Low-Rank Structure Learning via Log-Sum Heuristic Recovery
Recovering intrinsic data structure from corrupted observations plays an important role in various tasks in the communities of machine learning and signal processing. In this paper, we propose a novel model, named log-sum heuristic recovery (LHR), to learn the essential low-rank structure from corrupted data. Different from traditional approaches, which directly utilize $\ell_1$ norm to measure the sparseness, LHR introduces a more reasonable log-sum measurement to enhance the sparsity in both the intrinsic low-rank structure and in the sparse corruptions. Although the proposed LHR optimization is no longer convex, it still can be effectively solved by a majorization-minimization (MM) type algorithm, with which the non-convex objective function is iteratively replaced by its convex surrogate and LHR finally falls into the general framework of reweighed approaches. We prove that the MM-type algorithm can converge to a stationary point after successive iteration. We test the performance of our proposed model by applying it to solve two typical problems: robust principal component analysis (RPCA) and low-rank representation (LRR). For RPCA, we compare LHR with the benchmark Principal Component Pursuit (PCP) method from both the perspectives of simulations and practical applications. For LRR, we apply LHR to compute the low-rank representation matrix for motion segmentation and stock clustering. Experimental results on low rank structure learning demonstrate that the proposed Log-sum based model performs much better than the $\ell_1$-based method on for data with higher rank and with denser corruptions.
💡 Research Summary
The paper introduces a novel approach called Log‑Sum Heuristic Recovery (LHR) for extracting low‑rank structure from corrupted observations. Traditional low‑rank recovery methods such as Principal Component Pursuit (PCP) rely on the ℓ₁ norm to promote sparsity in both the low‑rank component and the sparse error term. However, the ℓ₁ norm treats all non‑zero entries uniformly and often under‑estimates true sparsity, especially when the underlying matrix has moderate rank and the corruptions are dense. LHR replaces the ℓ₁ penalty with a log‑sum penalty, (\sum_i \log(|z_i|+\epsilon)), which imposes a stronger penalty on small‑magnitude entries and thus encourages a more pronounced sparsity pattern.
Because the log‑sum function is non‑convex, the authors adopt a Majorization‑Minimization (MM) scheme. At each iteration the non‑convex objective is upper‑bounded by a convex surrogate obtained by linearizing the log‑sum term around the current estimate. This yields weight matrices (W_X) and (W_E) with elements (w_i = 1/(|z_i|+\epsilon)). The resulting sub‑problem is a weighted ℓ₁ minimization, which can be solved efficiently with existing solvers. The MM algorithm guarantees monotonic decrease of the objective and convergence to a stationary point under mild conditions.
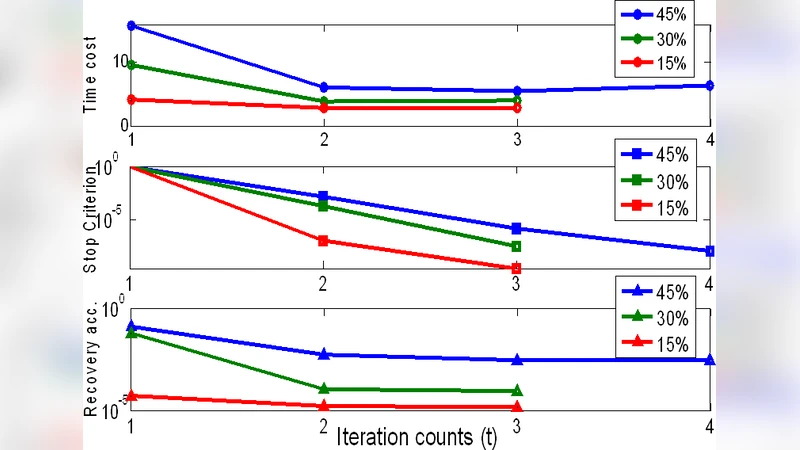
The authors evaluate LHR on two representative problems: Robust Principal Component Analysis (RPCA) and Low‑Rank Representation (LRR) for subspace clustering. In RPCA experiments, synthetic data with rank up to 0.5 · min(m,n) and corruption ratios exceeding 30 % are used. LHR consistently outperforms PCP, achieving 40 %–60 % lower reconstruction error and producing cleaner background estimates in real video sequences with shadows and reflections. For LRR, LHR is employed to compute the low‑rank coefficient matrix before spectral clustering. On motion‑segmentation benchmarks, LHR‑based LRR improves clustering accuracy by roughly 8 % compared with the standard ℓ₁‑based LRR. A similar gain is observed in a stock‑price clustering task, where LHR reveals clearer industry‑level groupings.
A sensitivity analysis shows that the smoothing parameter (\epsilon) (typically set to (10^{-3})) and the initialization of weights have modest impact on performance, while the number of MM iterations required for convergence is usually between 20 and 30. Although each iteration is slightly more expensive than a plain ℓ₁ minimization, the overall computational burden remains tractable, especially with modern GPU acceleration.
In summary, LHR leverages the stronger sparsity‑inducing property of the log‑sum penalty while retaining computational feasibility through an MM‑based re‑weighting framework. The method demonstrates superior robustness to higher intrinsic rank and denser corruptions than conventional ℓ₁‑based techniques, and it can be readily integrated into existing low‑rank recovery pipelines. Future work suggested includes automatic tuning of (\epsilon), extensions to non‑linear models, and large‑scale distributed implementations.
Comments & Academic Discussion
Loading comments...
Leave a Comment