What you need to know about the state-of-the-art computational models of object-vision: A tour through the models
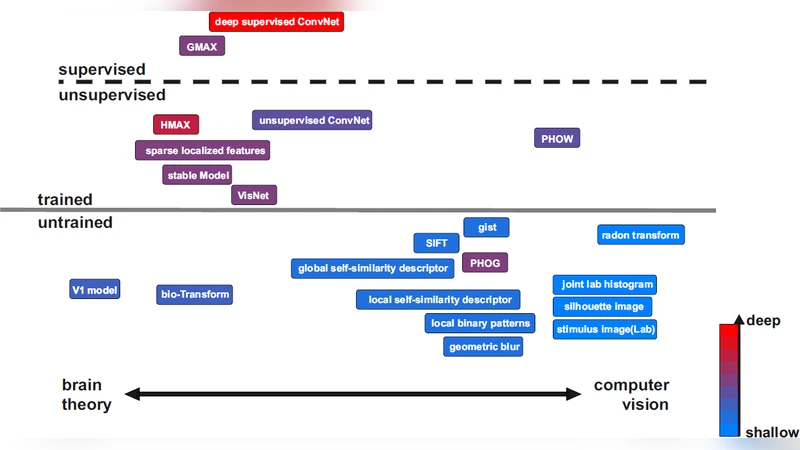
Models of object vision have been of great interest in computer vision and visual neuroscience. During the last decades, several models have been developed to extract visual features from images for object recognition tasks. Some of these were inspired by the hierarchical structure of primate visual system, and some others were engineered models. The models are varied in several aspects: models that are trained by supervision, models trained without supervision, and models (e.g. feature extractors) that are fully hard-wired and do not need training. Some of the models come with a deep hierarchical structure consisting of several layers, and some others are shallow and come with only one or two layers of processing. More recently, new models have been developed that are not hand-tuned but trained using millions of images, through which they learn how to extract informative task-related features. Here I will survey all these different models and provide the reader with an intuitive, as well as a more detailed, understanding of the underlying computations in each of the models.
💡 Research Summary
The paper provides a comprehensive survey of computational models of object vision, tracing their evolution from early hand‑engineered feature extractors to today’s massive, data‑driven deep networks. It begins by framing the field within the hierarchical organization of the primate visual system, noting that many models have been inspired by the progression from simple edge detectors in V1 to complex object representations in higher visual areas. The authors then introduce a three‑axis taxonomy: (1) training regime (supervised, unsupervised/self‑supervised, or no training), (2) architectural depth (shallow versus deep hierarchies), and (3) degree of biological inspiration (hard‑wired versus learned).
The first major category covered is the class of hard‑wired, non‑learning models. Classic examples such as Gabor filters, Scale‑Invariant Feature Transform (SIFT), Histogram of Oriented Gradients (HOG), and the hierarchical HMAX model are described in detail. These systems rely on manually designed kernels that capture low‑level statistics (edges, corners, textures) and, in the case of HMAX, a limited number of hierarchical stages that loosely mimic V1‑V4 processing. Their strengths lie in computational efficiency, interpretability, and suitability for low‑power or embedded platforms, but they struggle with large intra‑class variability and high‑level semantic reasoning.
The second category comprises fully supervised deep learning models. The survey walks through the historical milestones—from AlexNet’s breakthrough in 2012, through VGG’s uniform deep stacks, GoogLeNet’s inception modules, ResNet’s residual connections, to densely connected DenseNet and modern EfficientNet designs. For each architecture the authors explain the core innovations (e.g., small‑kernel stacking, multi‑branch pathways, identity shortcuts) and how they address issues such as vanishing gradients, parameter redundancy, and computational cost. The paper emphasizes that these models achieve state‑of‑the‑art performance on benchmarks like ImageNet, COCO, and Pascal VOC, but they require massive labeled datasets, extensive GPU resources, and remain largely opaque in terms of internal representations. Transfer learning, fine‑tuning, and model compression (pruning, quantization, knowledge distillation) are discussed as practical strategies to adapt these heavy models to real‑world applications.
The third category focuses on unsupervised and self‑supervised approaches that have surged in the last five years. Contrastive learning frameworks such as SimCLR, MoCo, BYOL, and SwAV are explained, highlighting how they generate positive and negative pairs through data augmentations and learn invariant embeddings without explicit labels. The authors also cover multimodal self‑supervision exemplified by CLIP and ALIGN, which jointly train image and text encoders on billions of image‑caption pairs, enabling zero‑shot classification and natural language grounding. These methods dramatically reduce the reliance on manual annotation while still producing representations that rival supervised counterparts on downstream tasks.
A dedicated section examines the rise of Vision Transformers (ViT) and their variants (Swin Transformer, MAE). By tokenizing image patches and applying multi‑head self‑attention, ViTs capture global context in a single forward pass, overcoming the locality bias of convolutions. The paper notes the trade‑offs: ViTs demand even larger pre‑training corpora and higher computational budgets, and they require positional encodings to preserve spatial information. Nonetheless, they have set new performance records on several vision benchmarks and have spurred research into hybrid CNN‑Transformer designs.
From a neuroscientific perspective, the survey compares early‑layer filters of CNNs with V1 receptive fields, noting a striking similarity in orientation selectivity and spatial frequency tuning. However, deeper layers diverge from known cortical processing, lacking the recurrent and feedback dynamics observed in the brain. Recent attempts to incorporate biologically plausible learning rules (Hebbian, spike‑timing‑dependent plasticity) and spiking neural network implementations are briefly reviewed, suggesting a growing interest in bridging the gap between engineering performance and neural realism.
The authors conclude with practical guidance for model selection. For resource‑constrained edge devices, lightweight hand‑crafted descriptors or compact CNNs (MobileNet, EfficientNet‑B0) are recommended. For applications demanding top‑tier accuracy and abundant compute, deep ResNets, EfficientNets, or ViTs pretrained on massive datasets are appropriate. When labeled data are scarce or domain shift is a concern, self‑supervised models like CLIP or contrastive encoders provide a cost‑effective alternative. The paper also stresses the importance of interpretability and biological plausibility for scientific investigations, encouraging future work on multimodal integration, more efficient self‑supervision, and neuro‑inspired architectures that can learn with far fewer samples while maintaining high performance.