Compressed Sensing with Very Sparse Gaussian Random Projections
We study the use of very sparse random projections for compressed sensing (sparse signal recovery) when the signal entries can be either positive or negative. In our setting, the entries of a Gaussian design matrix are randomly sparsified so that onl…
Authors: Ping Li, Cun-Hui Zhang
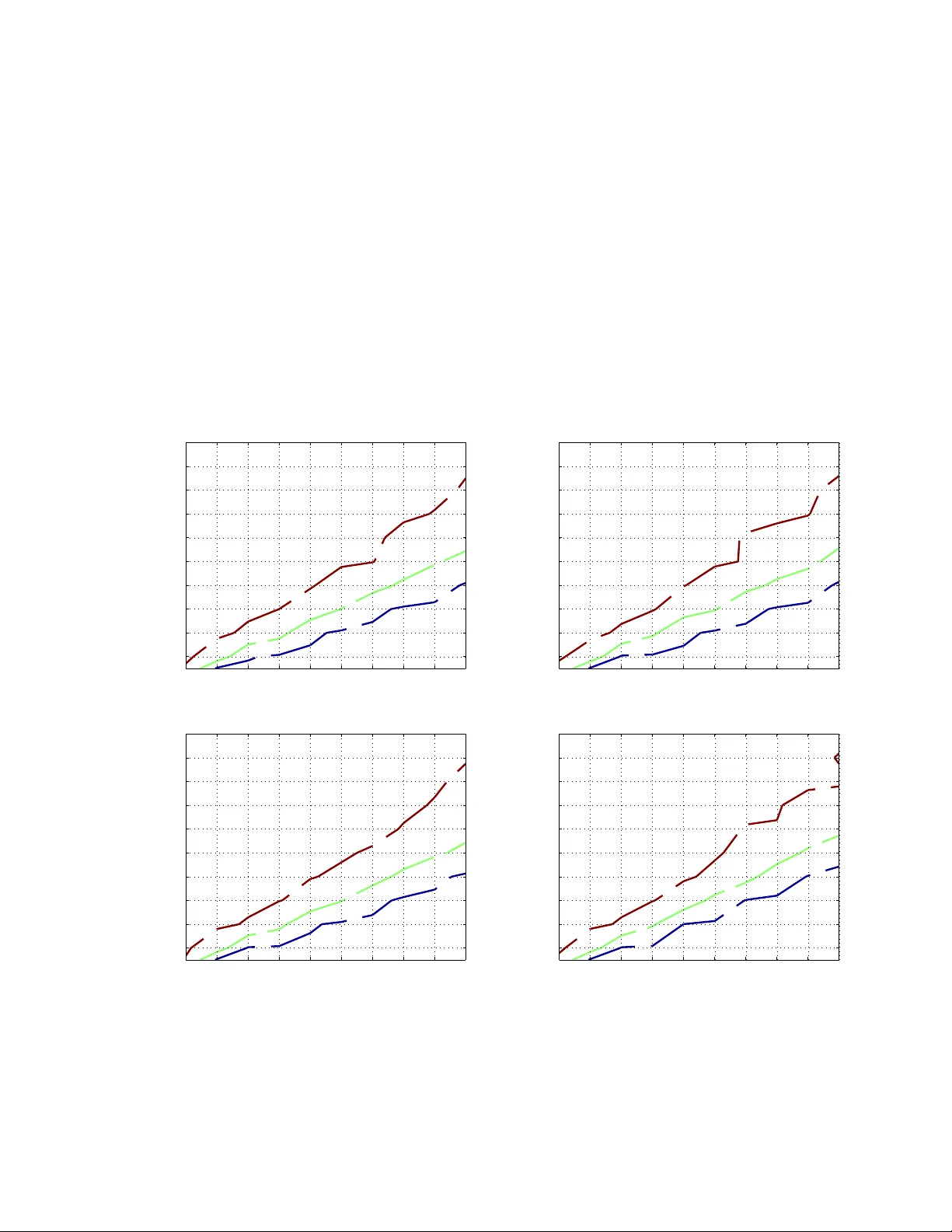
Compressed Sensing with V ery Sparse Gaussian Random Projections Ping Li Department of Statistics and Biostatisti cs Department of Computer Science Rutgers Univ ersity Piscataw ay , NJ 08854, USA pingli@sta t.rutgers .edu Cun-Hui Zhang Department of Statistics and Biostatisti cs Rutgers Univ ersity Piscataw ay , NJ 08854, USA cunhui@sta t.rutgers .edu Abstract W e study the use of very sparse random pr ojections f or compressed sensing (spar se signal recovery) when the s ignal entries can be either positi ve or negati ve. In our setting, the entries of a Gaussian design matrix are rando mly sparsified so that only a very small fraction of the entries are nonzero. Our pr oposed decodin g algo rithm is simple and efficient in that th e major cost is one lin ear scan of the coo rdinates. W e ha ve developed two estimators: (i) the tie estimator , and (ii) the absolute minimum estimator . Using only the tie estimator, we a re able to recover a K -sparse signal o f length N using 1 . 551 eK log K/δ measuremen ts (where δ ≤ 0 . 05 is the co nfidence) . Using only the ab solute minimum estimato r , we can detect th e suppor t of the signal u sing e K lo g N/ δ measurements. For a particu lar coor dinate, the abso- lute minimu m estimato r requir es fewer mea surements (i.e., with a constant e instead of 1 . 551 e ). Thus, the two estimators can be combined to form an e ven more practical deco ding framew ork. Prior studies h av e shown that existing on e-scan (or r ough ly one-scan) recovery algorithm s using sparse matrices would require substantially more (e. g., one or der of magnitud e) measurements than L1 decoding by linear programming , when the nonzero entries of sign als ca n be either n egati ve or p ositiv e. In this paper, following a known experimental setup [ 1] 1 , we show th at, at the same n umber of measur ements, the recovery accurac ies of our proposed method are (at least) similar to the standard L1 decoding. 1 http://groups. csail.mit.edu/t oc/sparse/wiki /index.php?title=Sparse_Recovery_Experiments 1 1 Introd uction Compr es sed Sensing (CS) [9, 4] has become an importa nt and popu lar topic in sev eral fields, including Computer Scien ce, Engineerin g, A pplied Ma thematic s, and Statistics. The goa l of compre ssed sens ing is to reco ve r a sparse signal x ∈ R 1 × N from a small number of non-a dapti v e linear measuremen ts y = xS , where S ∈ R N × M is the “design” matrix (or “sensing” m atrix). T ypicall y , the signal x is assumed to be K -sp arse (i.e., K nonzer o en tries) and neither th e magnitudes n or locations of t he nonzer o coor dinate s are kno wn. Many streaming /datab ase appl ication s c an be naturall y formulated as compress ed sensing problems [5, 7, 14] (e ve n before the name “compressed sensing” was pro posed ). The idea of compressed sensing m ay be traced back to many pr ior papers, for example [10, 8]. In the l iteratu re of compress ed sensing, entri es of the des ign matrix S are often sampled i.i.d. from a Gaussian distrib ution (or Gaussian- like distr ib utio n, e.g., a distr ib utio n with a finite secon d moment). W ell-k no wn reco v ery alg orith ms are often based on lin ear pro gramming (LP) (e.g., basis pu rs uit [6] or L1 decod ing) or greedy methods such as orthogo nal matching pursuit (OMP) [16, 13, 18, 17]. In genera l, L1 decod ing is computat ionall y expensi ve. OMP is often more efficie nt than L1 decoding but it can still be exp ensi v e especially w hen K is large. 1.1 Compr essed Sensing with V ery Sparse Random Pr ojections The process of collectin g measurements, i.e., y = xS , is often called “random projecti ons”. [12] studied the idea of “very sparse random project ions” by randomly sparsif ying the sensing matrix S so that only a ver y small frac tion of the en tries can be nonzero. In this p aper , we will continue to in vestigate on the ide a of ve ry sparse random projectio ns in the con tex t of compressed sensing. Our work is related to “sparse reco ver y with sparse matrice s” [3 , 2, 11, 15], for examp le, the SMP ( Spar se Matc hin g Pur suit ) algorithm [3]. There is a nice well-kno wn wiki page [1 ], which summarize s th e comparis ons of L1 decodin g with count-min sketch [7] and SMP . Their results hav e sho wn that, in order to achie v e similar rec ov ery accura cies, cou nt-min sk etch needs about 10 to 15 times more measurement s tha n L1 decodi ng an d SMP needs about half of the measuremen ts of count-min sketch. In comparison, our experi mental sectio n (e.g., Figure 2) demonstrate s that th e proposed method can be as accurate as (or e v en more accu rate tha n) L 1 decoding, at the same number of measurement s. The major cost of our method is one linea r scan of the coordinates , lik e count-min sketch . 1.2 Linear Measur ements fr om Sparse Projec tions In this paper , our procedure for compressed sensing first co llects M non-adapti v e lin ear measuremen ts y j = N X i =1 x i [ s ij r ij ] , j = 1 , 2 , .. ., M (1) Here, s ij is the ( i, j ) -th entr y of th e design matri x with s ij ∼ N (0 , 1) i.i.d. Instead of using a dense design matrix, we randomly sparsif y (1 − γ ) -fra ction of the entries of the design matrix to be zero, i.e., r ij = 1 with prob . γ 0 with prob . 1 − γ i.i.d. (2) And an y s ij and r ij are also indepe ndent . Our propo sed decoding scheme utilizes two simple estimators: (i) th e tie estimator and (ii) the absolu te minimum estimator . For con v enie nce, we will theoretica lly analyz e them separately . In pra ctice, these two estimato rs should be c ombined to form a po werful decod ing framewor k. 2 1.3 The T ie Estimator The tie estimator is de vel oped based on the follo wing interesting observ at ion on the rati o statistics y j s ij r ij . Conditio nal on r ij = 1 , we can w rite y j s ij r ij r ij =1 = P N t =1 x t s tj r tj s ij = x i + P N t 6 = i x t s tj r tj s ij = x i + ( η ij ) 1 / 2 S 2 S 1 (3) where S 1 , S 2 ∼ N (0 , 1) , i.i.d., and η ij = N X t 6 = i | x t r tj | 2 = N X t 6 = i | x t | 2 r tj (4) Note that η ij has certain probab ility of being zero. If η ij = 0 , then y j s ij r ij r ij =1 = x i . Thus, giv en M measuremen ts, if η ij = 0 happen s (at least) twice (i.e., a tie occurs) , we can ex actly iden tify the v alue x i . This is the ke y obser v ation w hich moti v ate s our proposal of the tie estimator . Another ke y observ ation is that, if x i = 0 , then we w ill not see a nonzero tie (i.e., the probability of nonze ro tie is 0). This is due to the fact that we use a G aussian design matrix, which excludes unwanted ties. It is also clear that the Gaussian assumpti on is not needed, as long as s ij follo ws from a continuo us distrib ution. In this paper w e focu s on G aussian desig n because it makes some detailed analysis easier . 1.4 The Absolute Minimum Estimator It turns out that, if we just need to detect wheth er x i = 0 , the task is easier than estimating the valu e of x i , for a particular coordinate i . Giv en M measurement s, if η ij = 0 happens (at leas t) once , w e will be ab le to determin e whether x i = 0 . Note that unlik e the tie es timator , this estimato r will generate “fal se po siti v es”. In other words , if we cannot be certain that x i = 0 , the n it is still possible that x i = 0 indeed. From the practica l perspecti v e, at a part icular coordinat e i , it is prefe rable to fi rst detec t w hether x i = 0 becaus e that would require fewer measurements than using the tie estimator . Later in the paper , we can see that the performan ce can be pot ential ly furth er impr ov ed by a more genera l esti mator , i.e., the so-cal led absolu te m inimum estimato r : ˆ x i,min,γ = z i,t , where t = argmin 1 ≤ j ≤ M | z i,j | , z ij = y j s ij r ij (5) W e will also introdu ce a threshold ǫ and provid e a theoretica l analysi s of the eve nt ˆ x i,min,γ ≥ ǫ . When ǫ = 0 , it becomes the “zero-detect ion” algorith m. Our an alysis will show that by using ǫ > 0 we can be tter exp loit the prior kno wledge we ha ve abo ut the signal and hence improve the ac curac y . 1.5 The Practical Proced ur e W e will separately analyz e the tie estimator and the absolu te minimum estimator , for the con venien ce of theore tical analysis. Howe v er , we recommen d a mixed procedure. That is, we first run the absolute minimum estimato r in one scan of t he coordinat es, i = 1 to N . Then we run the tie estimator onl y on those co ordin ates which are possibl y not zero. Recall that the absolute minimum estimator may generate false positi v es. As an option , we can iterate this proce ss for sev eral rounds. After one iteration (i.e., the absolute minimum estimator fo llo wed by the tie est imator), there might be a set of co ordina tes for which we cannot decide their value s. W e can compute the resi duals and use them as the measu rements for th e next iteration. T ypica lly , a few (e.g., 3 or 4) iteration s are sufficie nt and the major computational cost is computing the absolu te min imum estimator in the ver y first iteration. 3 2 Analysis of the Absolute Minimum Estimat or The important task is to analyze the fa lse positi ve pr obabi lity: Pr ( | ˆ x i,min,γ | > ǫ, x i = 0) for some chose n thresh old ǫ > 0 . Later we will see that ǫ is irrele v an t if we only care about the worst case . Recall tha t, conditi onal on r ij = 1 , we can expres s y j s ij r ij = x i + ( η ij ) 1 / 2 S 2 S 1 , wher e S 1 , S 2 ∼ N (0 , 1) i.i.d. and η ij is defined in (4). It is kno wn that S 2 /S 1 follo ws the stand ard C auchy distr ib utio n. Therefore, Pr S 2 S 1 ≤ t = 2 π tan − 1 ( t ) , t > 0 (6) W e are ready to presen t the L emma about the false positi ve probab ility , inclu ding a practicall y useful data-d epend ent bound , as wel l as a data-in depen dent bound (which is con venien t for worst- case analysis ). 2.1 The False P ositive Pr obability Lemma 1 D ata-dep endent bound: Pr ( | ˆ x i,min,γ | > ǫ, x i = 0) = " 1 − γ E ( 2 π tan − 1 ǫ η 1 / 2 ij !)# M (7) ≤ 1 − γ 2 π tan − 1 ǫ q γ P t x 2 t M (8) Data-indep endent (worst case) bound: Pr ( | ˆ x i,min,γ | > ǫ, x i = 0) ≤ h 1 − γ (1 − γ ) K i M (9) Remark: The data-depend ent bound (7) and (8) can be numerically ev alu ated if we ha ve information about the data. The bound will help us understand why empirically the performance of our propose d al- gorith m is substantiall y better than the worst-case bound. On the other hand, the worst case bound (9) is con venien t for the oretic al analy sis. In fact, it direct ly le ads to the eK log N complexity bound . Pro of of Lemma 1 : For con ven ience , we define the set T i = { j, 1 ≤ j ≤ M , r ij = 1 } . Pr ( | ˆ x i,min,γ | > ǫ, x i = 0) = E Pr y j s ij > ǫ, x i = 0 , j ∈ T i | T i = E Y j ∈ T i " Pr S 2 S 1 > ǫ η 1 / 2 ij , x i = 0 !# = E Y j ∈ T i " 1 − 2 π tan − 1 ǫ η 1 / 2 ij !# = E " 1 − E ( 2 π tan − 1 ǫ η 1 / 2 ij !)# | T i | = " 1 − γ + γ ( 1 − E ( 2 π tan − 1 ǫ η 1 / 2 ij !))# M = " 1 − γ E ( 2 π tan − 1 ǫ η 1 / 2 ij !)# M 4 By noticin g that f ( x ) = tan − 1 a √ x , (where a > 0 ), is a con vex functi on of x > 0 , w e can obtain an upper bound by using Jensen ’ s ineq uality . Pr ( | ˆ x i,min,γ | > ǫ, x i = 0) = " 1 − γ E ( 2 π tan − 1 ǫ η 1 / 2 ij !)# M ≤ " 1 − γ ( 2 π tan − 1 ǫ ( E η ij ) 1 / 2 !)# M ( Jense n’ s Inequa lity ) = 1 − γ 2 π tan − 1 ǫ γ P t 6 = i x 2 t 1 / 2 M = 1 − γ 2 π tan − 1 ǫ q γ P t x 2 t M W e can furth er obtain a worst case bound as follo ws. N ote that η ij has some mass at 0. Pr ( | ˆ x i,min,γ | > ǫ, x i = 0) = " 1 − γ E ( 2 π tan − 1 ǫ η 1 / 2 ij !)# M ≤ 1 − γ 2 π tan − 1 ǫ 0 Pr ( η ij = 0) M = h 1 − γ (1 − γ ) K i M 2.2 The False Negative Pr ob ability It is also necess ary to control the false negat i ve prob abilit y: Pr ( | ˆ x i,min,γ | ≤ ǫ, x i 6 = 0) . Lemma 2 Pr ( | ˆ x i,min,γ | ≤ ǫ, x i 6 = 0) =1 − " 1 − γ E ( 1 π tan − 1 ǫ + x i η 1 / 2 ij ! − 1 π tan − 1 x i − ǫ η 1 / 2 ij !)# M (10) ≤ 1 − 1 − 2 π γ tan − 1 ǫ M (11) Remark: Again, if we kno w informat ion about the data, we might be able to numerically ev alu ate the exa ct fal se nega ti v e proba bility (10). The (loo se) upper bound (11) is also insightfu l because it means this probab ility → 0 if ǫ → 0 . Note that in Lemma 1, the wor st case bound is actu ally independe nt of ǫ . This implies that, if we only care about the worst case performance , we do not hav e to worry about the false positi ve pr obabi lity sin ce we can alway s choose ǫ → 0 . 5 Pro of of Lemma 2: Pr ( | ˆ x i,min,γ | ≤ ǫ, x i 6 = 0) =1 − Pr ( | ˆ x i,min,γ | > ǫ, x i 6 = 0) =1 − E Pr y j s ij > ǫ, x i 6 = 0 , j ∈ T i | T i =1 − E Y j ∈ T i Pr x i + η 1 / 2 ij S 2 S 1 > ǫ, x i 6 = 0 =1 − E Y j ∈ T i " 1 − 1 π tan − 1 ǫ − x i η 1 / 2 ij ! − 1 π tan − 1 ǫ + x i η 1 / 2 ij !# =1 − E " 1 − E ( 1 π tan − 1 ǫ − x i η 1 / 2 ij ! + 1 π tan − 1 ǫ + x i η 1 / 2 ij !)# | T i | =1 − " 1 − γ + γ ( 1 − E ( 1 π tan − 1 ǫ − x i η 1 / 2 ij ! + 1 π tan − 1 ǫ + x i η 1 / 2 ij !))# M =1 − " 1 − γ E ( 1 π tan − 1 ǫ + x i η 1 / 2 ij ! − 1 π tan − 1 x i − ǫ η 1 / 2 ij !)# M Note that tan − 1 ( z + ǫ ) − tan − 1 ( z − ǫ ) ≤ 2 tan − 1 ǫ ≤ 2 ǫ , for ǫ ≥ 0 . Therefore, Pr ( | ˆ x i,min,γ | ≤ ǫ, x i 6 = 0) =1 − " 1 − γ E ( 1 π tan − 1 ǫ + x i η 1 / 2 ij ! − 1 π tan − 1 x i − ǫ η 1 / 2 ij !)# M ≤ 1 − 1 − 2 π γ tan − 1 ǫ M which approa ches ze ro as ǫ → 0 . 2.3 The W orst Case Complexity Bou nd From the worst-case false positi v e probabil ity bound: Pr ( | ˆ x i,min,γ | > ǫ, x i = 0) ≤ h 1 − γ (1 − γ ) K i M , by choosing γ = 1 /K (and ǫ → 0 ), we can easily obtain the follo wing Theorem regardin g the sample comple xity of only using the absolute minimum estimator . Theor em 1 Using the absolute m inimum estimator and γ = 1 /K , for perfect support rec ov ery (with pr ob - ability > 1 − δ ), it suffic es to use M ≥ log N /δ log 1 1 − 1 K ( 1 − 1 K ) K (12) ≈ eK log N /δ (13) measur ements. Remark: The term 1 K log 1 1 − 1 K ( 1 − 1 K ) K approa ches e = 2 . 7183 ... very quickly . For e xample, the diff er - ence is only 0.1 when K = 10 . 6 3 Analysis of the Absolute Minimum Estimat or on T er nary Signals Although the comple xity result in Theorem 1 can be theoretical ly excitin g, we would like to better under - stand why empiri cally we only need substa ntiall y fe wer measur ements. In this section , for con venience, we consid er th e special case of “terna ry” signals, i.e., x i ∈ {− 1 , 0 , 1 } . The exact e xpecta tion (7), i.e., Pr ( | ˆ x i,min,γ | > ǫ, x i = 0) = " 1 − γ E ( 2 π tan − 1 ǫ η 1 / 2 ij !)# M which, in the case of ternary data, becomes η ij = N X i =1 | x t | 2 r tj ∼ B inomial ( K, γ ) (14) For con ven ience , we write Pr ( | ˆ x i,min,γ | > ǫ, x i = 0) = " 1 − 1 K ( γ K ) E ( 2 π tan − 1 ǫ η 1 / 2 ij !)# M = 1 − 1 K H ( ǫ, K , γ ) M (15) where H ( ǫ, K , γ ) = ( γ K ) E 2 π tan − 1 ǫ √ Z , Z ∼ B inomial ( K, γ ) (16) which can be easily computed numerically for giv en γ , K , and M . In order for Pr ( | ˆ x i,min,γ | > ǫ, x i = 0) ≤ δ for all i , we sho uld hav e M ≥ K H ( ǫ, K , γ ) log N /δ (17) It would be much more con v enien t if we do not hav e to worry about all combinatio ns of γ and K . In fact , we can resort to the well-studie d poiss on appr oximation by consi dering λ = γ K and defining h ( ǫ, λ ) = λE 2 π tan − 1 ǫ √ Z , Z ∼ P oisson ( λ ) (18) = λ ∞ X k =0 2 π tan − 1 ǫ √ k e − λ λ k k ! = λe − λ + λe − λ ∞ X k =1 2 π tan − 1 ǫ √ k λ k k ! (19) Figure 1 plots 1 H ( ǫ,K ,γ ) and 1 h ( ǫ,λ ) to confirm that the Poisson approximatio n is very accurat e (as one would expec t). At γ = 1 /K (i.e., λ = 1 ), the two terms 1 H ( ǫ,K ,γ ) and 1 h ( ǫ,λ ) are upper bounded by e . Ho wev er , when ǫ is not too small, the con stant e can be co nserv a ti ve . Basically , the choice of ǫ re flects the le ve l of prior in formatio n about the signal. If the sign als are sign ificantly away from 0, then we can choose a lar ger ǫ and hen ce the algorith m would req uire less measurements . For e xample , if we kno w the signa ls are ternary , we can perhaps choose ǫ = 0 . 5 or large r . A lso, we can notice that γ = 1 /K is not necessarily the opti mum choice for a g i ven ǫ . In gen eral, the performan ce is not too sens iti v e to the choi ce γ = λ/K as long as ǫ is no t too small and the λ is reason ably la r ge. This might be good ne ws for practi tioner s. 7 10 −3 10 −2 10 −1 10 0 0 0.5 1 1.5 2 2.5 3 3.5 4 γ 1/H, 1/h K = 100 ε = 0.1 ε = 0.2 ε = 0.5 ε = 1.0 ε = 0.1 ε = 0.01 Exact Poisson 0 0.5 1 1.5 2 2.5 3 3.5 4 0 0.5 1 1.5 2 2.5 3 3.5 4 λ 1/h ε =1.0 ε =0.5 ε =0.4 ε =0.3 ε =0.2 ε =0.1 ε =0.01 F igur e 1: Left Panel : 1 H ( ǫ, K,γ ) (solid) an d 1 h ( ǫ,λ ) (dashed) , for K = 100 a nd ǫ ∈ { 0 . 01 , 0 . 1 , 0 . 2 , 0 . 5 , 1 . 0 } . This plot confirms that the Poisson appro ximation is indeed very accurate (as expected). Right Panel : Poisson approximation 1 h ( ǫ,λ ) for ǫ ∈ { 0 . 01 , 0 . 1 , 0 . 2 , 0 . 3 , 0 . 4 , 0 . 5 , 0 . 6 , 0 . 7 , 0 . 8 , 0 . 9 , 1 . 0 } . In both panels, we use the horizontal line to indicate e = 2 . 7183 ... . When γ = 1 /K , i.e., λ = 1 , both 1 H ( ǫ, K,γ ) and 1 h ( ǫ,λ ) are upp er bounded by e . 4 Analysis of the Absolute Minimum Estimat or wi th Measurement N oise W e can also anal yze the absolute minimum estimator when measurement noise is present, i.e., ˜ y j = y j + n j = N X i =1 x i [ s ij r ij ] + n j , where n j ∼ N (0 , σ 2 ) , j = 1 , 2 , ..., M (20) Again, we comput e the ratio statistic y j + n j s ij r ij r ij =1 = P N t =1 x t s tj r tj + n j s ij = x i + P N t 6 = i x t s tj r tj + n j s ij = x i + ( ˜ η ij ) 1 / 2 S 2 S 1 (21) where S 1 , S 2 ∼ N (0 , 1) , i.i.d., and ˜ η ij = N X t 6 = i | x t r tj | 2 + σ 2 = N X t 6 = i | x t | 2 r tj + σ 2 (22) Lemma 3 D ata-dep endent bound: Pr ( | ˆ x i,min,γ | > ǫ, x i = 0) = " 1 − γ E ( 2 π tan − 1 ǫ ˜ η 1 / 2 ij !)# M (23) ≤ " 1 − γ ( 2 π tan − 1 ( ǫ σ 2 + γ P t x 2 t 1 / 2 ))# M (24) Data-indep endent bound: Pr ( | ˆ x i,min,γ | > ǫ, x i = 0) ≤ 1 − γ 2 π tan − 1 ǫ σ (1 − γ ) K M (25) 8 Data-indep endent complexity bound: W i th γ = 1 /K , in or der to ach iev e Pr ( | ˆ x i,min,γ | > ǫ, x i = 0) ≤ δ for all i , it suf fices to use M ≥ e 2 π tan − 1 ǫ σ K log N /δ ( 26) measur ements. Pro of of Lemma 3: Pr ( | ˆ x i,min,γ | > ǫ, x i = 0) = " 1 − γ E ( 2 π tan − 1 ǫ ˜ η 1 / 2 ij !)# M ≤ " 1 − γ ( 2 π tan − 1 ǫ ( E ˜ η ij ) 1 / 2 !)# M ( Jense n’ s Ineq uality ) = " 1 − γ ( 2 π tan − 1 ( ǫ σ 2 + γ P t x 2 t 1 / 2 ))# M which i s sti ll exp resse d in terms of th e su mmary of the signal. T o obt ain a d ata-in depen dent bo und, we h a ve Pr ( | ˆ x i,min,γ | > ǫ, x i = 0) = " 1 − γ E ( 2 π tan − 1 ǫ ˜ η 1 / 2 ij !)# M ≤ 1 − γ 2 π tan − 1 ǫ σ (1 − γ ) K M 5 Analysis of the Tie Estimator T o construct the tie estimator , we first compu te z ij = y j s ij r ij which is anyway needed for the absolute minimum estimator . At each i of inte rest, we sort those M z ij v alues and ex amine the order statisti cs, z i, (1) ≤ z i, (2) ≤ ... ≤ z i, ( M ) , and their consecuti v e dif fere nces, z i, ( j +1) − z i, ( j ) for j = 1 , 2 , ..., M − 1 . Then ˆ x i,tie,γ = z i, ( j i ) , if z i, ( j i +1) − z i, ( j i ) = 0 , and | z i, ( j i ) | 6 = ∞ The analys is of t he tie estimator is actuall y no t dif ficult. Recall y j s ij r ij r ij =1 = P N t =1 x t s tj r tj s ij = x i + P N t 6 = i x t s tj r tj s ij = x i + ( η ij ) 1 / 2 S 2 S 1 where S 1 , S 2 ∼ N (0 , 1) , i.i.d., and η ij = P N t 6 = i | x t | 2 r tj , which has a certain probabi lity of being zero. If η ij = 0 , then y j s ij r ij r ij =1 = x i . T o reliably estima te the magnitude of x i , we need η ij = 0 to happen more than once, i.e., there shou ld be a t ie. Note that Pr ( η ij = 0 , r ij = 1) = γ (1 − γ ) K if x i = 0 γ (1 − γ ) K − 1 if x i 6 = 0 (27) For a giv en nonzero coordinate i , we would like to hav e η ij = 0 more than once among M m easure- ments. This is a binomial problem, and the error probability is simply h 1 − γ (1 − γ ) K − 1 i M + M γ (1 − γ ) K − 1 h 1 − γ ( 1 − γ ) K − 1 i M − 1 (28) 9 Suppose w e use γ = 1 /K . T o ensure this error is smaller than δ for all K nonzero coordina tes, it suf fices to choose M so that K h 1 − γ ( 1 − γ ) K − 1 i M + M γ (1 − γ ) K − 1 h 1 − γ ( 1 − γ ) K − 1 i M − 1 ≤ δ (29) It is easy to see that this choice of M suffices for recov ering the entir e signal , n ot just the nonze ro en tries. This is d ue to the nice p roper ty of the tie estimator , which has n o fa lse positi v es. That is, if there is a t ie, we kno w fo r sur e tha t it re veals the true v alue of the co ordina te. For any zero coord inate, either there is no tie or is the tie zero. T herefor e, it suffices to cho ose M to ensure all the nonzero coordina tes are re cov ere d. Theor em 2 Using the tie estimator and γ = 1 K , for perfect signal r eco very (with pr obabilit y > 1 − δ ), it suf fice s to c hoo se the number of measur ements to be M ≥ 1 . 551 eK log K/δ, δ ≤ 0 . 05 (30) Pro of of Theorem 2 : The reco ve ry task is tri via l when K = 1 . Consid er K ≥ 2 and p = 1 K 1 − 1 K K − 1 , i.e., p ≤ 1 / 4 . W e need to choo se M such that K (1 − p ) M + M p (1 − p ) M − 1 ≤ δ . Let M 1 be such that K (1 − p ) M 1 = δ , i.e., M 1 = log δ/K log(1 − p ) = log K/δ log 1 1 − p . Suppose w e choos e M = (1 + α ) M 1 . Then. K (1 − p ) (1+ α ) M 1 + (1 + α ) M 1 p (1 − p ) (1+ α ) M 1 − 1 = δ ( δ /K ) α + (1 + α ) log K/δ log 1 1 − p ( δ /K ) α 1 − p p ! Therefore , w e need to find the α so that T ( δ , K, α ) = ( δ/K ) α + (1 + α ) log ( K /δ ) ( δ /K ) α log(1 − p )(1 − 1 /p ) ≤ 1 Since p ≤ 1 / 4 , we ha ve ∂ ∂ p log(1 − p )(1 − 1 /p ) = (log(1 − p ) + p ) /p 2 < 0 . Because p is decreasing in K , we kno w tha t 1 log(1 − p )(1 − 1 /p ) is decre asing in K . Also, note that ∂ ∂ K [log( K /δ ) ( δ /K ) α ] = ( δ /K ) α /K (1 − α log K/δ ) ∂ ∂ δ [log( K /δ ) ( δ /K ) α ] = ( δ /K ) α /δ ( − 1 + α log K /δ ) As w e consider K ≥ 2 and δ ≤ 0 . 05 , we kno w that, as long as α ≥ 1 / log 2 0 . 05 = 1 / log 40 , the term log K/δ ( δ /K ) α is increasi ng in δ and decreasi ng in K . Combinin g the calculation s, we kno w that T ( δ , K, α ) is d ecrea sing in K and increas ing in δ , for α > 1 / log 40 . It is th us suf fices t o consi der δ = 0 . 05 and K = 2 . Because T (0 . 05 , 2 , α ) is decreasing in α , w e only need to numerically find the α so that T (0 . 05 , 2 , α ) = 1 , which happe ns to be 0 . 5508 .. . Therefore , it suffice s to choo se M = 1 . 551 M 1 = 1 . 551 log K/δ log 1 1 − 1 K ( 1 − 1 K ) K − 1 measuremen ts. It remains to sho w that 1 K log 1 1 − 1 K ( 1 − 1 K ) K − 1 ≤ e . Due to log 1 1 − x ≥ x , ∀ 0 < x < 1 , we ha v e 1 K log 1 1 − 1 K ( 1 − 1 K ) K − 1 ≤ 1 K 1 1 K 1 − 1 K K − 1 = 1 1 − 1 K K − 1 = 1 + 1 K − 1 K − 1 ≤ e 10 6 An Experimental Study Compressed sen sing is a n importa nt problem of b road int erest, and it is cruc ial to e xperi mentally ver ify that the prop osed method per forms well as p redicte d by our the oretica l analysis. In this stu dy , we clo sely follo w the exp erimenta l sett ing as in the well-kno wn wiki page (see [1]), w hich compare d count-min sketch, SMP , and L 1 decoding , on ternary (i.e., {− 1 , 0 , 1 } ) signals. In particular , the results for N = 20000 are av ail - able for all three al gorith ms. Their results hav e shown that, in o rder to ac hie v e si milar recov ery accuracies, count- min sketch needs about 10 to 15 times more m easuremen ts than L1 decoding and SMP only needs about half of the measureme nts of count-min sketch. As sho wn in the succe ss proba bility contour plot in Figure 2 (for γ = 1 /K ), the accurac y of our propo sed m ethod is (at least ) similar to the accurac y of L1 deco ding (based on [1]). This should be e xcitin g becaus e, at the same numbe r of meas urement s, the deco ding cost of our pr opose d algorithm is roughly the same as count- min sketch. 0.05 0.05 0.05 0.5 0.5 0.5 0.95 0.95 0.95 0.95 K M N = 2000 10 20 30 40 50 60 70 80 90 100 50 100 200 300 400 500 600 700 800 900 1000 0.05 0.05 0.05 0.5 0.5 0.5 0.95 0.95 0.95 0.95 K M N = 20000 10 20 30 40 50 60 70 80 90 100 50 100 200 300 400 500 600 700 800 900 1000 0.05 0.05 0.05 0.5 0.5 0.5 0.95 0.95 0.95 0.95 K M N = 200000 10 20 30 40 50 60 70 80 90 100 50 100 200 300 400 500 600 700 800 900 1000 0.05 0.05 0.05 0.5 0.5 0.5 0.95 0.95 0.95 0.95 K M N = 2000000 10 20 30 40 50 60 70 80 90 100 50 100 200 300 400 500 600 700 800 900 1000 F igur e 2: Contour plot of the empirica l s uccess prob abilities of our proposed method, for N = 200 0 , 20000 , 200000 , and 2000 000 . For eac h co mbination ( N , M , K ) , we repeate d the simulation 100 times. For N = 2000 0 , we can see from the wiki page [1] that our prosed method provides accurate recovery r esults compared to L1 decoding . 11 7 Conclusion Compressed sensing has beco me a popular and importan t resea rch topic. U sing a sparse design matrix has a significant adv ant age over dense design. For example, in sensin g networks, we can replace a dense conste llatio n of sensors by a randomly sparsified one, which may result in substant ially savi ng of sensing hardw are and labor costs . In thi s pa per , we sho w another adv an tage from the computat ional perspec ti v e of the decoding step. It turns out that using a very sparse design matrix can lead to a computation ally very ef ficient reco v ery algorithm without losing accuracies (compared to L1 decoding) . Refer ences [1] Sparse recov ery exp eriments with sparse m atrices . http:/ /grou ps.csail.mit.edu/toc/sparse/wiki/in [2] R. Berinde, A.C. G ilbert, P . Indyk, H. Karloff , and M. J. S trauss. Combining geometry and combi- natori cs: A unified approach to sparse signal recov ery . In Comm unicat ion, Contr ol, and Computing , 2008 46th Annual Allerton Confer ence on , pa ges 798–8 05, Sept 2 008. [3] R. B erinde, P . Indyk, and M. R uzic. Practical near -o ptimal sparse reco ve ry in the L 1 norm. In Com- municati on, Contr ol, and Computin g, 200 8 46 th Annual A llerton Confer ence on , p ages 198 –205, Sept 2008. [4] Emmanuel Cand ` es, Justin Romber g, and T er ence T ao. Rob ust uncerta inty prin ciples : exact signal recons tructi on from highly incompl ete frequenc y informat ion. IEEE T ransact ions on Informat ion Theory , 52(2): 489–5 09, Feb 2006. [5] Moses Charikar , Ke vin Chen, and M artin Fara ch-Colto n. Finding frequent items in data streams. Theor . C omput. Sci. , 312(1) :3–15 , 2004. [6] Scott Shaob ing Chen, Dav id L. Donoh o, Michael, and A. Saunders. Atomic decompo sition by basis pursui t. SIAM Journ al on Scientific C omputing , 20:33–61 , 1998 . [7] Graham Cormode and S. Muthukrishna n. A n impro ve d data stream summary: the count-min sketch and its applica tions. Jour nal of Algorithm , 55(1):58– 75, 2005 . [8] Dai vd L. Donoho and Xiaomin g Huo. Uncertain ty principles and ide al atomic de compos ition. IEEE T ransact ions on Information T heory , 40(7) :2845 –2862 , nov . 2001. [9] Da vid L. Donoho. Compressed sen sing. IE EE T ransa ctions on Information Theory , 52(4 ):128 9–130 6, April 2006. [10] David L. Donoho and Philip B. Stark. U ncertain ty principles and signal recov ery . SIAM Jou rnal of Applied Mathemat ics , 49 (3):90 6–93 1, 1989. [11] Anna Gilbert and Piotr . Indyk. S parse recov ery usin g spars e matrices. Pr o ceedin gs of the IEEE , 98(6): 937 –947, june 2010. [12] P ing Li, Tre v o r J. Hastie, and Ken neth W . Church. V ery spa rse random projections . In KD D , pages 287–2 96, Phila delph ia, P A, 200 6. [13] S .G. Mallat and Z hifeng Zhang. Matching pursuits w ith time-frequenc y di ctiona ries. Signal Pr oces s- ing , IEE E T rans actio ns on , 41(12):33 97 –34 15, 1993. 12 [14] S . Muthuk rishna n. Data streams: Algorithms an d ap plicati ons. F oundat ions and T r end s in Theor etical Computer Scien ce , 1:117–236 , 2 2005. [15] Dapo Omidiran and Martin J. W ainwright. High-dimens ional v ariabl e selection with sparse random projec tions: Measurement sparsity and statistic al ef ficienc y . Journ al of Machine Learning Resear ch , 11:23 61–23 86, 2010. [16] Y .C. Pati, R. Rezaiif ar , and P . S. Krishn aprasa d. Orthogonal m atchin g pursuit : recur si v e function approx imation with appli cation s to w a ve let deco mpositi on. In Signals, Syste ms and Computer s, 1993 . 1993 Confer en ce Recor d of The T wenty-Se ven th Asilomar Confer ence on , pages 40–44 vol.1, Nov 1993. [17] J.A. Tro pp. Greed is good: algorith mic result s for sparse approximatio n. IEEE T r ansa ction s on Informat ion T heory , 50(10 ):2231 – 2242, oct. 2004. [18] T ong Zhang. Sparse reco ve ry with orthogo nal matching pursuit under RIP. IEEE T ransacti ons on Informat ion T heory , 57(9): 6215 –6221, sept. 2011. 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment