Reducing Offline Evaluation Bias in Recommendation Systems
Recommendation systems have been integrated into the majority of large online systems. They tailor those systems to individual users by filtering and ranking information according to user profiles. This adaptation process influences the way users int…
Authors: Arnaud De Myttenaere (SAMM), Benedicte Le Gr, (CRI)
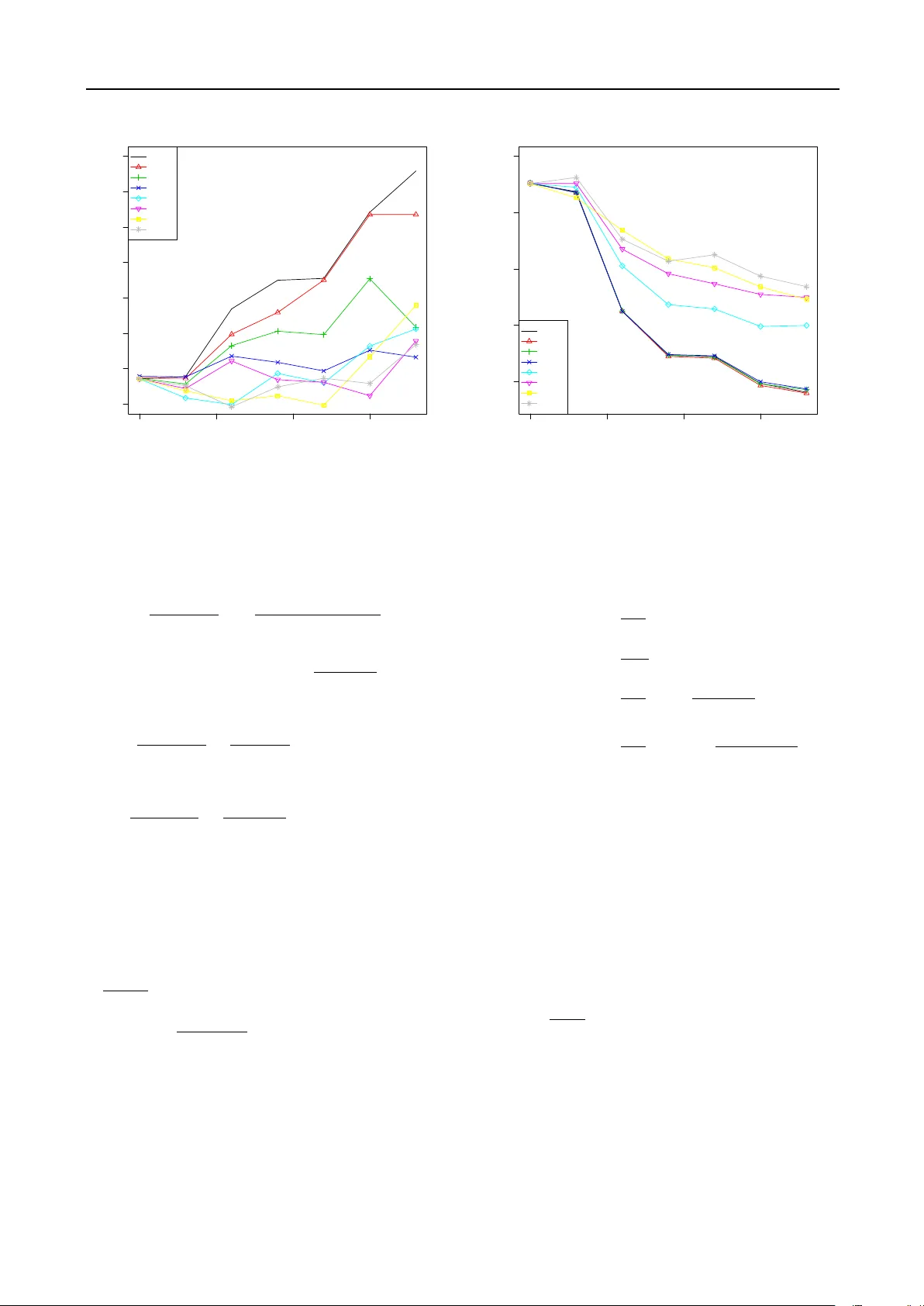
Reducing Offline Ev aluation Bias in Recommendation Systems Arnaud de Myttenaere ademyttenaere@viadeoteam.com Boris Golden bgolden@viadeoteam.com Viadeo, 30 rue de la Victoire, 75009 P aris, F rance B´ en´ edicte Le Grand benedicte.le-grand@univ-p aris1.fr Cen tre de Rec herc he en Informatique, Univ ersit ´ e P aris 1 P an th ´ eon – Sorb onne, 90 rue de T olbiac, 75013 P aris, F rance F abrice Rossi F abrice.R ossi@univ-p aris1.fr SAMM EA 4534, Univ ersit ´ e Paris 1 P an th ´ eon – Sorbonne, 90 rue de T olbiac, 75013 Paris, F rance Keyw ords : recommendation systems, offline ev aluation, ev aluation bias, co v ariate shift Abstract Recommendation systems ha v e b een in te- grated into the ma jority of large online sys- tems. They tailor those systems to individ- ual users b y filtering and ranking information according to user profiles. This adaptation pro cess influences the wa y users interact with the system and, as a consequence, increases the difficulty of ev aluating a recommendation algorithm with historical data (via offline eval- uation ). This pap er analyses this ev aluation bias and prop oses a simple item w eigh ting so- lution that reduces its impact. The efficiency of the prop osed solution is ev aluated on real w orld data extracted from Viadeo professional so cial net w ork. 1. In tro duction A recommender system pro vides a user with a set of p ossibly rank ed items that are supp osed to match the in terests of the user at a given moment ( ? ; ? ; ? ). Such systems are ubiquitous in the daily exp erience of users of online systems. F or instance, they are a crucial part of e-commerce where they help consumers select mo vies, bo oks, music, etc. that matc h their tastes. They also provide an imp ortant source of reven ues, e.g. via targeted ad placements where the ads display ed on a w ebsite are chosen according to the user profile as Preliminary work. Under review for BENELEARN 2014. Do not distribute. inferred by her browsing history for instance. Com- mercial asp ects set aside, recommender systems can b e seen as a wa y to select and sort information in a p er- sonalised wa y , and as a consequence to adapt a system to a user. Ob viously , recommendation algorithms must b e ev al- uated b efore and during their active use in order to ensure the quality of the recommendations. Liv e moni- toring is generally achiev ed using online quality metrics suc h as the clic k-through rate of displa y ed ads. This ar- ticle focuses on the offline ev aluation part whic h is done using historical data (which can b e recorded during online monitoring). One of the main strategy of offline ev aluation consists in simulating a recommendation by remo ving a confirmation action (click, purchase, etc.) from a user profile and testing whether the item asso- ciated to this action w ould hav e b een recommended based on the rest of the profile ( ? ). Numerous v ari- ations of this general scheme are used ranging from remo ving sev eral confirmations to taking into account item ratings. While this general scheme is completely v alid from a statistical p oint of view, it ignores v arious factors that ha v e influenced historical data as the re commendation algorithms previously used. Assume for instance that sev eral recommendation algo- rithms are ev aluated at time t 0 based on historical data of the user database until t 0 . Then the b est algorithm is selected according to a quality metric asso ciated to the offline pro cedure and put in pro duction. It starts recommending items to the users. Pro vided the algo- rithm is go o d enough, it generates some confirmation Reducing Offline Ev aluation Bias in Recommendation Systems actions. Those actions can b e attributed to a go o d user mo deling but also to luc k and to a natural attraction of some users to new things. This is esp ecially true when the cost of confirming/accepting a recommendation is lo w. In the end, the state of the system at time t 1 > t 0 has b een influenced by the recommendation algorithm in pro duction. Then if one wan ts to monitor the p erformance of this algorithm at time t 1 , the offline pro cedure sometimes o v erestimates the quality of the algorithm b ecause con- firmation actions are now frequently triggered b y the recommendations, leading to a very high predictability of the corresp onding items. This bias in offline ev aluation with online systems can also b e caused by other even ts such as a promotional offer on some sp ecific pro ducts b etw een a first offline ev aluation and a second one. Its main effect is to fav or algorithms that tend to recommend items that hav e b een fa vored betw een t 0 and t 1 and th us to fav or a kind of “winner take all” situation in which the algorithm considered as the b est at t 0 will probably remain the b est one afterwards, ev en if an unbiased pro cedure could demote it. While limits of ev aluation strategies for recommendation algorithms hav e been identified in e.g. ( ? ; ? ; ? ), the ev aluation bias describ ed ab ov e has not b een addressed in the literature, to our knowledge. This pap er prop oses a mo dification of the classical of- fline ev aluation pro cedure that reduces the impact of this bias. F ollowing the general principle of weigh ting instances used in the context of cov ariate shift ( ? ), we prop ose to assign a tunable weigh t to each item. The w eigh ts are optimized in order to reduce the bias with- out discarding new data generated since the reference ev aluation. The rest of the pap er is organized as follo ws. Section 2 describ es in detail the setting and the problem ad- dressed in this pap er. Section 3 in tro duces the weigh t- ing sc heme prop osed to reduce the ev aluation bias. Section 4 demonstrates the practical relev ance of the metho d on real world data extracted from the Viadeo professional so cial net w ork 1 . 2. Problem formulation 2.1. Notations and setting W e denote U the set of users, I the set of items and D t the historical data a v ailable at time t . A recommen- 1 Viadeo is the world’s second largest professional so cial net work with 55 million members in August 2013. See http://corporate.viadeo.com/en/ for more information ab out Viadeo. dation algorithm is a function g from U × D t to some set built from I . W e will denote g t ( u ) = g ( u, D t ) the recommendation computed by g at instant t for user u . The recommendation strategy , g t ( u ), could b e a list of k items (ordered in decreasing interest), a set of k items (with no ranking), a mapping from a subset of I to n umerical grades for some items, etc. The sp ecifics are not relev ant to the present analysis as w e assume giv en a quality function l from product of the result space of g and I to R + that measures to what extent an item i is correctly recommended by g at time t via l ( g t ( u ) , i ). Offline ev aluation is based on the p ossibility of “re- mo ving” an y item i from a user profile ( I u denotes the items asso ciated to u ). The result is denoted u − i and g t ( u − i ) is the recommendation obtained at instan t t when i has b een remov ed from the profile of user u . If g outputs a subset of I , then one p ossible choice for l is l ( g t ( u − i ) , i ) = 1 when i ∈ g t ( u − i ) and 0 otherwise. If g outputs a list of the b est k items, then l will decrease with the rank of i in this list (it could b e, e.g., the in v erse of the rank). Finally , offline ev aluation follows a general scheme in whic h a user is chosen according to some prior probabil- it y on users P ( u ) (these probabilities might reflect the business imp ortance of the users, for instance). Given a user, an item is chosen among the items asso ciated to its profile, according to some c onditional probability on items P ( i | u ). When an item i is not asso ciated to a user u (that is i 6∈ I u ), P ( i | u ) = 0. Notice than while w e use a sto chastic framew ork, exhaustiv e approac hes are common in medium size systems. In this case, the probabilities will b e interpreted as weigh ts and all the pairs ( u, i ) (where i ∈ I u ) will b e used in the ev aluation pro cess. In b oth sto chastic and exhaustiv e ev aluations, a very common choice for P ( u ) is the uniform proba- bilit y on U . It is also quite common to use a uniform probabilit y for P ( i | u ). F or instance, one could fav or items recen tly asso ciated to a profile o v er older ones. The tw o distributions P ( u ) and P ( i | u ) lead to a joint distribution P ( u, i ) = P ( i | u ) P ( u ) on U × I . In an online system, P ( i | u ) evolv es ov er time 2 . F or exam- ple, if the probability P ( i | u ) is uniform ov er the items asso ciated to user u , then as so on as u gets a new item (recommended by an algorithm, for instance), all probabilities are mo dified. The same is true for more complex schemes that take into accoun t the age of the items, for instance. 2 While P ( u ) could also evolv e ov er time, we do not consider the effects of such evolution in the present article. Reducing Offline Ev aluation Bias in Recommendation Systems 2.2. Origin of the bias in offline ev aluation The offline ev aluation pro cedure consists in calculating the quality of the recommender g at instant t as L t ( g ) = E ( l ( g t ( u − i ) , i )) where the exp ectation is taken with resp ect to the join t distribution, that is L t ( g ) = X ( u,i ) ∈ U × I P t ( i | u ) P t ( u ) l ( g t ( u − i ) , i ) . (1) In very large systems, L t ( g ) is approximated b y actually sampling from U × I according to the probabilities while in small ones, the probabilities are used as weigh ts, as p oin ted out ab ov e. Then if tw o algorithms are ev aluated at tw o different momen ts, their qualities are not directly comparable. While this problem do es not fall exactly into the co v ari- ate shift paradigm ( ? ), it is related: once a recommen- dation algorithm is chosen based on a given state of the system, it is almost guaranteed to influence the state of the system while put in pro duction, inducing an increasing distance b etw een its ev aluation environmen t (i.e. the initial state of the system) and the e v olving state of the system. This influence of the recommenda- tion algorithm on the state of the system is resp onsible for the bias since offline ev aluation relies on historical data. A naive solution to this bias would b e to define a fixed ev aluation database (a snapshot of the system at t 0 ) and to compare algorithms only with resp ect to the original database. This is clearly unacceptable for an online system as it w ould discard b oth new users and, more imp ortan tly , evolutions of user profiles. 2.3. Real w orld illustration of the bias W e illustrate the evolution of the P t ( i ) probabilities in an online system with a functionalit y provided by the Viadeo platform: each user can claim to ha ve some skills that are displa yed on his/her profile (examples of skills include pro ject management, marketing, etc.). In order to obtain more complete profiles, skills are recommended to the users via a recommendation algo- rithm, a practice that has obviously consequences on the probabilities P t ( i ), as illustrated on Figure 1. The skill functionality has b een implemen ted at time t = 0. After 300 days, some of the P t ( i ) are roughly static. Probabilities of other items still evolv e ov er time under v arious influences, but the ma jor sources of ev olution are recommendation campaigns. Indeed, at times t = 330 and t = 430, recommendation campaigns ha v e been conducted: users hav e received p ersonalized recommendation of skills to add to their profiles. The figure shows strong mo difications of the P t ( i ) quickly ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 300 350 400 450 0.004 0.006 0.008 0.010 0.012 0.014 0.016 0.018 t selection probability Figure 1. Impact of recommendation campaigns on the item probabilities: each curve displays the evolution of P ( i ) ov er time for a given item. after eac h campaign. In particular, the probabilities of the items whic h ha ve b een recommended increase significan tly; this is the case for the blac k, pink and ligh t blue curves at t = 330. On the other hand, the probabilities of the items which hav e not b een recom- mended decrease at the same time. The probabilities tend to b ecome stable again un til the same phenomenon can be observed righ t after the second recommenda- tion campaign at t = 430: the curves corresponding to the items that ha v e b een recommended again keep increasing. The green curve represents the probability of an item which has b een recommended only during the second recommendation campaign. Section 4.2 demonstrates the effects of this evolution on algorithm ev aluations. 3. Reducing the ev aluation bias 3.1. Principle for reducing the bias Let us consider a naive algorithm which alw a ys recom- mends the same items whatever the user and historical data. In other words, g is constant. Constant algo- rithms are particularly easy to understand and useful to illustrate the bias due to external factors. Indeed one can reasonably assume that the score of such algorithms do es not strongly v ary ov er time. A simple transformation of equation (1) shows that for Reducing Offline Ev aluation Bias in Recommendation Systems a constan t algorithm g : L t ( g ) = X u ∈ U X i ∈ I P t ( i | u ) P t ( u ) l ( g t , i ) = X i ∈ I l ( g t , i ) X u ∈ U P t ( i | u ) P t ( u ) = X i ∈ I P t ( i ) l ( g t , i ) . (2) As a consequence, a wa y to guarantee a stationary ev al- uation framework for a constan t algorithm is to ha v e constan t v alues for the P t ( i ) (the marginal distribution of the items). A natural solution to hav e constan t v alues for P t ( i ) w ould b e to record those probabilities at t 0 and use them subsequen tly in offline ev aluation as the proba- bilit y to select an item. Ho wev er, this would require to revert the wa y offline ev aluation is done: first select an item, then select a user having this item with a certain probabilit y π t ( u | i ). But as the probability law originally defined on users reflects their relativ e imp or- tance and should not b e mo dified, it will b e necessary to compute π t ( u | i ) such as the ov erall probability law on users is close enough to the original one P t 0 ( u ) . The computation of the co efficients π t ( u | i ) w ould need to b e done for all use rs. Keeping the standard offline ev aluation pro cedure and computing co efficients to al- ter the probabilities of selecting an item for a given user is more efficient b ecause it can b e done only for a limited num b er of key items (in practice in muc h smaller quan tit y than the num b er of users for most of real world systems) leading to a muc h low er complexit y . A strong assumption w e make is that in practice re- ducing offline ev aluation bias for constan t algorithms con tributes to reducing offline ev aluation bias for all algorithms. 3.2. Item w eights P t ( i | u ) probabilities are thus the only quantities that can b e mo dified in order to reduce the bias of offline ev aluation. In particular, P t ( u ) is driv en b y business considerations related to the imp ortance of individ- ual users and can seldom b e manipulated without im- pairing the asso ciated business metrics. W e prop ose therefore to depart from the classical v alues for P t ( i | u ) (suc h as using a uniform probability) in order to mimic static v alues for P t 0 ( i ). This approac h is related to the w eigh ting strategy used in the case of cov ariate shift ( ? ). This is implemented via tunable item sp ecific weigh ts, the ω = ( ω i ) i ∈ I , which induce mo dified conditional probabilities P t ( i | u, ω ). The general idea is to increase the probabilit y of selecting i if ω i is larger than 1 and vice versa, so that ω recalibrates the probability of selecting eac h item. The simplest wa y to implement this probability mo dification is to define P t ( i | u, ω ) as follo ws: P t ( i | u, ω ) = ω i P t ( i | u ) P j ∈ I t ω j P t ( j | u ) . (3) Other w eigh ting sc hemes could b e used. Notice that these w eighted conditional probabilities lead to w eigh ted item probabilities defined b y: P t ( i | ω ) = X u ∈ U P t ( i | u, ω ) P t ( u ) . (4) 3.3. Adjusting the w eights W e th us reduce the ev aluation bias by leveraging the weigh ts ω and using the asso ciated distribution P t 1 ( i | u, ω ) instead of P t 1 ( i | u ). Indeed one can c hose ω in such as wa y that P t 1 ( i | ω ) ' P t 0 ( i ). This allows one to use all the data av ailable at time t 1 for the offline ev aluation while limiting the bias induced b y those new data. This leads to a non-linear system with n i equations and n i parameters ( ω 1 , . . . , ω n i ) suc h that for all i ∈ I t 1 : X u ∈ U ω i P t 1 ( i | u, ω i ) P j ∈ I ω j P t 1 ( j | u, ω j ) · P t 1 ( u ) = P t 0 ( u ) ω cannot b e solved easily and w e thus need to approxi- mate it using an optimisation algorithm. Optimizing the weigh ts amounts to reducing a dissimi- larit y b et w een the weigh ted distribution and the origi- nal one. W e use here the Kullback-Leibler divergence, that is D ( ω ) = D K L ( P t 0 ( . ) k P t 1 ( . | ω )) = X i ∈ I t 0 P t 0 ( i ) log P t 0 ( i ) P t 1 ( i | ω ) . (5) Where I t 0 represen ts the set of items which hav e b een selected at least once at t 0 . The asymmetric nature of D K L is useful in our context as it reduces the influence of rare items at time t 0 as they were not very imp ortant in the calculation of L t 0 ( g ). The target probabilit y P t 0 ( i ) is computed once and for all items at the initial ev aluation time. One co ordinate of the gradient can b e computed in O ( N U × I t 1 ), where N U × I t 1 is the n umber of couples ( u, i ) with i ∈ I u and u ∈ U at instan t t 1 . Th us the whole gradient can b e computed in complexity O ( n i · N U × I t 1 ). This Reducing Offline Ev aluation Bias in Recommendation Systems w ould b e prohibitive on a large system. T o limit the optimization cost, we focus on the largest mo difications b et w een P t 0 ( i ) and P t 1 ( i ). More precisely , w e compute once P t 1 ( i ) for all i ∈ I t 0 and select the subset I t 1 t 0 ( p ) of I t 1 of size p whic h exhibits the largest differences in absolute v alues b etw een P t 0 ( i ) and P t 1 ( i ). Then D ( ω ) is only optimized with resp ect to the cor- resp onding weigh ts ( ω i ) i ∈ I t 1 t 0 ( p ) , leading to a cost in O ( p · N U × I t 1 ) for eac h gradient calculation. Notice that p is therefore an imp ortant parameter of the weigh ting strategy . In practice, w e optimize the divergence via a basic gradien t descent. Notice that to implemen t w eigh t optimization, one needs to compute P t 0 ( i ) and P t 1 ( i ). As p ointed out in 3.1 these are costly operations. W e assume how ever that ev aluating several recommendation algorithms has a muc h larger cost, b ecause of the rep eated ev aluation of L t ( g ) asso ciated to e.g. statistical mo del parameter tuning. Then while optimizing ω is costly , it allows one to rely on the efficient classical offline strategy to ev aluate recommendation algorithms with a reduced bias. 4. Exp erimental ev aluation 4.1. Data and metrics The prop osed approach is studied on real world data extracted from the Viadeo professional so cial netw ork. The recommendation setting is the one describ ed in Section 2.3: users can attach skills to their profile. Skills are recommended to the users in order to help them build more accurate and complete profiles. In this context, items are skills. The data set used for the analysis con tains 34 448 users and 35 741 items. The av erage num b er of items p er user is 5.33. The distribution of items p er user follows roughly a p ow er la w, as shown on Figure 2. Both probabilities P t ( u ) and P t ( i | u ) are uniform. The qualit y function l is given by l ( g t ( u − i ) , i ) = 1 i ∈ g t ( u − i ) where g t ( u − i ) consists in 5 items. W e use constan t rec- ommendation algorithms to fo cus on the direct effects of our weigh ting prop osal, whic h means here that each algorithm is based on a selection of 5 items that will b e recommended to all users. The quality of a recommendation algorithm, L t ( g ), is estimated via sto chastic sampling in order to sim ulate what could b e done on a larger data set than the one used for testing. W e selected rep eatedly 20 000 users (uniformly among the 34 448, including p ossible rep etitions) and then one item p er user (according to P t ( i | u ) or P t ( i | u, ω )). ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1 2 5 10 20 50 1 5 10 50 100 500 5000 N items N members Figure 2. Distribution of items p er user The analysis is conducted on a 201 days p erio d, from da y 300 to day 500. Day 0 corresp onds to the launch date of the skill functionality . As noted in Section 2.3 tw o recommendation campaigns were conducted b y Viadeo during this p erio d at t = 330 and t = 430 resp ectiv ely . 4.2. Bias in action W e first demonstrate the effect of the bias on tw o constan t recommendation algorithms. The first one g 1 is mo deled after the actual recommendation algorithm used by Viadeo in the following sense: it recommends the five most recommended items from t = 320 to t = 480. The second algorithm g 2 tak es the opp osite approac h by recommending the five most frequent items at time t = 300 among the items that w ere never recommended from t = 320 to t = 480. In a sense, g 1 agrees with Viadeo’s recommendation algorithm, while g 2 disagrees. Figures 3 and 4 show the evolution of L t ( g 1 ) and L t ( g 2 ) o v er time. As both algorithms are constant, it w ould be reasonable to exp ect minimal v ariations of their offline ev aluation scores. Ho wev er in practice the estimated qualit y of g 1 increases by more than 25 %, while the relativ e decrease of g 2 reac hes 33 %. 4.3. Reduction of the bias W e apply the strategy describ ed in Section 3 to compute optimal weigh ts at different instan ts and for several Reducing Offline Ev aluation Bias in Recommendation Systems ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 300 350 400 450 0.040 0.042 0.044 0.046 0.048 0.050 0.052 t expected score Figure 3. Ev olution of L t ( g 1 ) ov er time ( g 1 “agrees” with the recommendation algorithm) v alues of the p parameter. Results are summarized in Figures 5 and 6. The figures show clearly the stabilizing effects of the w eigh ting strategy on the scores of b oth algorithms. In the case of algorithm g 1 , the stabilisation is quite satisfactory with only p = 20 activ e weigh ts. This is exp ected b ecause g 1 agrees with Viadeo’s recommen- dation algorithm and therefore recommends items for whic h probabilities P t ( i ) change a lot ov er time. Those probabilities are exactly the ones that are corrected by the w eigh ting technique. The case of algorithm g 2 is less fav orable, as no stabili- sation o ccurs with p ≤ 20. This can b e explained by the relativ e stability ov er time of the probabilities of the items recommended by g 2 (indeed, those items are not recommended during the p erio d under study). Then the p erceived reduction in quality ov er time is a con- sequence of increased probabilities asso ciated to other items. Because those items are never recommended by g 2 , they corresp ond to direct recommendation failures. In order to stabilize g 2 ev aluation, w e need to take into accoun t w eaker modifications of probabilities, whic h can only b e done by increasing p . This is clearly shown b y Figure 6. 5. Conclusion W e hav e analyzed the offline ev aluation bias induced b y v arious factors that hav e influenced historical data ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 300 350 400 450 0.0040 0.0045 0.0050 0.0055 0.0060 t expected score Figure 4. Ev olution of L t ( g 2 ) o ver time ( g 2 “disagrees” with the recommendation algorithm) as the recommendation algorithms previously used for suc h an online system. Indeed, as recommendations influence users, a recommendation algorithm in pro duc- tion tends to b e fav ored by offline ev aluation ov er time. On the contrary , an algorithm with different recom- mendations will generally witness o ver time a reduction of its offline ev aluation score. T o ov ercome this bias, w e hav e introduced a simple item weigh ting strategy inspired by techniques designed for tackling the cov ari- ate shift problem. W e hav e shown on real world data extracted from Viadeo professional so cial netw ork that the prop osed technique reduces the ev aluation bias for constan t recommendation algorithms. While the prop osed solution is very general, we hav e only fo cused on the simplest situation of constant rec- ommendations ev aluated with a binary quality metric (an item is either in the list of recommended items or not). F urther w orks include the confirmation of bias reduction on more elab orate algorithms, p ossibly with more complex quality functions. The trade off b etw een the computational cost of the proposed solution and its qualit y should also b e in v estigated in more details. A. Algorithmic details A.1. Gradien t calculation W e optimize D ( ω ) with a gradient based algorithm and hence ∇ D is needed. Let i and k b e tw o distinct items Reducing Offline Ev aluation Bias in Recommendation Systems ● ● ● ● ● ● ● 300 350 400 450 0.038 0.040 0.042 0.044 0.046 0.048 0.050 0.052 t score ● 1 5 10 20 100 300 600 1000 Figure 5. Ev olution of L t ( g 1 ) ov er time ( g 1 “agrees” with the recommendation algorithm) when items are weigh ted (see text for details). i 6 = k , then ∂ P ( i | u, ω ) ∂ ω k = − ω i P ( i | u ) P ( k | u ) P j ∈ I ω j P ( j | u ) 2 , = − P ( i | u, ω ) P ( k | u, ω ) ω k . (6) W e hav e also ∂ P ( i | u, ω ) ∂ ω i = P ( i | u, ω ) ω i (1 − P ( i | u, ω )) , (7) and therefore for all k : ∂ P ( i | u, ω ) ∂ ω k = P ( k | u, ω ) ω k ( δ ik − P ( i | u, ω )) . (8) W e ha ve implicitly assumed that the ev aluation is based on indep enden t draws, and therefore: P ( i, k | ω ) = X u P ( i | u, ω ) P ( k | u, ω ) P ( u ) . (9) Then ∂ D ( ω ) ∂ ω k = X i P t 0 ( i ) ω k P t 1 ( i | ω ) ( P t 1 ( i, k | ω ) − δ ik P t 1 ( k | ω )) . Application: if P ( u ) ∼ U ( U ) and P ( i | U ) ∼ U ( I u ), then: ● ● ● ● ● ● ● 300 350 400 450 0.0040 0.0045 0.0050 0.0055 0.0060 t score ● 1 5 10 20 100 300 600 1000 Figure 6. Ev olution of L t ( g 2 ) o ver time ( g 2 “disagrees” with the recommendation algorithm) when items are weigh ted (see text for details). P ( u ) = 1 # U P ( i | u ) = 1 # I u · 1 i ∈ I u P ( i | ω ) = 1 # U · X u ∈ U i ω i P j ∈ I u ω j P ( i, k | ω ) = 1 # U · X u ∈ U i ∩ U k ω i ω k ( P j ∈ I u ω j ) 2 Complexit y: Assuming we hav e a sparse matrix A ∈ M n U , n I ( R ) such as A u,i = 1 u ∈ I u , we suggest to pre- calculate P t 0 ( i ) and then for each co ordinate of the gradien t and for each i : • compute P ( i | ω ) = P u ∈ U i P ( i | u, ω ) P ( u ) in O (# U i ) • compute P ( i, k | ω ) = P i ∈ U i P ( i | u, ω ) P ( k | u, ω ) P ( u ) in O (# U i ) Then eac h ∂ D ( ω ) ∂ ω k consists in a sum of I terms computed in O (1), so that we can compute each coordinate of the gradien t is O ( P i ∈ I U i ) = O ( | A | ). Th us, as | A | = N U × I the complexity to compute p co ordinates of the gradien t is O ( p · N U × I ). Reducing Offline Ev aluation Bias in Recommendation Systems References Adoma vicius and T uzhilin][2005]adoma vicius2005to ward Adoma vicius, G., & T uzhilin, A. (2005). T o ward the next generation of recommender systems: A surv ey of the state-of-the-art and p ossible exten- sions. Know le dge and Data Engine ering, IEEE T r ansactions on , 17 , 734–749. Herlo c k er et al.][2004]Herlo ck erEtAl2004Ev aluating Herlo c k er, J. L., Konstan, J. A., T erveen, L. G., & Riedl, J. T. (2004). Ev aluating collab orative fil- tering recommender systems. A CM T r ansactions on Information Systems , 22 , 5–53. Kan tor et al.][2011]k an tor2011recommender Kan tor, P . B., Rok ach, L., Ricci, F., & Shapira, B. (Eds.). (2011). R e c ommender systems handb o ok . Springer. McNee et al.][2006]mcnee2006b eing McNee, S. M., Riedl, J., & Konstan, J. A. (2006). Being accu- rate is not enough: how accuracy metrics hav e hurt recommender systems. CHI’06 extende d abstr acts on Human factors in c omputing systems (pp. 1097– 1101). P ark et al.][2012]park2012literature Park, D. H., Kim, H. K., Choi, I. Y., & Kim, J. K. (2012). A litera- ture review and classification of recommender sys- tems research. Exp ert Systems with Applic ations , 39 , 10059–10072. Said et al.][2013]said2013user Said, A., Fields, B., Jain, B. J., & Alba yrak, S. (2013). User-centric ev alua- tion of a k-furthest neighbor collab orative filtering recommender algorithm. Pr o c e e dings of the 2013 c onfer enc e on Computer supp orte d c o op er ative work (pp. 1399–1408). Shani and Gunaw ardana][2011]shani2011ev aluating Shani, G., & Gunaw ardana, A. (2011). Ev aluating recommendation systems. In P . B. Kan tor, L. Rok ac h, F. Ricci and B. Shapira (Eds.), R e c ommender sys- tems handb o ok , 257–297. Springer. Shimo daira][2000]Shimo daira2000227 Shimo daira, H. (2000). Improving predictive inference under cov ari- ate shift by weigh ting the log-lik eliho od function. Journal of Statistic al Planning and Infer enc e , 90 , 227 – 244. Sugiy ama et al.][2007]sugiyama2007co v ariate Sugiy ama, M., Krauledat, M., & M ¨ uller, K.-R. (2007). Co v ariate shift adaptation by imp ortance weigh ted cross v ali- dation. The Journal of Machine L e arning R ese ar ch , 8 , 985–1005.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment