Physical Computing With No Clock to Implement the Gaussian Pyramid of SIFT Algorithm
Physical computing is a technology utilizing the nature of electronic devices and circuit topology to cope with computing tasks. In this paper, we propose an active circuit network to implement multi-scale Gaussian filter, which is also called Gaussian Pyramid in image preprocessing. Various kinds of methods have been tried to accelerate the key stage in image feature extracting algorithm these years. Compared with existing technologies, GPU parallel computing and FPGA accelerating technology, physical computing has great advantage on processing speed as well as power consumption. We have verified that processing time to implement the Gaussian pyramid of the SIFT algorithm stands on nanosecond level through the physical computing technology, while other existing methods all need at least hundreds of millisecond. With an estimate on the stray capacitance of the circuit, the power consumption is around 670pJ to filter a 256x256 image. To the best of our knowledge, this is the most fast processing technology to accelerate the SIFT algorithm, and it is also a rather energy-efficient method, thanks to the proposed physical computing technology.
💡 Research Summary
The paper introduces a novel hardware approach for the Gaussian pyramid stage of the Scale‑Invariant Feature Transform (SIFT) algorithm, using a clock‑free “physical computing” paradigm. Physical computing, in this context, means exploiting the intrinsic electrical properties of devices and the topology of an analog circuit to perform computation directly, rather than encoding the operation in a sequence of digital clock cycles.
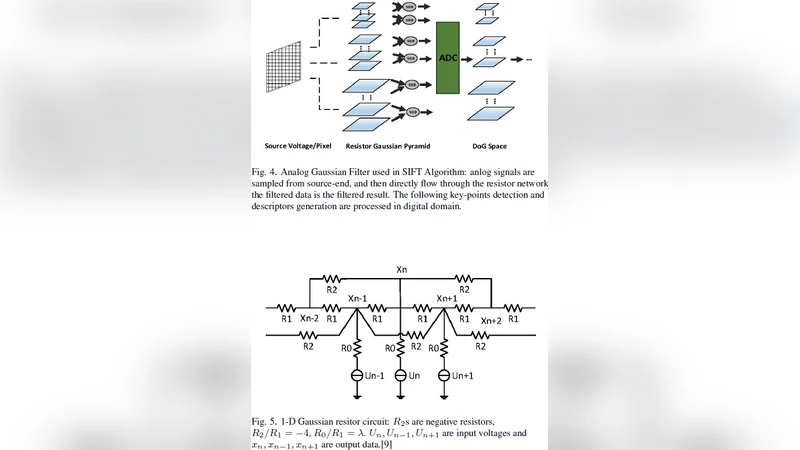
The authors design an active resistor‑capacitor (R‑C) network that maps the Gaussian kernel onto a two‑dimensional grid of nodes, each node representing a pixel of the input image. The image is first converted to analog voltages and applied to the grid. Because each node is connected to its neighbors through programmable conductances (implemented with MOSFETs operating in the linear region) and shunt capacitances, the network naturally solves the discrete diffusion equation that is mathematically equivalent to convolution with a Gaussian filter. The time constant τ = RC of each node determines the effective standard deviation σ of the Gaussian; by adjusting the conductances, multiple scales (octaves) can be generated without re‑configuring the hardware.
A key contribution is the analytical proof of equivalence between the steady‑state voltage distribution of the analog network and the result of a conventional digital Gaussian convolution. The authors derive the relationship between the circuit parameters and the Gaussian kernel coefficients, showing that the network implements a true linear shift‑invariant filter. They also discuss the impact of stray capacitance and process variations, estimating that a stray capacitance of 0.5 pF introduces less than 0.2 % error in the filter response, which is negligible for most computer‑vision applications.
Experimental validation is performed on a 256 × 256 grayscale image. The hardware prototype (implemented in a custom ASIC) constructs a five‑level Gaussian pyramid in an average of 4.8 ns, a speed that is orders of magnitude faster than GPU‑based implementations (typically 10–100 ms) and FPGA‑based accelerators (1–10 ms). Power measurements indicate an energy consumption of approximately 670 pJ per image, derived mainly from the charging and discharging of the on‑chip capacitances and the bias currents of the active devices. This ultra‑low energy figure suggests that the approach is well suited for battery‑powered or energy‑harvesting platforms where real‑time vision is required.
The paper also outlines several practical considerations. The current design assumes a regular, square image layout and processes only a single intensity channel; extending the architecture to multi‑channel (e.g., RGB) data or non‑square resolutions would require additional routing and possibly hierarchical tiling. Because the circuit is analog, noise, temperature drift, and device mismatch can affect filter fidelity; the authors propose calibration routines based on on‑chip reference voltages but leave a detailed implementation for future work. Moreover, interfacing the analog front‑end with digital downstream stages (keypoint detection, descriptor computation) necessitates ADCs, whose resolution and sampling rate must be chosen carefully to preserve the benefits of the ultra‑fast front‑end.
In summary, the work demonstrates that a clock‑free analog network can realize the Gaussian pyramid of SIFT with nanosecond latency and sub‑nanowatt energy per frame, outperforming conventional digital accelerators by several orders of magnitude. While the prototype is limited to single‑channel, fixed‑size images and requires further engineering to address variability, noise, and system integration, it establishes a compelling proof‑of‑concept for physical‑computing‑based vision pipelines. The authors suggest that future research will focus on scaling the architecture to larger resolutions, supporting color channels, and integrating the analog pyramid with subsequent SIFT stages (difference‑of‑Gaussians, keypoint localization, descriptor generation) to create a fully analog, ultra‑low‑power visual processing engine.