XML Matchers: approaches and challenges
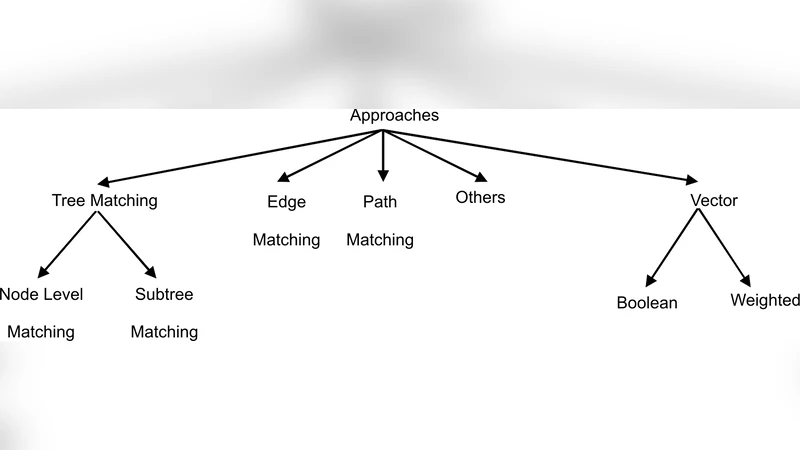
Schema Matching, i.e. the process of discovering semantic correspondences between concepts adopted in different data source schemas, has been a key topic in Database and Artificial Intelligence research areas for many years. In the past, it was largely investigated especially for classical database models (e.g., E/R schemas, relational databases, etc.). However, in the latest years, the widespread adoption of XML in the most disparate application fields pushed a growing number of researchers to design XML-specific Schema Matching approaches, called XML Matchers, aiming at finding semantic matchings between concepts defined in DTDs and XSDs. XML Matchers do not just take well-known techniques originally designed for other data models and apply them on DTDs/XSDs, but they exploit specific XML features (e.g., the hierarchical structure of a DTD/XSD) to improve the performance of the Schema Matching process. The design of XML Matchers is currently a well-established research area. The main goal of this paper is to provide a detailed description and classification of XML Matchers. We first describe to what extent the specificities of DTDs/XSDs impact on the Schema Matching task. Then we introduce a template, called XML Matcher Template, that describes the main components of an XML Matcher, their role and behavior. We illustrate how each of these components has been implemented in some popular XML Matchers. We consider our XML Matcher Template as the baseline for objectively comparing approaches that, at first glance, might appear as unrelated. The introduction of this template can be useful in the design of future XML Matchers. Finally, we analyze commercial tools implementing XML Matchers and introduce two challenging issues strictly related to this topic, namely XML source clustering and uncertainty management in XML Matchers.
💡 Research Summary
The paper provides a comprehensive survey of XML‑specific schema matching techniques, which the authors term “XML Matchers.” While schema matching has long been studied for traditional data models such as ER diagrams and relational schemas, the widespread adoption of XML in domains ranging from bio‑informatics to e‑commerce has motivated the development of approaches that exploit the particular features of DTDs and XSDs. The authors first examine how XML schemas differ from other models: they contain hierarchical structures, namespaces, complex types, and richer datatype information, all of which can be leveraged to improve matching quality but also introduce new challenges.
The central contribution is the introduction of an “XML Matcher Template,” a modular framework that decomposes any XML matching system into six logical components: (1) preprocessing – conversion of DTD/XSD into tree or graph representations, normalization of names, resolution of namespaces, and datatype mapping; (2) element extraction – gathering labels, datatypes, cardinalities, defaults, etc.; (3) relationship modeling – capturing parent‑child, sibling, reference, and inheritance links; (4) similarity computation – applying multiple similarity measures (string‑based, lexical/semantic, structural, and instance‑based) to generate raw scores for element pairs; (5) aggregation – merging the heterogeneous scores using weighted linear combinations, Bayesian fusion, or learned meta‑models; and (6) selection – applying thresholds, conflict resolution, and optimal matching algorithms (e.g., Hungarian, max‑flow) to produce the final set of mappings with confidence values.
The template is then used to analyze a number of well‑known XML Matchers such as XMatch, COMA++, iMAP, and YAM. For each system the authors map its concrete implementation to the template’s stages, highlighting commonalities (e.g., use of Levenshtein distance) and differentiators (e.g., graph‑based structural similarity, use of external ontologies). This systematic comparison demonstrates that despite superficial differences, most XML Matchers share a similar architectural backbone, which the template makes explicit.
The survey also reviews commercial tools (Altova MapForce, Stylus Studio, IBM InfoSphere, etc.), classifying them according to the same template and discussing their practical strengths and limitations in real‑world integration projects.
Finally, two emerging research challenges are identified. The first is XML source clustering: with the explosion of publicly available XML schemas, it becomes infeasible to match every pair individually. Clustering techniques—feature‑vector K‑means, hierarchical agglomeration, graph‑based community detection, and topic‑model approaches—can group similar schemas, enabling batch matching and domain‑specific optimizations. The second challenge is uncertainty management. Matching results are often probabilistic; the authors argue for explicit modeling of confidence using Bayesian networks, Markov random fields, or fuzzy matching, and for mechanisms that incorporate user feedback or additional data to iteratively refine the uncertainty estimates.
In conclusion, the paper positions the XML Matcher Template as a unifying lens for both academic research and industrial development, facilitating clearer comparison, reuse of components, and systematic progress on open problems such as large‑scale clustering and robust handling of uncertainty.
Comments & Academic Discussion
Loading comments...
Leave a Comment