Bandits Warm-up Cold Recommender Systems
We address the cold start problem in recommendation systems assuming no contextual information is available neither about users, nor items. We consider the case in which we only have access to a set of ratings of items by users. Most of the existing works consider a batch setting, and use cross-validation to tune parameters. The classical method consists in minimizing the root mean square error over a training subset of the ratings which provides a factorization of the matrix of ratings, interpreted as a latent representation of items and users. Our contribution in this paper is 5-fold. First, we explicit the issues raised by this kind of batch setting for users or items with very few ratings. Then, we propose an online setting closer to the actual use of recommender systems; this setting is inspired by the bandit framework. The proposed methodology can be used to turn any recommender system dataset (such as Netflix, MovieLens,…) into a sequential dataset. Then, we explicit a strong and insightful link between contextual bandit algorithms and matrix factorization; this leads us to a new algorithm that tackles the exploration/exploitation dilemma associated to the cold start problem in a strikingly new perspective. Finally, experimental evidence confirm that our algorithm is effective in dealing with the cold start problem on publicly available datasets. Overall, the goal of this paper is to bridge the gap between recommender systems based on matrix factorizations and those based on contextual bandits.
💡 Research Summary
The paper tackles the cold‑start problem in recommender systems under the strict assumption that no side information about users or items is available; only a set of observed ratings (or implicit feedback) can be used. Traditional approaches treat recommendation as a batch matrix‑factorization problem, minimizing RMSE on a static training set. The authors argue that this formulation suffers from several fundamental drawbacks: it treats all rating errors equally regardless of their magnitude, it cannot provide predictions for newly arriving users or items, and it ignores the temporal order and the cost of exploration.
To overcome these issues, the authors recast recommendation as an online sequential decision‑making problem, specifically a multi‑armed bandit (MAB) setting. In this view each user–item pair can be considered an arm, and pulling an arm yields a stochastic reward equal to the observed rating (or click). Unlike classic MAB problems with a fixed small number of arms, recommender systems continuously add new users and items, so the arm set is dynamic and potentially very large.
The core contribution is a novel algorithm that bridges low‑rank matrix factorization and contextual bandits. The latent factor vectors obtained from matrix factorization are used as context vectors for each arm. The algorithm follows a LinUCB‑style Upper Confidence Bound (UCB) policy: at each time step t, for a given user i the score of item j is
(\hat{U}_i \cdot \hat{V}_j^\top + \alpha \sqrt{v_j A_i^{-1} v_j^\top})
where (\hat{U}_i) and (\hat{V}_j) are the current estimates of the user and item latent vectors, (v_j = \hat{V}_j) serves as the context, (A_i) is the accumulated design matrix for user i, and (\alpha) controls the exploration level. The first term exploits the current estimate of expected reward, while the second term encourages exploration of items with high uncertainty.
The algorithm proceeds online: (1) when a new user or item appears, a few random recommendations are made to collect initial feedback; (2) all observed feedback is used to update the latent factor matrices via stochastic gradient descent or alternating least squares; (3) the UCB score is recomputed and the next item is selected; (4) the observed rating is fed back into the model immediately. This loop runs continuously, allowing the factorization to adapt as more data arrive.
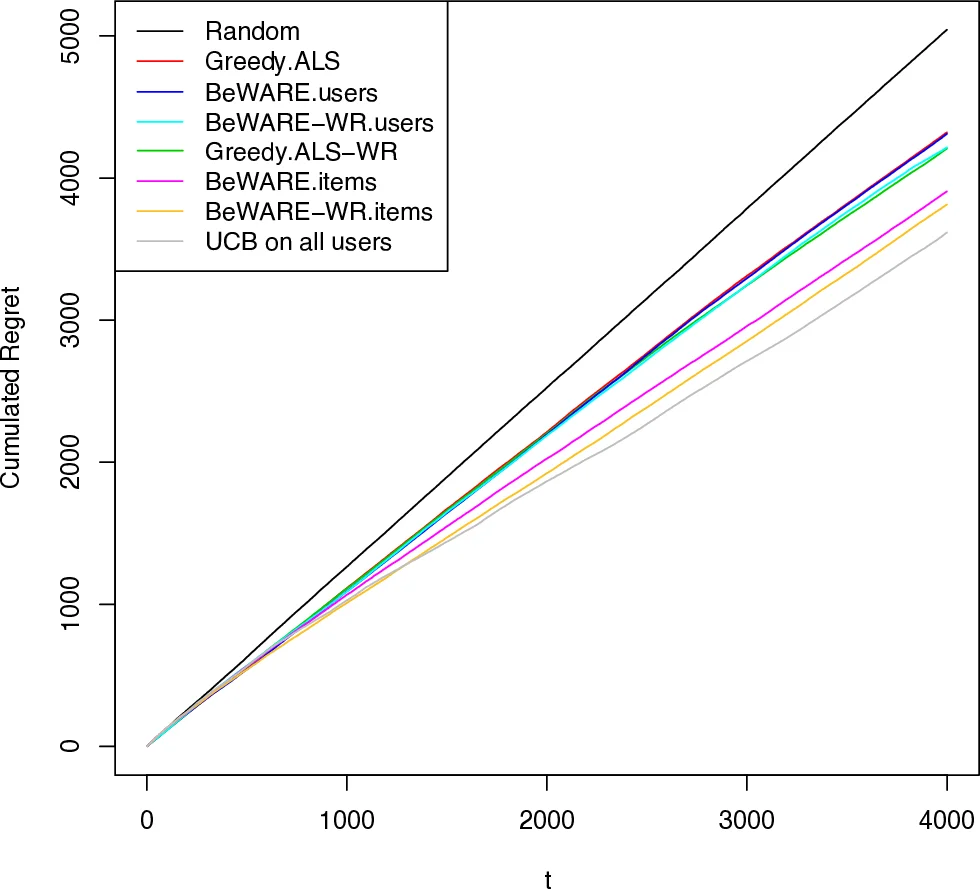
Experimental evaluation is performed on both synthetic data (where the true latent dimension and noise level are controlled) and real‑world datasets (MovieLens and Netflix). The proposed method is compared against standard batch matrix factorization, PureUCB, and LinUCB baselines. Results show that the new algorithm achieves higher cumulative reward and lower initial RMSE, especially during the early interactions with cold users or items. The method quickly reduces the error after only a few recommendations, demonstrating effective exploration without sacrificing overall accuracy.
Beyond the immediate results, the paper discusses extensions: incorporating side information (user demographics, item content) into the context vectors, handling multiple objectives such as diversity or fairness, and scaling to massive item catalogs. By unifying matrix factorization with contextual bandits, the work provides a principled framework for online recommendation under uncertainty and opens several avenues for future research and practical deployment.
Comments & Academic Discussion
Loading comments...
Leave a Comment