Query DAGs: A Practical Paradigm for Implementing Belief Network Inference
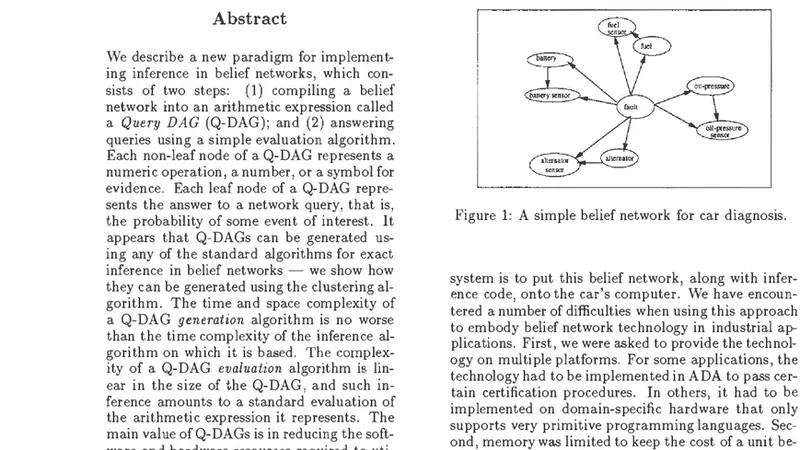
We describe a new paradigm for implementing inference in belief networks, which relies on compiling a belief network into an arithmetic expression called a Query DAG (Q-DAG). Each non-leaf node of a Q-DAG represents a numeric operation, a number, or a symbol for evidence. Each leaf node of a Q-DAG represents the answer to a network query, that is, the probability of some event of interest. It appears that Q-DAGs can be generated using any of the algorithms for exact inference in belief networks — we show how they can be generated using clustering and conditioning algorithms. The time and space complexity of a Q-DAG generation algorithm is no worse than the time complexity of the inference algorithm on which it is based; that of a Q-DAG on-line evaluation algorithm is linear in the size of the Q-DAG, and such inference amounts to a standard evaluation of the arithmetic expression it represents. The main value of Q-DAGs is in reducing the software and hardware resources required to utilize belief networks in on-line, real-world applications. The proposed framework also facilitates the development of on-line inference on different software and hardware platforms, given the simplicity of the Q-DAG evaluation algorithm. This paper describes this new paradigm for probabilistic inference, explaining how it works, its uses, and outlines some of the research directions that it leads to.
💡 Research Summary
The paper introduces a novel implementation paradigm for exact inference in Bayesian networks called Query DAGs (Q‑DAGs). A Q‑DAG is a directed acyclic graph that encodes the entire inference computation as a single arithmetic expression. Non‑leaf nodes represent elementary operations (addition, multiplication), constant numbers, or symbolic placeholders for evidence variables, while leaf nodes correspond to the final query answers – the posterior probabilities of interest. By compiling a Bayesian network into a Q‑DAG once, the online phase reduces to a straightforward evaluation of this arithmetic expression, eliminating the need for repeated message passing or variable elimination each time evidence changes.
The authors demonstrate that any exact inference algorithm can be used as a basis for Q‑DAG generation. They detail two concrete constructions: (1) a clustering‑based method that leverages join‑tree (junction‑tree) structures, and (2) a conditioning‑based method that performs case‑splitting on evidence variables. In the clustering approach, each cluster’s local probability table is transformed into a sub‑expression; the join‑tree’s separators become connections between sub‑expressions, yielding a global Q‑DAG whose size is bounded by the tree‑width of the original network. In the conditioning approach, each conditioning case produces a separate sub‑graph, and common sub‑structures are shared to keep the overall graph compact. The paper proves that the time and space required to generate a Q‑DAG are no worse than the time complexity of the underlying inference algorithm, and that the evaluation of a Q‑DAG is linear in the number of its nodes.
From a practical standpoint, this separation of offline compilation and online evaluation offers several advantages. The evaluation algorithm is extremely simple: after assigning concrete values to the evidence symbols, a single topological traversal computes all intermediate results and finally the query probabilities. This linear‑time evaluation is highly cache‑friendly and can be implemented on devices with very limited CPU and memory resources. Moreover, because the computation graph is static, it maps naturally onto hardware accelerators such as FPGAs or ASICs; only the evidence‑symbol inputs need to be dynamically updated, while the arithmetic circuitry remains fixed. Consequently, Q‑DAGs enable real‑time probabilistic reasoning in embedded systems, medical diagnostic devices, autonomous robots, and other latency‑critical applications.
The authors also discuss limitations and future research directions. The size of a Q‑DAG can grow exponentially with network tree‑width, so techniques for sub‑graph sharing, graph compression, and approximate compilation (e.g., sampling‑based pruning) are essential for scaling to very large models. Extending the paradigm to support dynamic network modifications, incremental updates when new evidence arrives, and hybrid exact‑approximate inference are identified as promising avenues. Additionally, integrating Q‑DAG generation with learning algorithms could allow models to be compiled directly after parameter estimation.
In summary, Query DAGs provide a practical bridge between the theoretical power of exact Bayesian inference and the engineering constraints of real‑world deployment. By front‑loading the computational complexity into an offline compilation step and reducing online inference to a simple arithmetic evaluation, Q‑DAGs dramatically lower software development effort, hardware resource consumption, and runtime latency, thereby broadening the applicability of Bayesian networks in mission‑critical, real‑time systems.