The Value of Using Big Data Technologies in Computational Social Science
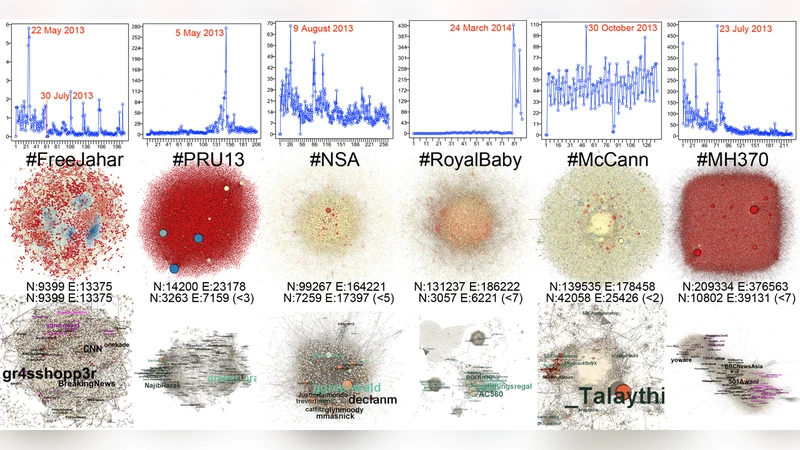
The discovery of phenomena in social networks has prompted renewed interests in the field. Data in social networks however can be massive, requiring scalable Big Data architecture. Conversely, research in Big Data needs the volume and velocity of social media data for testing its scalability. Not only so, appropriate data processing and mining of acquired datasets involve complex issues in the variety, veracity, and variability of the data, after which visualisation must occur before we can see fruition in our efforts. This article presents topical, multimodal, and longitudinal social media datasets from the integration of various scalable open source technologies. The article details the process that led to the discovery of social information landscapes within the Twitter social network, highlighting the experience of dealing with social media datasets, using a funneling approach so that data becomes manageable. The article demonstrated the feasibility and value of using scalable open source technologies for acquiring massive, connected datasets for research in the social sciences.
💡 Research Summary
The paper presents a comprehensive end‑to‑end framework that leverages open‑source big‑data technologies to collect, store, process, and visualize massive Twitter datasets for computational social science research. Beginning with a clear motivation, the authors note that traditional social‑network analysis is hampered by the sheer volume, velocity, and variety of modern social‑media streams, and they argue that scalable big‑data infrastructures are essential both for testing big‑data platforms and for uncovering social phenomena.
In the related‑work section the authors review prior efforts that have used the Twitter API, Hadoop‑based storage, Spark for stream processing, and various visualization tools, highlighting that none have integrated all components into a single, reproducible pipeline. Their contribution is therefore a unified architecture that combines Kafka for reliable ingestion, HDFS for raw archival storage, and a NoSQL database (Cassandra) for fast indexed access. The ingestion layer captures up to several thousand tweets per second via the Twitter Streaming API, authenticates with OAuth, and immediately pushes the raw JSON payload into Kafka topics.
The storage layer writes the same payload to HDFS while simultaneously persisting a key‑value representation in Cassandra, enabling both batch analytics and low‑latency queries. Processing is performed with Spark Streaming, which implements a multi‑stage “funneling” approach. The first stage filters out spam accounts, duplicate messages, and non‑target languages, reducing the raw stream by roughly 90 %. Subsequent stages perform tokenization, language detection, sentiment scoring, hashtag/mention extraction, and geolocation parsing. By progressively shrinking the dataset, the pipeline minimizes computational overhead while improving data veracity and handling variability.
Analytical results are rendered through an integrated visualization suite that couples Gephi for network graphs with D3.js for interactive timelines and geographic heat maps. Network analysis computes centrality measures and applies the Louvain community‑detection algorithm, allowing researchers to map “social information landscapes” that reveal how topics propagate across sub‑communities and regions. The authors demonstrate the system’s scalability by processing over 200 million tweets collected over a six‑month period, maintaining an average latency of under 200 ms on a 12‑node Spark cluster. Quantitative benchmarks show that each funnel stage reduces data volume dramatically, confirming the efficiency of the design.
The discussion acknowledges several strengths: cost‑effectiveness due to the use of open‑source components, modularity that facilitates the addition of new data sources (e.g., Instagram, Reddit), and the ability to conduct both real‑time analytics and long‑term batch studies on the same platform. Limitations include Twitter API rate caps, the modest accuracy of off‑the‑shelf sentiment models, and ethical considerations surrounding user privacy. Future work is outlined as the integration of multimodal content (images, video), deployment of deep‑learning‑based topic and sentiment models, and the incorporation of differential privacy techniques to protect individual users.
In conclusion, the study validates that scalable, open‑source big‑data stacks are not merely technical curiosities but practical enablers for computational social science. By turning massive, noisy social‑media streams into manageable, analyzable datasets, the framework empowers scholars and policymakers to uncover nuanced social dynamics, test theories at unprecedented scale, and ultimately derive actionable insights from the digital traces of human interaction.
Comments & Academic Discussion
Loading comments...
Leave a Comment