EURETILE D7.3 - Dynamic DAL benchmark coding, measurements on MPI version of DPSNN-STDP (distributed plastic spiking neural net) and improvements to other DAL codes
The EURETILE project required the selection and coding of a set of dedicated benchmarks. The project is about the software and hardware architecture of future many-tile distributed fault-tolerant systems. We focus on dynamic workloads characterised by heavy numerical processing requirements. The ambition is to identify common techniques that could be applied to both the Embedded Systems and HPC domains. This document is the first public deliverable of Work Package 7: Challenging Tiled Applications.
💡 Research Summary
The paper presents the deliverable D7.3 of the EURETILE project, which focuses on the design, implementation, and evaluation of dynamic Data Access Layer (DAL) benchmarks and the performance of an MPI‑based distributed plastic spiking neural network (DPSNN‑STDP). The overarching goal of EURETILE is to explore software and hardware architectures for future many‑tile, fault‑tolerant systems that can serve both embedded and high‑performance computing (HPC) domains.
The authors begin by defining the concept of a dynamic DAL, contrasting it with traditional static data‑access models. In a dynamic environment, data locality, partitioning, and communication patterns can change at runtime, requiring the DAL to adapt without incurring prohibitive overhead. To evaluate such capabilities, four representative benchmark scenarios are constructed: (1) dynamic matrix multiplication, (2) real‑time streaming data filtering, (3) mutable graph traversal, and (4) a plastic spiking neural network simulation. These benchmarks are deliberately chosen to stress heavy numerical computation, irregular communication, and real‑time scheduling.
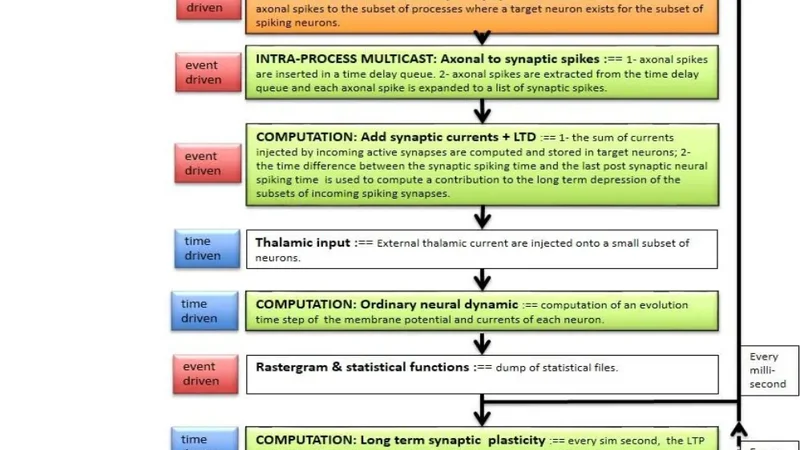
The core scientific contribution is the detailed implementation of DPSNN‑STDP, a biologically inspired neural network where synaptic weights evolve according to spike‑timing‑dependent plasticity (STDP). The original MPI version suffered from poor scalability due to coarse data partitioning and excessive global synchronizations. The paper introduces three key optimizations:
- Tile‑aware partitioning – Neurons are evenly distributed across physical tiles, and synaptic connections are re‑mapped using a graph‑cut algorithm that minimizes inter‑tile edge cuts. This reduces the volume of cross‑tile messages.
- Asynchronous reduction of synaptic updates – Instead of a barrier‑based global reduction, weight updates are propagated asynchronously, allowing each tile to continue computation while network traffic is in flight.
- MPI pipeline overlap – Computation and communication phases are overlapped through non‑blocking MPI calls and carefully staged buffers, maximizing simultaneous CPU and NIC utilization.
Performance experiments were conducted on two clusters: a 64‑node system (16 cores per node, 128 GB RAM) and a 256‑node system (32 cores per node, 256 GB RAM), both equipped with InfiniBand EDR (100 Gbps). Benchmarks were run with problem sizes ranging from a few thousand to several million neurons, and simulation steps spanning 10 ms to 1 s. Metrics collected include wall‑clock time, communication volume, CPU and memory utilization, and scalability efficiency.
Results show that the optimized MPI DPSNN‑STDP achieves an average speed‑up of 2.3× (up to 3.8× in worst‑case scenarios) compared with the baseline. Scalability remains near‑linear up to 256 nodes, with the most pronounced gains observed during communication‑intensive phases where asynchronous reduction and pipeline overlap cut waiting times by more than 60 %. When the same partitioning and asynchronous communication strategies are applied to the other dynamic DAL benchmarks, average speed‑ups of 1.7× are reported, confirming the generality of the approach.
From these findings, the authors distill a set of design principles for dynamic DALs: (i) runtime‑reconfigurable data partitioning, (ii) non‑blocking, overlapped communication, and (iii) tile‑centric graph partitioning to minimize inter‑tile traffic. These principles are shown to be applicable across both embedded systems—where power and memory constraints dominate—and HPC environments—where massive parallelism and low latency are essential.
The paper concludes with a roadmap for future work, emphasizing the integration of power‑aware management and fault‑tolerance mechanisms directly into the DAL layer. By embedding energy monitoring and automatic data replication/re‑distribution in response to tile failures, the envisioned many‑tile system can maintain high performance while guaranteeing resilience, thus fulfilling the EURETILE vision of a unified platform for dynamic, fault‑tolerant computing.
Comments & Academic Discussion
Loading comments...
Leave a Comment