to guarantee reproducibility. Moreover, the evaluation focuses solely on precision; other important dimensions such as recall, user satisfaction, search efficiency, and long‑term impact on research workflows remain unexplored.
Despite these constraints, the paper makes a valuable contribution by empirically demonstrating that bibliometric‑driven recommendation services can produce highly relevant search terms, journal venues, and author leads for real researchers. The findings suggest that tailoring recommender output to user roles—emphasising author names for practitioners and journal names for post‑docs—could enhance the usability of digital library interfaces. Future work is proposed to expand the participant pool across disciplines, incorporate additional evaluation metrics (MAP, NDCG, user‑task completion time), and develop interactive UI prototypes that allow real‑time feedback to refine recommendation models. Integrating usage logs with the bibliometric backbone could further personalise suggestions, ultimately advancing the next generation of scholarly search platforms.