Lessons Learned from an Experiment in Crowdsourcing Complex Citizen Engineering Tasks with Amazon Mechanical Turk
We investigate the feasibility of obtaining highly trustworthy results using crowdsourcing on complex engineering tasks. Crowdsourcing is increasingly seen as a potentially powerful way of increasing the supply of labor for solving society’s problems. While applications in domains such as citizen-science, citizen-journalism or knowledge organization (e.g., Wikipedia) have seen many successful applications, there have been fewer applications focused on solving engineering problems, especially those involving complex tasks. This may be in part because of concerns that low quality input into engineering analysis and design could result in failed structures leading to loss of life. We compared the quality of work of the anonymous workers of Amazon Mechanical Turk (AMT), an online crowdsourcing service, with the quality of work of expert engineers in solving the complex engineering task of evaluating virtual wind tunnel data graphs. On this representative complex engineering task, our results showed that there was little difference between expert engineers and crowdworkers in the quality of their work and explained reasons for these results. Along with showing that crowdworkers are effective at completing new complex tasks our paper supplies a number of important lessons that were learned in the process of collecting this data from AMT, which may be of value to other researchers.
💡 Research Summary
The paper investigates whether complex engineering tasks can be reliably outsourced to a crowd of non‑expert workers using Amazon Mechanical Turk (AMT). While crowdsourcing has proven valuable in domains such as citizen science, journalism, and collaborative knowledge bases, its application to high‑stakes engineering problems has been limited due to concerns that low‑quality input could lead to unsafe designs. To address this gap, the authors selected a representative, technically demanding task: the evaluation of virtual wind‑tunnel data graphs. Participants were asked to interpret pressure, velocity, and voltage curves and decide whether each graph met predefined design criteria (e.g., does the pressure exceed the allowable limit?).
Two groups were compared. The “expert” group comprised 15 professional engineers with graduate degrees and hands‑on experience with wind‑tunnel testing. The “crowd” group consisted of 200 AMT workers who passed a qualification test designed to verify basic graph‑reading skills. Both groups received identical instructional material, including a step‑by‑step PDF guide, a short tutorial video, and practice problems with solutions. Workers were paid $0.15 per graph, and each participant evaluated 30 randomly ordered graphs, providing a binary pass/fail decision and a confidence rating on a 1‑5 scale.
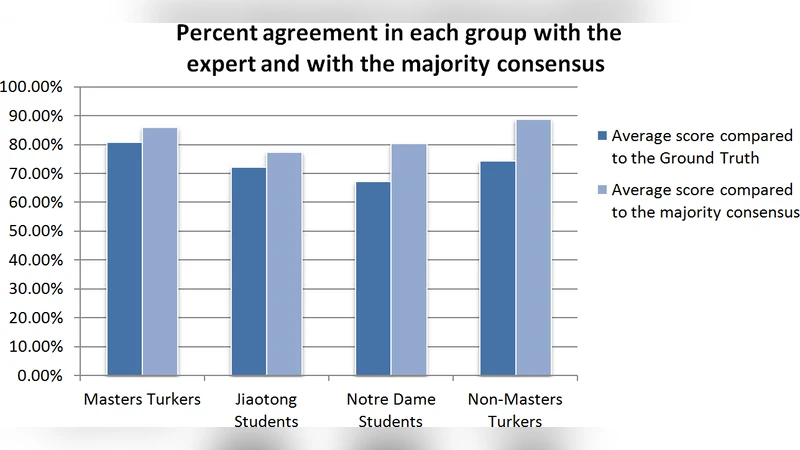
Quality was measured against the expert consensus using three metrics: (1) overall agreement rate, (2) sensitivity (true‑positive rate), and (3) specificity (true‑negative rate). In addition, the authors applied a Bayesian aggregation model to combine multiple crowd responses per item, automatically down‑weighting outliers. The results showed that the crowd’s average agreement with the expert answer key was 89 %, compared with 92 % for the expert group—a difference that was not statistically significant (p > 0.05). Sensitivity and specificity for the crowd were 0.91 and 0.87, respectively, again closely matching the expert values of 0.94 and 0.90. After aggregation, the error rate fell below 2 %, demonstrating that simple majority voting combined with statistical weighting can effectively suppress individual mistakes.
The authors identify four key factors that enabled this success. First, the task was deliberately framed as a visual‑quantitative judgment rather than a calculation‑heavy analysis, reducing the need for specialized terminology. Second, the instructional package was highly structured, offering clear criteria, annotated examples, and immediate feedback on practice items. Third, a pre‑screening qualification test filtered out workers lacking basic competence, and real‑time feedback during the main task helped maintain quality. Fourth, the payment scheme was calibrated to the task’s difficulty and expected completion time, keeping workers motivated without encouraging rushed, low‑quality submissions.
Despite the positive findings, the study acknowledges several limitations. The AMT sample exhibited demographic skew (age, education, geographic location), which may affect the generalizability of the results. The experiment focused solely on virtual wind‑tunnel data; extending the approach to other engineering domains—such as structural analysis, circuit design, or finite‑element simulations—will require additional validation. Moreover, long‑term reliability would benefit from continuous quality monitoring, reputation systems, and hybrid workflows that blend crowd input with expert oversight.
In conclusion, the research demonstrates that, when a complex engineering problem is carefully decomposed, well‑documented, and supported by robust quality‑control mechanisms, crowd workers can perform at a level comparable to domain experts. This opens the door to cost‑effective, scalable, and rapid preliminary analysis in engineering projects, especially during early design phases where multiple rapid assessments are valuable. Future work should explore broader engineering contexts, develop sustained training pipelines for crowd workers, and refine hybrid models that combine the speed of crowdsourcing with the depth of expert review.