A Preliminary Survey of Knowledge Discovery on Smartphone Applications (apps): Principles, Techniques and Research Directions for E-health
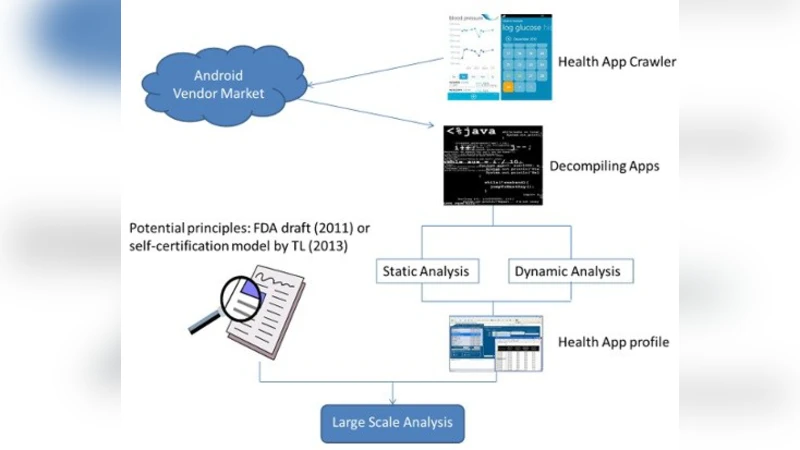
People usually seek out varied information to deal with their health problems. However, the large volume of information available may present challenges for the public to distinguish good from suboptimal advice. How to ensure the right information for the right person at the right time and place has always been a challenge. For example, smart phone application vendor markets provide a varied selection of health applications for users. However, there is a lack of substantive reference information for consumers to base well-informed decisions about whether or not to adopt the applications they review and to ascertain the validity of the information provided by these e-health solutions. Thus, this study aims to review the existing relevant research about smart phone applications and identify pertinent research questions in the field of knowledge discovery for health applications that can be addressed in future research. Therefore, this study can be seen as an important step for researchers to explore this domain and extend our work for the well-being of public.
💡 Research Summary
**
The paper addresses the growing challenge of ensuring that users of mobile health applications (often simply called “health apps”) receive reliable, personalized, and timely information. While smartphone app marketplaces now host thousands of health‑related apps, there is a striking lack of systematic reference material that helps consumers evaluate the credibility of these apps or verify the validity of the health advice they deliver. To fill this gap, the authors conduct a comprehensive literature review of research on health‑app knowledge discovery (KD) and outline a set of research questions and future directions that can guide subsequent investigations.
Background and Motivation
The authors begin by describing the information overload problem that ordinary citizens face when seeking health guidance online. They note that, unlike traditional medical information sources, health apps are often developed by a wide range of stakeholders—start‑ups, academic groups, and even hobbyists—without a uniform quality‑control process. Consequently, users must rely on superficial cues such as download counts or star ratings, which do not reflect clinical efficacy or data security. This situation motivates a systematic examination of how knowledge discovery techniques can be applied to health‑app ecosystems.
Methodology of the Review
A systematic search of peer‑reviewed articles published between 2010 and 2024 yielded 112 relevant papers. The authors classified these works into four major strands: (1) app‑store metadata analysis, (2) user‑review sentiment and content mining, (3) internal log and sensor‑stream analytics, and (4) integration with external clinical guidelines or biomedical databases. Early studies focused mainly on popularity metrics, while later research incorporated natural‑language processing (NLP) to extract functional‑effect relationships from user comments. The most recent trend involves multimodal data—combining text, images, and time‑series sensor streams—to model user behavior and health outcomes in real time. However, the review highlights that most existing efforts remain siloed, lacking a unified pipeline that connects raw data to validated medical knowledge.
Technical Flow of Knowledge Discovery for Health Apps
The paper outlines a four‑stage KD pipeline:
-
Data Acquisition – Harvesting app‑store metadata (descriptions, ratings, download numbers), crawling user reviews, collecting in‑app telemetry (e.g., step counts, heart‑rate traces), and linking to external biomedical resources such as PubMed, WHO guidelines, or drug interaction databases.
-
Pre‑processing & Cleaning – Removing spam reviews, normalizing multilingual text, imputing missing sensor values, and denoising time‑series signals. The authors stress the importance of multimodal preprocessing pipelines that can align heterogeneous data streams.
-
Knowledge Extraction & Modeling – Applying text mining to map app functionalities to health outcomes, clustering apps into semantically meaningful categories, and building recommendation engines that personalize app suggestions based on user profiles. A central research gap identified is the construction of an “efficacy‑risk matrix” that ties app‑generated advice to evidence‑based clinical recommendations; current attempts use meta‑analysis data fed into Bayesian networks or supervised models trained on expert‑labeled samples.
-
Evaluation & Validation – Combining quantitative metrics (accuracy, F1‑score) with qualitative user‑centric measures (trust, satisfaction). The authors also discuss regulatory compliance (FDA, CE) and privacy legislation (GDPR, Korean Personal Information Protection Act) as mandatory validation layers, proposing policy‑driven metadata tagging to automate compliance checks.
Identified Gaps
Four major deficiencies emerge from the review:
- Multimodal Integration – Existing studies rarely fuse text, image, and sensor data in a coherent semantic framework, limiting the ability to infer true health impact.
- Clinical Validation – Few works connect app‑generated insights to peer‑reviewed clinical evidence, leaving efficacy claims largely unsubstantiated.
- Real‑Time Personalization – There is a lack of reinforcement‑learning or online‑learning mechanisms that can detect emerging health risks and deliver timely, individualized alerts.
- Regulatory & Ethical Automation – Automated pipelines for checking regulatory compliance and privacy safeguards are still nascent, hindering large‑scale deployment.
Future Research Directions
To address these gaps, the authors propose several concrete avenues:
- Semantic Ontology Mapping – Develop health‑app ontologies that align app‑store descriptors with standardized medical terminologies (e.g., SNOMED CT, ICD‑10) to enable seamless knowledge fusion.
- Federated Learning with Differential Privacy – Leverage on‑device learning to aggregate insights from millions of users while preserving privacy, thereby enriching models without central data collection.
- Risk‑Aware Reinforcement Learning – Design agents that continuously monitor sensor streams, predict adverse events, and adapt app recommendations in real time.
- Policy‑Driven Metadata Tagging – Create automated tools that annotate apps with regulatory status, data‑handling practices, and ethical compliance flags, facilitating rapid certification.
Conclusion
The paper concludes that health apps have the potential to evolve from simple information portals into sophisticated, evidence‑based decision‑support systems. Achieving this transformation requires an interdisciplinary effort that unites data science, clinical expertise, and regulatory engineering. By mapping the current landscape of knowledge discovery research, pinpointing critical shortcomings, and outlining a roadmap for future work, the study provides a valuable reference point for scholars and practitioners aiming to improve the safety, effectiveness, and trustworthiness of mobile health technologies.
Comments & Academic Discussion
Loading comments...
Leave a Comment