Automatic Removal of Marginal Annotations in Printed Text Document
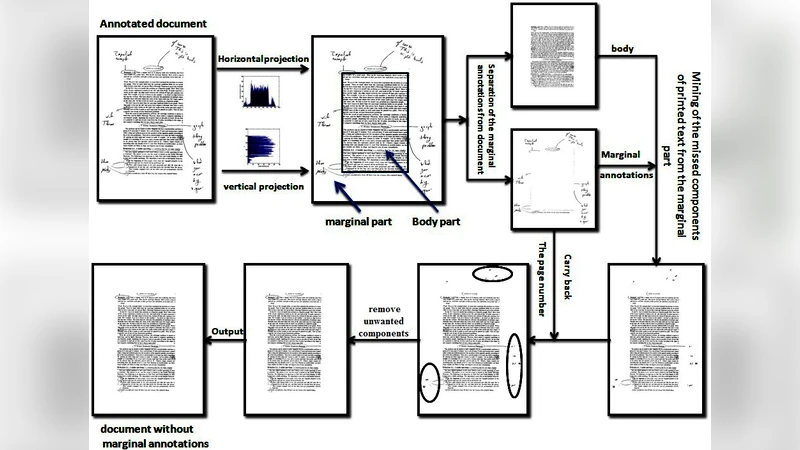
Recovering the original printed texts from a document with added handwritten annotations in the marginal area is one of the challenging problems, especially when the original document is not available. Therefore, this paper aims at salvaging automatically the original document from the annotated document by detecting and removing any handwritten annotations that appear in the marginal area of the document without any loss of information. Here a two stage algorithm is proposed, where in the first stage due to approximate marginal boundary detection with horizontal and vertical projection profiles, all of the marginal annotations along with some part of the original printed text that may appear very close to the marginal boundary are removed. Therefore as a second stage, using the connected components, a strategy is applied to bring back the printed text components cropped during the first stage. The proposed method is validated using a dataset of 50 documents having complex handwritten annotations, which gives an overall accuracy of 89.01% in removing the marginal annotations and 97.74% in case of retrieving the original printed text document.
💡 Research Summary
The paper addresses the problem of automatically removing handwritten marginal annotations from printed documents while preserving the original printed text, a task that becomes especially challenging when the pristine source document is unavailable. The authors propose a two‑stage pipeline. In the first stage, they estimate the marginal region using horizontal and vertical projection profiles derived from a binarized version of the page. By locating abrupt drops in pixel density, they define approximate top, bottom, left, and right margins. All pixels inside this estimated margin—including both handwritten ink and any printed characters that lie close to the margin—are removed. Because this margin detection is deliberately coarse, it inevitably discards some legitimate printed glyphs that are positioned near the edge of the page.
The second stage remedies this loss through connected‑component analysis. After the first stage, the binary image is scanned to label each 8‑connected component. For each component the algorithm extracts geometric features (bounding box, area, aspect ratio) and intensity statistics. Components that are situated within a small tolerance of the previously removed margin, whose size and shape resemble printed characters, and whose average intensity matches that of the surrounding printed text are flagged as “cropped text.” These components are then reinstated into the image, either by copying the original pixel values from the unprocessed source or by interpolating from neighboring pixels when necessary. The authors also employ a simple intensity‑difference test to separate handwritten ink (typically darker or colored) from printed strokes, reducing false positives.
To evaluate the approach, the authors assembled a dataset of 50 real‑world documents spanning academic papers, reports, and letters, each manually annotated with a variety of handwritten notes differing in style, thickness, and color. They measured two primary metrics: (1) marginal‑annotation removal accuracy, defined as the proportion of annotation pixels correctly eliminated, and (2) printed‑text recovery accuracy, defined as the overlap between the restored printed characters and a ground‑truth clean version of the document (using Intersection‑over‑Union and character‑level F1 scores). The system achieved an average annotation‑removal accuracy of 89.01 % and a printed‑text recovery accuracy of 97.74 %. Error analysis revealed that most failures occurred in documents with complex multi‑column layouts, embedded tables, or figures where the marginal region is ambiguous, and in cases where handwritten strokes completely overlapped printed glyphs, making separation impossible with the current heuristic.
The authors discuss the advantages of their method: it is computationally lightweight (projection profiles and connected‑component labeling are linear‑time operations), requires no training data, and can be integrated into existing document‑processing pipelines with minimal effort. They acknowledge limitations, notably the reliance on a fixed intensity threshold and simple geometric heuristics, which may not generalize to colored scans or heavily degraded prints. For future work they propose incorporating deep‑learning‑based semantic segmentation to refine margin detection, extending the approach to handle multi‑page books, and exploring adaptive thresholding that accounts for varying illumination and scan quality. Overall, the paper contributes a practical, high‑accuracy solution for a niche yet important document‑restoration scenario, demonstrating that a well‑designed combination of classical image‑processing techniques can rival more complex machine‑learning approaches for specific, constrained tasks.