Synthetic Minority Over-sampling TEchnique(SMOTE) for Predicting Software Build Outcomes
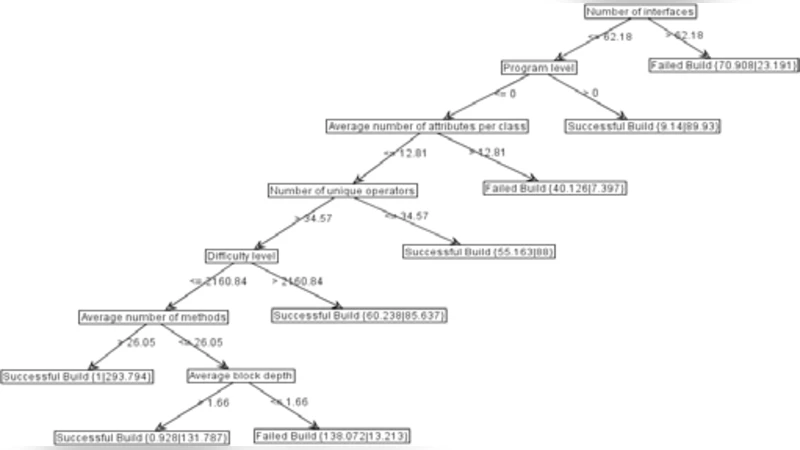
In this research we use a data stream approach to mining data and construct Decision Tree models that predict software build outcomes in terms of software metrics that are derived from source code used in the software construction process. The rationale for using the data stream approach was to track the evolution of the prediction model over time as builds are incrementally constructed from previous versions either to remedy errors or to enhance functionality. As the volume of data available for mining from the software repository that we used was limited, we synthesized new data instances through the application of the SMOTE oversampling algorithm. The results indicate that a small number of the available metrics have significance for prediction software build outcomes. It is observed that classification accuracy steadily improves after approximately 900 instances of builds have been fed to the classifier. At the end of the data streaming process classification accuracies of 80% were achieved, though some bias arises due to the distribution of data across the two classes over time.
💡 Research Summary
The paper investigates a real‑time predictive framework for software build outcomes by combining data‑stream mining with synthetic minority over‑sampling (SMOTE). Using source‑code metrics extracted from the IBM Jazz repository, the authors treat each build as an incremental instance in a continuous stream, allowing the model to evolve as new builds are generated. Because the repository contains a limited number of builds and the failure class represents a small minority, conventional classifiers tend to be biased toward the successful builds. To mitigate this imbalance, the authors apply SMOTE, which creates synthetic failure instances by interpolating between existing minority samples, thereby enriching the decision boundary and improving the classifier’s ability to learn from scarce data.
For the streaming classifier, an online decision‑tree algorithm such as the Hoeffding Tree (VFDT) is employed. This algorithm updates the model in a single pass with bounded memory, making it suitable for high‑velocity data streams. The experimental setup feeds roughly 1,200 build instances sequentially into the learner. Accuracy remains modest until about the 900th instance, after which it rises steadily, reaching approximately 80 % by the end of the stream. Feature‑importance analysis reveals that only a handful of metrics—primarily code complexity, number of changed lines, and file count—drive most of the predictive power, suggesting that developers can focus on these key indicators during pre‑build inspections.
Despite the overall performance gains, the study identifies persistent challenges. The class distribution shifts over time, causing temporary bias that SMOTE does not fully eliminate. Synthetic samples may also introduce noise, potentially degrading performance in certain windows. The authors recommend future work on adaptive over‑sampling strategies, dynamic class‑ratio estimation, and ensemble methods to further reduce bias and enhance robustness.
In summary, the research demonstrates that even with a modest, imbalanced dataset, a streaming decision‑tree model augmented by SMOTE can achieve reliable, near‑real‑time prediction of build success or failure. This contributes a practical, scalable approach for continuous integration pipelines and software quality assurance processes.