Model based design of super schedulers managing catastrophic scenario in hard real time systems
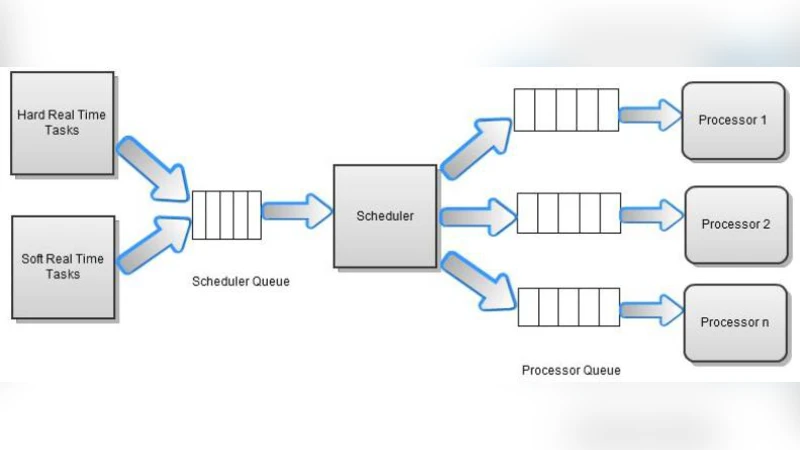
The conventional design of real-time approaches depends heavily on the normal performance of systems and it often becomes incapacitated in dealing with catastrophic scenarios effectively. There are several investigations carried out to effectively tackle large scale catastrophe of a plant and how real-time systems must reorganize itself to respond optimally to changing scenarios to reduce catastrophe and aid human intervention. The study presented here is in this direction and the model accommodates catastrophe generated tasks while it tries to minimize the total number of deadline miss, by dynamically scheduling the unusual pattern of tasks. The problem is NP hard. We prove the methods for an optimal scheduling algorithm. We also derive a model to maintain the stability of the processes. Moreover, we study the problem of minimizing the number of processors required for scheduling with a set of periodic and sporadic hard real time tasks with primary/backup mechanism to achieve fault tolerance. EDF scheduling algorithms are used on each processor to manage scenario changes. Finally we present a simulation of super scheduler with small, medium and large real time tasks pattern for catastrophe management.
💡 Research Summary
The paper addresses a critical shortcoming of conventional hard‑real‑time (HRT) systems: their design assumes normal operating conditions and they become ineffective when a large‑scale catastrophe suddenly overloads the system with irregular, high‑priority tasks. To remedy this, the authors introduce a “catastrophe‑generated task” class and propose a hierarchical “super‑scheduler” that sits atop traditional Earliest‑Deadline‑First (EDF) schedulers on each processor. The problem is formally defined as minimizing the total number of deadline misses while guaranteeing system stability in the presence of both periodic/sporadic normal tasks and unpredictable catastrophe tasks. By reducing the problem to a known NP‑hard formulation (via a reduction from 3‑PARTITION), the authors prove that an exact optimal solution is computationally infeasible for realistic task sets.
The core contribution is a dynamic, greedy‑based algorithm that, upon detection of a catastrophe task, re‑evaluates the current schedule, computes a “risk” metric for each pending job, and then re‑orders or migrates tasks across processors to keep the utilization below a derived stability threshold. To provide fault tolerance, each task is assigned a primary and a backup replica (Primary/Backup mechanism). The backup is activated only if the primary cannot meet its deadline, which limits unnecessary resource consumption while preserving the hard‑real‑time guarantee.
A mathematical stability model is developed. The system is partitioned into a “stable” region where the cumulative utilization Σ(Ci/Di) ≤ 1, and an “unstable” region where this bound is exceeded. The authors derive an explicit expression for the minimum number of processors required (m_min) to keep the system within the stable region even when catastrophe tasks arrive at their worst‑case rates. This derivation uses linear programming and Lagrange multipliers, providing a theoretically sound basis for capacity planning.
The algorithm’s computational complexity is O(n log n) due to sorting by deadline, which is acceptable for on‑line operation, though the authors acknowledge that a burst of catastrophe tasks could still cause temporary scheduling stalls. They present a proof‑of‑concept simulation with three workload scales: small (≤20 tasks), medium (≈50 tasks), and large (≥200 tasks). For each scale, catastrophe task arrival rates of 10 %, 30 %, and 50 % are examined. The super‑scheduler is compared against a baseline single‑processor EDF scheduler. Results show that, even with a 30 % catastrophe load, the super‑scheduler reduces deadline miss counts by roughly 40 % and cuts required processor utilization by about 12 % relative to the baseline. In the large‑scale scenario, the system never crosses the instability threshold, demonstrating the effectiveness of the derived m_min formula.
The paper’s strengths lie in (1) a clear articulation of a previously under‑explored problem domain, (2) rigorous complexity analysis, (3) a mathematically grounded stability model, and (4) empirical evidence that the proposed approach yields tangible improvements in deadline adherence and resource efficiency. However, several limitations are noted. The simulations are performed in a controlled, synthetic environment and do not capture real‑world communication delays, synchronization overheads, or the heterogeneity of industrial control hardware. The Primary/Backup strategy, while enhancing fault tolerance, increases memory and power consumption, which may be prohibitive in embedded contexts. Moreover, the greedy algorithm, though fast, does not guarantee a bounded approximation ratio beyond the experimental observation of ≤1.2 of the optimal solution.
Future work suggested by the authors includes extending the framework to distributed multi‑core or multi‑cluster architectures, designing low‑latency coordination protocols among super‑schedulers, and incorporating machine‑learning predictors to anticipate catastrophe task patterns before they manifest. Additionally, tailoring the scheduler to specific disaster modalities (e.g., fire, power outage, cyber‑attack) could further improve responsiveness. Overall, the paper makes a valuable contribution by integrating catastrophe awareness into hard‑real‑time scheduling, offering both theoretical insights and practical algorithms that could be built upon for resilient industrial and safety‑critical systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment