Multi-agents adaptive estimation and coverage control using Gaussian regression
We consider a scenario where the aim of a group of agents is to perform the optimal coverage of a region according to a sensory function. In particular, centroidal Voronoi partitions have to be computed. The difficulty of the task is that the sensory…
Authors: Andrea Carron, Marco Todescato, Ruggero Carli
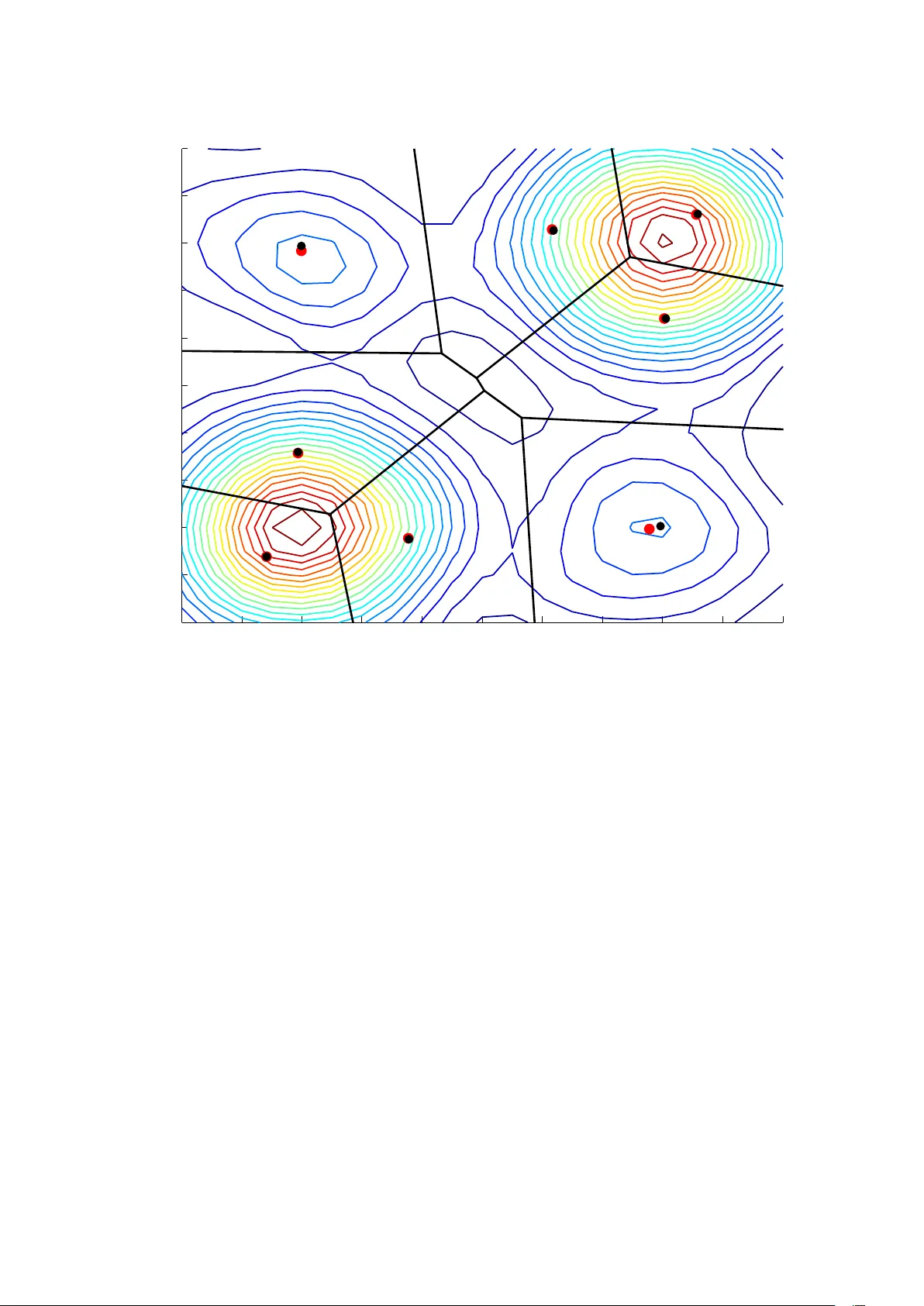
Multi-agents adaptiv e estimation and cov erage contr ol using Gaussian r egr ession Andrea Carron, Marco T odescato, Ruggero Carli, Luca Schenato, Gianluigi Pillonetto Abstract W e consider a scenario where the aim of a group of agents is to perform the optimal cov erage of a region according to a sensory function. In particular , centroidal V oronoi partitions hav e to be computed. The dif ficulty of the task is that the sensory function is unknown and has to be reconstructed on line from noisy measurements. Hence, estimation and coverage needs to be performed at the same time. W e cast the problem in a Bayesian regression framework, where the sensory function is seen as a Gaussian random field. Then, we design a set of control inputs which try to well balance cov erage and estimation, also discussing conv ergence properties of the algorithm. Numerical experiments show the effecti vness of the new approach. I . I N T RO D U C T I O N The continuous progress on hardware and software is allo wing the appearance of compact and relati v ely inexpensi ve autonomous vehicles embedded with multiple sensors (inertial systems, cameras, radars, en vironmental monitoring sensors), high-bandwidth wireless communication and po werful computational resources. While previously limited to military ap- plications, nowadays the use of cooperating vehicles for autonomous monitoring and large environment, ev en for ci vilian applications, is becoming a reality . Although robotics research has obtained tremendous achievements with single vehicles, the trend of adopting multiple vehicles that cooperate to achie ve a common goal is still very challenging and open problem. In particular , an area that has attracted considerable attention for its practical relev ance is the problem of envir onmental partitioning problem and coverage contr ol whose objecti ve is to partition an area of interest into subregions each monitored by a different robot trying to optimize some global cost function that measures the quality of service provided by the monitoring robots. The ”centering and partitioning” algorithm originally proposed by Lloyd [1] and elegantly re viewed in the survey [2] is a classic approach to en vironmental partitioning problems and coverage control problems. The Lloyd algorithm computes Centroidal V oronoi partitions as optimal configurations of an important class of objecti ve functions called cov erage functions. The Lloyd approach was first adapted for distributed coverage in the robotic multiagent literature control in [3]; see also the text [4] (Chapter 5 and literatures notes in Section 5 . 4) for a comprehensive treatment. Since this beginning, similar algorithms have been applied to non-conv ex en vironments [5], [6], to dynamic routing with equitable partitioning [7], to robotic networks with limited anisotropic sensory [8] and to cov erage with communication constraints [9]. Most of the works cited abov e assume that a global sensory cost function is known a priori by each agent. Therefore, the focus is limited to the distributed cov erage control problem. Ho wev er , it is often unrealistic to assume such function to be known. For instance, consider a group of underwater vehicles whose main goal is to monitor areas which present a higher concentration of pollution. The distrib ution of pollution is not known in adv ance, but vehicles are provided with sensors that can take noisy measurements of it. In this context, cov erage control is much harder since the vehicles has to simultaneously explore the environment to estimate pollution distribution and to move to areas with higher pollution concentrations. This is a classical robotic task often referred to as cover age-estimation problem. In [10], an adaptiv e strategy is proposed to solve it but the agents are assumed to take an uncountable number of noiseless measurements. Moreov er , the authors used a parametric approach with the assumption that the true function belongs to such class. More recently , [11] proposed a non parametric approach based on Markov Random Fields for adapti ve sampling and function estimation. This approach has the advantage to provide better approximation of the underlying sensory function as well confidence bounds on the estimate. The nov elty of this work is to consider a Bayesian non parametric learning scheme where, under the frame work of Gaussian regression [12], the unknown function is modeled as a zero-mean Gaussian random field. Robot coordination control is guaranteed to incrementally improve the estimate of the sensory function and simultaneously achiev e asymptotic optimal cov erage control. Although robot motion is generated by a centralized station, this work provides a starting point to design coordination algorithm for simultaneous estimation and cov erage. Note howe ver that the robot to base station communication model adopted in this paper already finds application for ocean gliders interfaces communicating with a tower [13], UA V data mules that periodically visit ground robots [14], or cost-mindful use of satellite or cellular communication. Classical learning problem consists of estimating a function from examples collected on input locations drawn from a fixed probability density function (pdf) [15], [16]. Recent extensions also replace such pdf with a con ver gent sequence of This work is supported by the European Community’ s Seventh Framew ork Programme [FP7/2007-2013] under grant agreement n. 257462 HYCON2 Network of excellence and by the MIUR FIRB project RBFR12M3AC-Learning meets time: a new computational approach to learning in dynamic systems . A. Carron, M. T odescato, R. Carli, L. Schenato, M. T odescato, G. Pillonetto are with the Department of Information Engineering, Uni versity of Padov a, V ia Gradenigo 6/a, 35131 Pado va, Italy { carronan|todescat|carlirug|schenato|giapi } @dei.unipd.it . probability measures [17]. When performing coverage, the stochastic mechanism underlying the input locations establishes how the agents move inside the domain of interest. The peculiarity of our algorithm is that such pdf is allowed to v ary over time, depending also on the current estimate of the function. Hence, agents locations consist of a non Markovian process, leading to a learning problem where stochastic adaption may happen infinitely often (with no guarantee of con vergence to a limiting pdf). Under this complex scenario, we will deriv e conditions that ensure statistical consistency of the function estimator both assuming that the Bayesian prior is correct and relaxing this assumption. In this latter case, we assume that the function belongs to a suitable reproducing kernel Hilbert space and provide a non trivial extension of the statistical learning estimates deriv ed in [16] (technical details are gathered in Appendix). The paper is so organized. After giving some mathematical preliminaries in Section II, problem statement is reported in Section III. The proposed algorithm is presented in Section IV, with its con ver gence propriety discussed in Section V. In Section VI are reported some simulations results. Conclusions then end the paper . I I . M A T H E M AT I C A L P R E L I M I N A R I E S Let X be a compact and con ve x polygon in R 2 an let k · k denote the Euclidean distance function. Let µ : X → R > 0 be a distribution density function defined over X . W ithin the context of this paper , a partition of X is a collection of N polygons W = ( W 1 , . . . , W N ) with disjoint interiors whose union is X . Giv en the list of N points in X , x = ( x 1 , . . . , x N ) , we define the V oronoi partition V ( x ) = { V 1 ( x ) , . . . , V N ( x ) } generated by x as V i ( x ) = q ∈ X | k q − x i k ≤ k q − x j k , ∀ j 6 = i . For each region V i , i ∈ { 1 , . . . , N } , we define its centroid with the respect to the density function µ as c i ( V i ( x )) = Z V i ( x ) µ ( q ) d q − 1 Z V i ( x ) q µ ( q ) d q . W e denote by c ( V ( x )) = ( c 1 ( V 1 ( x )) , . . . , c N ( V N ( x ))) the vector of regions centroids corresponding to the V oronoi partition generated by x = ( x 1 , . . . , x N ) . A partition is said to be a Centroidal V oronoi partition of the pair ( X , µ ) if , for i ∈ { 1 , . . . , N } , the point x i is the centroid of V i ( x ) . Giv en x = ( x 1 , . . . , x N ) and a density function µ we introduce the Covera ge function H ( x ; µ ) defined as H ( x ; µ ) = N ∑ i = 1 Z V i ( x ) k q − c i ( V i ( x )) k 2 µ ( q ) d q For a fixed density function µ , it can be sho wn that the set of local minima H ( x ; µ ) is composed by the points x = ( x 1 , . . . , x N ) are such x 1 , . . . , x N are the centroids of the corresponding regions V 1 ( x ) , . . . , V N ( x ) , i.e, V ( x ) is a Centroidal V oronoi partition. A. Coverage Contr ol Algorithm Let X be a con ve x and closed polygon in R 2 and let µ be a density function defined ov er X . Consider the following optimization problem min x ∈ Q N H ( x ; µ ) . The cover age algorithm we consider is a v ersion of the classic Llo yd algorithm based on ”centering and partitioning” for the computation of Centroidal V oronoi partitions. Given an initial condition x ( 0 ) the algorithm cycles iteratively the following two steps: 1) computing the V oronoi partition corresponding to the current value of x , namely , computing V ( x ) ; 2) updating x to the vector c ( V ( x )) . In mathematical terms, for k ∈ N , the algorithm is described as x ( k + 1 ) = c ( V ( x ( k ))) . (1) It can be shown [3] that the function H ( x ; µ ) is monotonically non-increasing along the solutions of (1) and that all the solutions of (1) con verge asymptotically to the set of configurations that generate centroidal V oronoi partitions. It is well known [3] that the set of centroidal V oronoi partitions of the pair ( X , µ ) are the critical points of the coverage function H ( x ; µ ) . I I I . P RO B L E M F O R M U L AT I ON Let µ : X → R an unknown function modeled as the realization of a zero-mean Gaussian random field with cov ariance K : X × X → R . W e restrict our attention to radial kernels, i.e. K ( a , b ) = h ( k a − b k ) , such that if k a − b k≤k c − d k then h ( k a − b k ) ≤ h ( k c − d k ) and K ( x , x ) = λ , ∀ x ∈ X . Assume we are gi ven a central base-station, and N robotic agents each moving in the space X . The function µ is assumed to be unknown to both the agents and the central unit. Each agent i ∈ { 1 , . . . , N } is required to hav e the following basic computation, communication and sensing capabilities: (C1) agent i can identify itself to the base station and can send information to the base station; (C2) agent i can sense the function µ in the position it occupies; specifically , if x i denotes its current position, it can take the noisy measurement y ( x i ) = µ ( x i ) + ν i , where ν v N ( 0 , σ 2 ) , independent of the unknown function µ , and all mutually independent. The base station must ha ve the following capabilities (C3) it can store all the measurements taken by all the agents; (C4) it can perform computations of partitions of X ; (C5) it can send information to each robot; (C6) it can store an estimate ˆ µ of the function µ and of the posterior variance. The ultimate goal of the group of agents and central base-station is twofold: 1) to explore the en vironment X through the agents, namely , to provide an accurate estimate ˆ µ of the function µ exploiting the measurements taken by the agents; 2) to compute a good partitioning of X using the estimate ˆ µ ,. I V . T H E A L G O R I T H M T o achiev e the above goal the follo wing Estimation + Coverage algorithm (denoted hereafter as EC algorithm) is employed. Algorithm 1 EC Require: The central base station (CBS) stores in memory all the measurements. 1: for k = 1,2,. . . do 2: Measurements collection : For i ∈ { 1 , . . . , N } , agent i takes the measurement y i , k and sends it to CBS. 3: Estimate update : Based on x k , x k − 1 , . . . , x 0 and { y 1 , s , . . . , y N , s } k s = 0 CBS computes ˆ µ k and its posterior . 4: T rajectory update : Based on ˆ µ k CBS computes u k and sends it to agents. Agents update position as x k + 1 = x k + u k . 5: end for Now , introducing the dynamic, we have that for each k ∈ N the central base-station stores in memory a partition W k = ( W 1 , k , . . . , W N , k ) of X , the corresponding list of centroids c k = ( c 1 , k , . . . , c N , k ) , the positions of the robots ( x 1 , k , . . . , x N , k ) and all the measurements receiv ed up to k by the agents. For k ∈ N , agent i , i ∈ { 1 , . . . , N } , moves according to the following first-order discrete-time dynamics x i , k + 1 = x i , k + u i , k where the input u i , k is assigned to agent i by the central base-station. As soon as agent i reaches the new position x i , k + 1 , it senses the function µ in x i , k + 1 taking the measurement y i , k + 1 = µ ( x i , k + 1 ) + ν i , k and it sends y i , k + 1 to the central base-station. The central base-station, based on the new measurements gathered y i , k + 1 N i = 1 and on the past measurements, computes a new estimate ˆ µ k + 1 of µ ; additionally it updates the partition W k , setting W k + 1 = V ( x 1 , k + 1 , . . . , x N , k + 1 ) . The goal is to iterativ ely update the position of the agents in such a way that, in a suitable metric, ˆ µ → µ and the Coverage function assumes values as small as possible. In next subsections we will explain how the central base-station updates the estimate ˆ µ based on the measurements collected from the agents, and how it design the control inputs to driv e the trajectories of the agents. It is quite intuitive that in order to hav e a better and better estimate of the function µ , the measurements have to be taken to reduce as much as possible a functional of the posterior variance, in particular we will adopt the maximum of the posterior variance. T o do so, in the first phase of the EC algorithm the agents will be spurred to explore the environment toward the regions which hav e been less visited. When the error-co variance of the estimate ˆ µ is small enough e verywhere, the central base-station will update the agents’ position to reduce as much as possible the value of the coverage function. T o simplify the notation let us introduce z i , k = { x i , k , y i , k } , i = 1 , . . . , N . One of the ke y aspects of the algorithm is related to the agents movement, which establishes ho w positions x i , k are generated. In particular , as clear in the sequel, each x i , k is a non Markovian process, depending on the whole past history z i , 1 , . . . , z i , k − 1 , i = 1 , . . . , N . It is useful to describe first the function estimator, then detailing the agent dynamics. A. Function estimate and posterior variance Hereby , we use Z N , t to denote the set { z i , k } with i = 1 , . . . , N and k = 1 , . . . , t . The agents movements are assumed to be regulated by probability densities fully defined by Z N , t . It comes that the minimum variance estimate of µ given Z N , t is ˆ µ t ( x ) = E [ µ ( x ) | Z N , t ] = N ∑ i = 1 t ∑ k = 1 c i K ( x i , k , · ) (2) where c 1 . . . c N = ( ¯ K + σ 2 I ) − 1 y 1 , 1 . . . y N , t and ¯ K = K ( x 1 , 1 , x 1 , 1 ) . . . K ( x 1 , 1 , x N , t ) . . . . . . K ( x N , t , x 1 , 1 ) . . . K ( x N , t , x N , t ) . The a posteriori variance of the estimate, in a generic input location x ∈ X , is V ( x ) = V ar [ µ ( x ) | Z N , t ] = K ( x , x ) − K ( x 1 , 1 , x ) . . . K ( x N , t , x ) ( ¯ K + σ 2 I ) − 1 K ( x 1 , 1 , x ) . . . K ( x N , t , x ) . (3) B. Description of agents dynamics The generation of the control input can be divided in two phases: in the first, estimation and coverage are carried out together , while, when the estimate is good enough, i.e. the posterior variance is uniformly small, automatically the control switches to the second phase, where the standard coverage control algorithm revie wed in Section II-A is deployed. 1) Phase I: Let u i , k = ℜ e ( ρ i e j θ i ) ℑ m ( ρ i e j θ i ) i = 1 , . . . , N (4) then the agents dynamics, for i = 1 , . . . , N , are defined by x i , k + 1 = ( x i , k + u i , k if x i , k + u i , k ∈ X x i , k if x i , k + u i , k / ∈ X Hence, variation of the agent’ s position is giv en by the random vector ρ i e j θ i , where θ i is a random variable on [ 0 , 2 π ] , determining the movement’ s direction, while ρ i is another random variable establishing the step length. The peculiarities of our approach are the follo wing ones: • the statistics of ( θ i , ρ i ) vary over time and depend on the past history through the estimate ˆ µ t and a function a ( · ) of the maximum of its posterior variance, i.e. a max x ∈ X V ( x ) . Note that a varies ov er time since it depends on the posterior variance which also varies ov er time as the agents mov e ov er X . Hereby , to simplify notation, we use a ( t ) to stress this dependence. In this way , at ev ery t , a suitable trade-off is established between centroids targeting, which are never perfectly known, being function of µ , and the need of reducing their uncertainty . These two goals are called explor ation and exploitation in [10]; • the probability densities of θ i and ρ i are assumed to be uniformly bounded below . This means that, irrespective of the particular agent’ s position and instant t , there exists ε > 0 such that every set of Lebesgue measure ` > 0 can be reached in one step with probability greater than ` ε . Example 1: W e provide a concrete example by describing the specific update rule adopted during the numerical experi- ments reported in section VI. The random v ariable ρ i is a truncated Gaussian, constrained to assume positi ve values, while θ i is a bimodal Gaussian with support limited to the interval [ 0 , 2 π ] . More specifically , for i = 1 , . . . , N , the density of θ i is p ( θ i ) = 1 − a ( t ) b i ( t ) e − ( θ i − θ C i ( t )) 2 σ 2 C i + a ( t ) c i ( t ) e − ( θ i − θ ∆ i ( t )) 2 σ 2 ∆ i , θ i ∈ [ 0 , 2 π ] 0 , θ i / ∈ [ 0 , 2 π ] where b i ( t ) = Z 2 π 0 e − ( θ i − θ C i ( t )) 2 σ 2 C i d θ i , c i ( t ) = Z 2 π 0 e − ( θ i − θ ∆ i ( t )) 2 σ 2 ∆ i d θ i where • θ C i ( t ) determines the direction to follo w at instant t to reach the current estimate of the V oronoi centroid of the agent i computed using ˆ µ t as defined in (2); • θ ∆ i determines the direction given by the gradient of the posterior v ariance (3) computed at the input location occupied by the i − t h agent at the instant t ; • a ( t ) ∈ [ 0 , 1 ] is a control parameter that establishes the trade-off between exploration and exploitation at instant t . In the next section an automatic way to tune this parameter based on the posterior variance will be presented; • σ 2 C i , σ 2 ∆ i determine the lev el of dispersion of the density around the directions giv en by θ C i and θ ∆ i . A simple heuristic that allows to automatically determine the value of a is based on the maximum of the posterior v ariance, with the constraint that a has to satisfy the following conditions: 1) a ( t ) has to be continuos as function of the maximum of the posterior , 2) a ( t ) has to be monotonically increasing with the maximum of the posterior , 3) if max x ∈ X V ( x ) = λ then a ( t ) = 1 , 4) if max x ∈ X V ( x ) = 0 then a ( t ) = 0. T wo examples are reported in Figure 1. 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 m a x V a r [ µ ( x ) | Z N , t ] a Fig. 1. Here are reported two examples of a(t). In this case the max x ∈ X V ( x ) = λ = 1. At the beginning, being the posterior variance large, a ( t ) will be close to 1 and the agents will just explore the domain. Thanks to the monotonicity of a ( t ) , while the maximum of the posterior will be reduced, also a ( t ) will be reduced and consequently the agents will pri vilege the cov erage. 2) Phase II: When a ( t ) is under a certain threshold, i.e. the posterior variance is uniformly low , the control input switches from the update rule described in section IV -B.1 to u i , k = − ( x i , k − c i , k ) , so the agents will directly reach the estimated centroids. In other words, in this phase the Lloyd’ s algorithm is performed with the unknown function set to the estimate obtained at the end of the first phase. V . C O N V E R G E N C E P RO P E RT I E S O F T H E A L G O R I T H M It is important to verify that (in probability) the posterior variance can be reduced as much as we want. Indeed, this fact implies that (with probability one) the agents dynamics will switch from phase I to phase II. The follo wing result holds. Pr oposition 2: Let µ be a zero-mean Gaussian random field of radial cov ariance K . Then, ∀ ε ≥ 0 , ∀ δ ∈ ( 0 , 1 ] there exists t 0 such that, ∀ t ≥ t 0 , one has: Pr max x ∈ X V ar ( µ ( x ) | Z N , t ) ≤ ε ≥ 1 − δ Pr oof: Consider the following inequality λ − ( λ − α ) 2 λ + σ 2 m ≤ ε . Then, we can always choose a pair ¯ α and ¯ m such that the previous inequality holds. By the continuity of the kernel, there exists a partition, function of ¯ α , giv en by all the subset D j ⊆ X such that K ( x , x ∗ ) ≥ λ − ¯ α , ∀ x , x ∗ ∈ D j . For a sufficiently large t , with a probability greater then 1 − δ , we can collect ¯ m or more measurements in each D j . In fact, ∀ A ⊆ X and ∀ x 1 ∈ X , Pr [ x ( k + 1 ) ∈ A | x ( k ) = x 1 ] ≥ ε ` A , where ` A is the Lebesgue measure of A , since the probability densities of θ i and ρ i are bounded below . Now it is not restrictiv e consider only ¯ m measurements falling in D j , which are denoted by z j 1 , . . . , z j ¯ m and collected on the input locations x j 1 , . . . , x j ¯ m . Calling ¯ K j the sampled kernel in the input location falling in D j and thanks to the fact that T r ( ¯ K j ) = ∑ Λ ( ¯ K j ) = m λ (where Λ ( ¯ K j ) is the set of eigenv alues of ¯ K j ) and that all the eigenv alues of ¯ K j are real and non negati ve ( ¯ K j is symmetric and semi positi ve definite), it holds that ¯ K j ¯ m λ I so that ( ¯ K j + σ 2 ) ( ¯ m λ + σ 2 ) I ⇒ ( ¯ K j + σ 2 ) − 1 ( ¯ m λ + σ 2 ) − 1 I . So with probability greater then 1 − δ it is true that V ar h µ ( x ) | z j i , . . . , z j ¯ m i = K ( x , x ) − h K ( x j 1 , x ) . . . K ( x j ¯ m , x ) i ( ¯ K j + σ 2 I ) − 1 K ( x j 1 , x ) . . . K ( x j ¯ m , x ) ≤ λ − ∑ ¯ m h = 1 K ( x j h , x ) 2 ¯ m λ + σ 2 ≤ λ − ¯ m ( λ − ¯ α ) 2 ¯ m λ + σ 2 = λ − ( λ − ¯ α ) 2 λ + σ 2 ¯ m ≤ ε thus proving the statement. The consequence of Proposition 2 is that with probability one there exists a time ¯ k such that the agents dynamics switch from phase I to phase II, namely the agents dynamics will be rule by x k + 1 = c ( V ( x ( k ))) (5) for k > ¯ k , where the centroids are computed according to the estimate ˆ µ ¯ k . Pr oposition 3: The trajectory generated by 5 conv erges to the set of configurations that generate centroidal V oronoi partitions of the pair ( X , ˆ µ ¯ k ) . V I . N U M E R I C A L R E S U L T S In this section, we provide some simulations implementing the new estimation and cov erage algorithm. W e consider a team of N = 8 agents placed, with a random initial position, in the domain X = [ 0 , 1 ] × [ 0 , 1 ] . Moreov er , we use the Gaussian kernel K ( x , x 0 ) = e − k x − x 0 k 2 0 . 02 with the estimator and the posterior variance giv en by (2) and (3), respecti vely . The unknown sensory function µ is a combination of four bi-dimensional Gaussian: µ ( x ) = 20 e −k x − µ 1 k 2 0 . 04 + e k x − µ 2 k 2 0 . 04 + 5 e − k x − µ 3 k 2 0 . 04 + e − k x − µ 4 k 2 0 . 04 , where µ 1 = 0 . 2 0 . 2 µ 2 = 0 . 8 0 . 8 µ 3 = 0 . 8 0 . 2 µ 4 = 0 . 2 0 . 8 . For computational reasons, the function µ and the posterior variance are ev aluated over a grid of step 0 . 05. The two parameters σ 2 ∆ i and σ 2 C i are both set to 0 . 1 and the threshold that allows to switch from phase I to phase II is equal to 0 . 3. The adopted a ( t ) is as described in Example 1. This means that, when the maximum of the posterior is large, the value of a ( t ) is also large to allow a good estimation. Instead, when the maximum of the posterior variance becomes small, also the value of a ( t ) is reduced to fa vor agents mov ement towards the centroids. An example is in Figure 2 which displays the posterior v ariance (contour plot), the gradient (quiv er plot) and the agents (red diamonds). The figure illustrates results from the first iteration (just because the plot is more clear). 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.6 0.65 0.7 0.75 0.8 0.85 0.9 Fig. 2. Contour plot of the posterior variance with the directions of the gradient. The red diamonds are the agents. Figure 3 plots the profile of the maximum, the av erage and the minimum of the posterior , as a function of the number of iterations. Finally , Figure VI reports the V oronoi regions associated with the agents, as well as the estimated function ˆ µ ( x ) 0 20 40 60 80 100 120 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Iteration Posterior Max Average Min Fig. 3. Evolution of the maximum, the av erage 1 R X d x R X V ( x ) d x and the minimum of the posterior ov er the time. (contour plot). The final agents positions (red circles) are close to the ideal agents positions, computed using the true sensory function µ (black circles). 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Fig. 4. V oronoi regions of the agents with contour plot of the density function. The red circles are the agents positions, the black circles are the centroids positions computed using µ instead of ˆ µ ¯ k . V I I . C O N C L U S I O N S W e hav e proposed a ne w algorithm to perform simultaneously estimation and coverage. The sensory function is seen as a Gaussian random field which has to be reconstructed in an on line manner . A set of control inputs establish the agents mov ement, trying to balance cov erage and estimation. W e have seen that the resulting problem is also an instance of a non standard function learning problem where input locations follow a non Markovian process with stochastic adaption allowed to happen infinitely often. Con ver gence of the estimator has been discussed also assuming that the function prior is not correct (see Appendix). Numerical experiments show good performance. Even if the centralized algorithm finds many applications in dif ferent fields, such as [13] and [14], we are also working on a distrib uted version. The core of the algorithm is based on the on-line non-parametric regression studied in [18]. In addition, we also plan to provide a distrib uted algorithm possibly also accounting for time variance of the sensory function. A P P E N D I X : C O N V E R G E N C E I N R K H S In section IV -B we have seen that the proposed co verage algorithm is divided into two phases. In the first phase, a trade-off between estimation and cov erage is searched for at e very step, while the final coverage step is performed in the second one which starts when the posterior variance is under a certain threshold. Recall that Proposition 2 ensures (in probability) that the second phase will always be reached. This result is obtained under the assumptions that the Bayesian prior on the unknown function is correct. In this Appendix we will relax this assumption, just assuming that the function belongs to the reproducing kernel Hilbert space induced by the covariance K which is thus seen as a reproducing kernel. Our key question is to asses if, in the first phase where input locations follow a very complex non Marko vian process and adaptation may happen infinitely often, the estimate is con ver ging to the true function in some norm. W e will se that the answer is positi ve: under some technical conditions conv ergence (in probability) holds under the RKHS norm (which also implies con vergence in the sup-norm). Dependence of input locations and measurements on the agent number is skipped to simplify notation. Hence, the set of input locations explored by the network and related meaurements av ailable at instant t are denoted by x 1 , . . . , x t and y 1 , . . . , y t , respectiv ely . The following proposition relies on the well known relationship between Bayes estimation of Gaussian random fields and regularization in RKHS. Pr oposition 4: Let H be the RKHS induced by the kernel K : X × X → R , with norm denoted by k · k H . Then, for any x ∈ X , one has ˆ µ t = arg min f ∈ H J ( f ) (6) where J ( f ) = ∑ t k = 1 ( y i − f ( x i )) 2 t + γ k f k 2 H , γ = σ 2 t (7) W e consider a very general framework to describe the process x i , which contains that previously described as special case. The input locations x i are thought of as random vectors each randomly drawn from a Borel nondegenerate probability density function p i ∈ P , with the noise ν t independent of x 1 , . . . , x t for any t . W e do not specify any particular stochastic or deterministic mechanism through which the p i ev olve ov er time. W e just need two conditions regarding the behavior of some covariances and the smoothness of µ , as detailed in the next subsection. A. Assumptions T o state our assumptions, first we need to set up some additional notation. W e use co P to denote the con ve x hull of P , i.e. the smallest con ve x set of densities containing P . Let also L 2 p be the Lebesque space parametrized by the density p , i.e. the space of real functions f : X → R such that k f k 2 p : = Z X f 2 ( a ) p ( a ) d a < ∞ . Our first assumption re gards the decay of the cov ariance between a class of functions e valuated at dif ferent input locations. Assumption 5 (covariances decay): Let f 1 , f 2 be any couple of functions satisfying k f 1 ∨ 2 k p < q < ∞ , ∀ p ∈ co P Then, for ev ery time instant i , there exists a constant A 1 < ∞ , dependent on q but not on f , such that ∞ ∑ k = 0 Cov ( f 1 ( x i ) + f 2 ( x i ) ν i , f 1 ( x i + k )) < A 1 The second assumption is related to smoothness of µ . Below , given a density p , the operator L p : L 2 p → H is defined by L p [ f ]( x ) = Z X K ( x , a ) f ( a ) p ( a ) d a , x ∈ X (8) Assumption 6 (smoothness of the targ et function): There exist constants r , with 1 2 < r ≤ 1, and A 2 < ∞ , such that sup p ∈ co P k L − r p µ k p < A 2 . (9) B. Consistency in RKHS Our main result is reported below . Pr oposition 7: Let Assumptions 5 and 6 hold. In addition, let the regularization parameter γ depend on instant t as follows γ ∝ t − α , 0 < α < 1 2 . (10) Then, as t goes to infinity , one has sup x ∈ X | ˆ µ t ( x ) − µ ( x ) | − → p 0 (11) where − → p denotes conv ergence in probability . Pr oof: W e show that, as t goes to ∞ , the estimator ˆ µ t in (6) conv erges in probability to µ in the topology of H and, hence, in that of the continuous functions. First, some useful notation is introduced. Denote by p 1 , . . . , p t the first t densities selected from P during the first t exploration steps. Note that repetitions can of course be present, e.g. one can have p 1 = p 2 . The average density is ¯ p t ( x ) = ∑ t i = 1 p i ( x ) t . (12) It is useful to indicate with L 2 t the Lebesque space of real functions with norm k f k 2 t : = Z X f 2 ( a ) ¯ p t ( a ) d a < ∞ . Note that, in the description of the space and its norm, the integer t in the subscript replaces ¯ p t . Follo wing this con vention, let also L t [ f ]( x ) = Z X K ( x , a ) f ( a ) ¯ p t ( a ) d a , x ∈ X (13) The following function plays a key role in the subsequent analysis: ¯ µ t = arg min f ∈ H k f − µ k 2 L 2 t + γ k f k 2 H (14) Note that, dif ferently from the data-free limit function introduced in [16, eq. 2.1], here ¯ µ t is a (possibly random) time-v arying function, depending on the time instant t . One has k ˆ µ t − µ k H ≤ k ¯ µ t − µ k H + k ˆ µ t − ¯ µ t k H (15) W e start analyzing the first term on the RHS of (15). The average density ¯ p t varies ov er time but nev er escapes from co P . Then, combining Assumption 6 and eq. (3.11) in [16], one obtains the following bound uniform in t : k ¯ µ t − µ k H ≤ γ r − 1 2 k L − r t µ k t ≤ γ r − 1 2 A 2 (16) Now , we study E k ˆ µ t − ¯ µ t k H , i.e. the expectation of the second term on the RHS of (15). Despite the complex nature of ¯ µ t , we can apply the same arguments introduced in the first part of Section 2 of [16] which, combined with definitions (12,13), lead to the equalities γ ¯ µ t = L t [ µ − ¯ µ t ] = 1 t t ∑ i = 1 L p i [ µ − ¯ µ t ] as well as to the following inequality E k ˆ µ t − ¯ µ t k H ≤ 1 γ E " 1 t t ∑ i = 1 (( y i − ¯ µ t ( x i )) K ( x i , · ) − L p i [ µ − ¯ µ t ]( · )) H # T o gain further insight on the above expression, first consider E 1 t t ∑ i = 1 (( y i − ¯ µ t ( x i )) K ( x i , · ) − L p i [ µ − ¯ µ t ]( · )) 2 H (18) Using the Mercer theorem, we can al ways find real and positi ve eigen values λ j and related eigenfunctions φ j , e.g. orthonormal w .r .t. the classical Lebesgue measure on X , such that K ( x i , · ) = ∞ ∑ j = 1 λ j φ j ( x i ) φ j ( · ) Then, one has ( y i − ¯ µ t ( x i )) K ( x i , · ) = ∞ ∑ j = 1 ( y i − ¯ µ t ( x i )) λ j φ j ( x i ) φ j ( · ) = ∞ ∑ j = 1 a j ( x i ) λ j φ j ( · ) where we have used the following correspondence a j ( x i ) = ( µ ( x i ) + ν i − ¯ µ t ( x i )) φ j ( x i ) Now , simple calculations show that E [( y i − ¯ µ t ( x i )) K ( x i , · )] = L p i [ µ − ¯ µ t ]( · ) = ∞ ∑ j = 1 E [ a j ( x i )] λ j φ j ( · ) Using RKHS norm’ s structure, (18) can now be re written as follows 1 t 2 E t ∑ i = 1 ∞ ∑ j = 1 ( a j ( x i ) − E [ a j ( x i )]) λ j φ j ( · ) 2 H = E " t ∑ i = 1 t ∑ k = 1 ∞ ∑ j = 1 λ j t 2 ( a j ( x i ) − E [ a j ( x i )]) ( a j ( x k ) − E [ a j ( x k )]) # W e now obtain an upper bound on the first term present in the rhs of the above equation. First, taking f = 0 in the objectiv e in (14), one has k ¯ µ t − µ k t ≤ k µ k t ≤ sup p ∈ co P k µ k p < ` 1 < ∞ . where the last inequality deriv es from continuity of the function µ on the compact X . In addition, φ j are all contained in a ball of the space of continuous functions, say of radius ` 2 . 1 This leads to the follo wing bound, uniform in m and j : k a j k t ≤ ` 1 ` 2 . The above inequality permits to exploit Assumption 5 to obtain 1 t 2 E " t ∑ i = 1 t ∑ k = 1 ∞ ∑ j = 1 λ j ( a j ( x i ) − E [ a j ( x i )]) ( a j ( x k ) − E [ a j ( x k )]) # ≤ ∞ ∑ j = 1 λ j t 2 t ∑ i = 1 t ∑ k = 1 E [( a j ( x i ) − E [ a j ( x i )]) ( a j ( x k ) − E [ a j ( x k )])] ≤ 2 A 1 ∑ ∞ j = 1 λ j t where, in virtue of the Mercer theorem, ∑ ∞ j = 1 λ j < ∞ (recall, in fact, that each L p induced by K , with p e.g. the uniform distribution on X , is a trace class operator). This last result, together with the Jensen’ s inequality , leads to E [ k ˆ µ t − ¯ µ t k H ] ≤ q 2 A 1 ∑ ∞ j = 1 λ j γ √ m . (21) Combining (21) with (15) and (16), we obtain E [ k ˆ µ t − µ k H ] ≤ γ r − 1 2 A 2 + q 2 A 1 ∑ ∞ j = 1 λ j γ √ m and this completes the proof. R E F E R E N C E S [1] S. P . Lloyd, “Least-squares quantization in pcm, ” IEEE T ransactions on Information Theory , vol. 28, pp. 129–137, 1982. [2] Q. Du, V . Faber , and M. Gunzburger , “Centroidal v oronoi tessellations: Applications and algorithms, ” SIAM Re view , vol. 41, pp. 637–676, 1999. [3] J. Cortes, S. Martinez, T . Karatas, and F . Bullo, “Coverage control for mobile sensing networks, ” Automatica , vol. 20, no. 2, pp. 243–255, 2004. [4] F . Bullo, J. Cortes, and S. Martinez, Distributed Control of Robotic Networks . Applied Mathematics Series, Princenton University Press, 2009. [5] M. Zhong and C. G. Cassandras, “Distributed coverage control in sensor network en vironments with polygonal obstacles, ” in IF A C W orld Congress , 2008, pp. 4162–4167. [6] L. C. A. Pimenta, V . Kumar, R. C. Mesquita, and G. A. S. Pereira, “Sensing and coverage for a network of heterogeneous robots, ” in IEEE Confer ence on Decision and Contr ol , 2008, pp. 3947–3952. [7] O. Baron, O. Berman, D. Krass, and Q. W ang, “The equitable location problem on the plane, ” European Journal of Operational Researc h , vol. 183, no. 2, pp. 578–590, 2007. [8] K. Laventall and J. Cortes, “Cov erage control by multi-robot networks with limited range anisotropic sensory , ” International Journal of Control , vol. 86, no. 6, 2009. [9] F . Bullo, R. Carli, and P . Frasca, “Gossip cov erage control for robotic networks : dynamical systems on the space of partitions, ” SIAM Journal on Contr ol and Optimization , vol. 50, no. 1, 2012. [10] M. Schwager , D. Rus, and J.-J. Slotine, “Decentralized, adaptive coverage control for networked robots, ” Int. J. Rob . Res. , vol. 28, no. 3, pp. 357–375, Mar . 2009. [11] J. Choi and R. Horowitz, “Learning coverage control of mobile sensing agents in one-dimensional stochastic en vironments, ” Automatic Contr ol, IEEE T ransactions on , vol. 55, no. 3, pp. 804–809, March 2010. [12] C. Rasmussen and C. W illiams, Gaussian Processes for Machine Learning . The MIT Press, 2006. [13] A. Pereira, H. Heidarsson, C. Oberg, D. A. Caron, B. Jones, G. S. Sukhatme, A. Pereira, C. Oberg, and G. S. Sukhatme, “ A communication framework for cost-ef fectiv e operation of auvs in coastal regions, ” in In The 7th International Confer ence on Field and Service Robots , 2009. [14] R. Shah, S. Roy , S. Jain, and W . Brunette, “Data mules: modeling a three-tier architecture for sparse sensor networks, ” in Sensor Network Pr otocols and Applications, 2003. Pr oceedings of the Fir st IEEE. 2003 IEEE International W orkshop on , May 2003, pp. 30–41. [15] T . Poggio and F . Girosi, “Networks for approximation and learning, ” in Proceedings of the IEEE , vol. 78, 1990, pp. 1481–1497. 1 This holds for the Gaussian kernel and, in practice, also for e very covariance adopted in the literature, e.g. spline, Laplacian and polynomial kernels. [16] S. Smale and D. Zhou, “Learning theory estimates via integral operators and their approximations, ” Constructive Appr oximation , vol. 26, pp. 153–172, 2007. [17] ——, “Online learning with markov sampling, ” Analysis and Applications , vol. 07, no. 01, pp. 87–113, 2009. [18] D. V aragnolo, G. Pillonetto, and L. Schenato, “Distributed parametric and nonparametric regression with on-line performance bounds computation, ” Automatica , vol. 48, no. 10, pp. 2468 – 2481, October 2012.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment