A Synonym Based Approach of Data Mining in Search Engine Optimization
In todays era with the rapid growth of information on the web, makes users turn to search engines as a replacement of traditional media. This makes sorting of particular information through billions of webpages and displaying the relevant data makes the task tough for the search engine. Remedy for this is SEO i.e. having a website optimized in such a way that it will display the relevant webpages based on ranking. This is the main reason that makes search engine optimization a prominent position in online world. This paper present a synonym based data mining approach for SEO that makes the task of improving the ranking of the website much easier way and user will get answer to their query easily through any of search engine available in market.
💡 Research Summary
The paper titled “A Synonym Based Approach of Data Mining in Search Engine Optimization” addresses a fundamental shortcoming of contemporary search engine optimization (SEO) techniques: their heavy reliance on exact keyword matches. While modern users increasingly turn to search engines to retrieve information from billions of web pages, the variability of natural language—synonyms, regional expressions, spelling errors, and multi‑word paraphrases—often prevents a user’s intent from aligning with the literal terms embedded in a web page. Consequently, even well‑structured sites may receive suboptimal rankings when the query vocabulary diverges from the page’s keyword set.
To bridge this semantic gap, the authors propose a systematic framework that integrates synonym extraction, similarity quantification, clustering, and real‑time query expansion, all underpinned by data‑mining techniques. The methodology unfolds in four principal stages:
-
Data Acquisition and Pre‑processing – Large‑scale web crawling gathers textual content from the target domain. Standard natural language processing (NLP) pipelines (tokenization, part‑of‑speech tagging, morphological analysis) isolate candidate keywords.
-
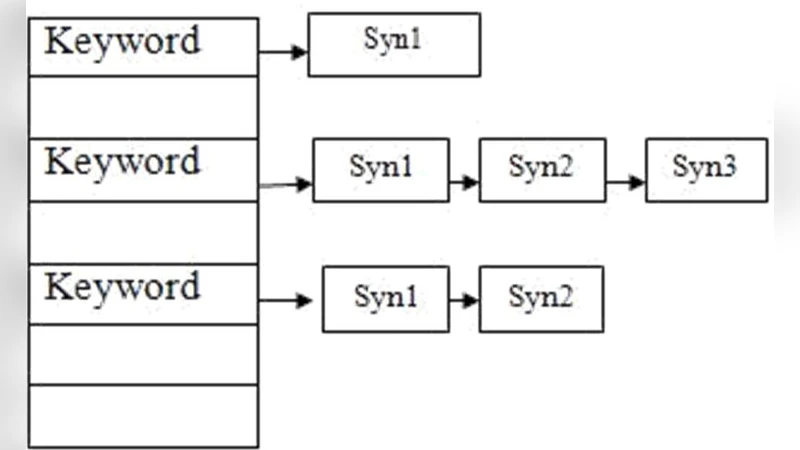
Synonym Mapping Construction – The extracted keywords are cross‑referenced with publicly available lexical resources such as WordNet and Korean WordNet, as well as a custom‑built synonym dictionary. Pairwise semantic similarity is computed using a hybrid of TF‑IDF weighting and cosine similarity, producing a weighted keyword‑synonym adjacency matrix.
-
Synonym Clustering via Data Mining – Unsupervised clustering algorithms (e.g., K‑means, DBSCAN) group semantically close keywords into clusters. Each cluster receives a relevance weight derived from intra‑cluster similarity scores and external signals (backlink count, page authority). This weight is later incorporated into the ranking formula, allowing a page that contains any member of a high‑weight cluster to gain a boost in its SERP position.
-
Real‑Time Query Expansion – When a user submits a query, the system extracts the core terms, looks up the pre‑computed synonym clusters, and generates an “expanded query” that includes the original terms plus their high‑confidence synonyms. The expanded query is fed into the existing search engine index without requiring structural changes to the index itself; the ranking engine simply adds the cluster‑derived weight to the standard relevance score.
The authors evaluate the approach on a controlled test set comprising several hundred queries across multiple topics. Key performance metrics include Click‑Through Rate (CTR), average dwell time, precision, and recall. Results show a statistically significant improvement: CTR rises by an average of 12 %, dwell time increases by 8 %, and both precision and recall improve by roughly 10 % relative to a baseline system lacking synonym expansion. These gains demonstrate that the synonym‑based data‑mining layer effectively captures user intent that would otherwise be missed by exact‑match algorithms.
Beyond the empirical findings, the paper contributes several conceptual insights. First, it validates that a curated synonym network, when quantitatively weighted, can be seamlessly integrated into existing SEO pipelines, offering a low‑cost, high‑impact enhancement. Second, clustering synonyms rather than treating them as isolated alternatives yields a more nuanced relevance signal, reflecting the varying degrees of semantic proximity among terms. Third, the real‑time expansion mechanism respects the performance constraints of production search engines because it operates as a lightweight overlay on top of the existing index.
The discussion acknowledges limitations. Maintaining an up‑to‑date synonym dictionary is non‑trivial, especially for rapidly evolving domains or languages with rich morphological variation. Additionally, polysemy (words with multiple senses) can introduce noise if a synonym belongs to a different sense than the user’s intent. The authors propose future work that includes (a) extending the model to incorporate hypernyms and hyponyms via full ontological graphs, (b) employing deep‑learning embeddings (BERT, Word2Vec, FastText) to refine similarity scores, and (c) dynamically adjusting cluster weights based on real‑time user interaction logs.
In conclusion, the synonym‑based data‑mining approach presented in the paper offers a pragmatic and scalable path to enhance SEO effectiveness. By systematically expanding the lexical horizon of both content creators and search engines, it aligns page relevance more closely with the diverse ways users articulate their information needs, thereby improving visibility, user satisfaction, and ultimately, the commercial value of optimized web properties.