Multi-utility Learning: Structured-output Learning with Multiple Annotation-specific Loss Functions
Structured-output learning is a challenging problem; particularly so because of the difficulty in obtaining large datasets of fully labelled instances for training. In this paper we try to overcome this difficulty by presenting a multi-utility learning framework for structured prediction that can learn from training instances with different forms of supervision. We propose a unified technique for inferring the loss functions most suitable for quantifying the consistency of solutions with the given weak annotation. We demonstrate the effectiveness of our framework on the challenging semantic image segmentation problem for which a wide variety of annotations can be used. For instance, the popular training datasets for semantic segmentation are composed of images with hard-to-generate full pixel labellings, as well as images with easy-to-obtain weak annotations, such as bounding boxes around objects, or image-level labels that specify which object categories are present in an image. Experimental evaluation shows that the use of annotation-specific loss functions dramatically improves segmentation accuracy compared to the baseline system where only one type of weak annotation is used.
💡 Research Summary
The paper tackles the long‑standing challenge of training structured‑output models—particularly semantic image segmentation—when fully annotated data are scarce. The authors propose a “multi‑utility learning” framework that simultaneously incorporates several types of weak supervision (image‑level labels, bounding boxes, and object seeds) into a latent‑variable structural SVM (LV‑SSVM). Central to the approach is the definition of annotation‑specific loss functions K(y, z) that estimate the expected Hamming loss of a labeling y with respect to a weak annotation z. By designing these losses to share a common scale (the expected Hamming loss), the framework requires only a single balancing coefficient α to trade off the influence of fully‑labeled versus weakly‑labeled data.
For image‑level labels, the loss penalizes pixels assigned to labels absent from the annotation and penalizes omission of annotated labels, using either estimated class areas from fully‑labeled examples or a uniform prior when such statistics are unavailable. For bounding boxes, the loss enforces that super‑pixels inside a box receive the box’s label, while penalizing the presence of box‑labels outside the box and the appearance of labels that should be absent. Seeds are treated as hard constraints on specific super‑pixels. All these losses can be expressed as unary terms plus label‑cost terms, allowing the use of graph‑cut based α‑expansion with label‑cost extensions for efficient inference.
Training proceeds via the cutting‑plane method combined with the concave‑convex procedure (CCCP) to handle the non‑convexity introduced by latent variables. Two inference sub‑problems are required at each iteration: (1) loss‑augmented inference, which finds the most violating labeling under the current model plus the annotation‑specific loss, and (2) annotation‑consistent inference, which finds the highest‑scoring labeling that respects the weak annotation. Both are solved efficiently with graph‑cut algorithms; the loss‑augmented step becomes a standard MRF problem with label costs, while the annotation‑consistent step reduces to α‑expansion over the allowed label set.
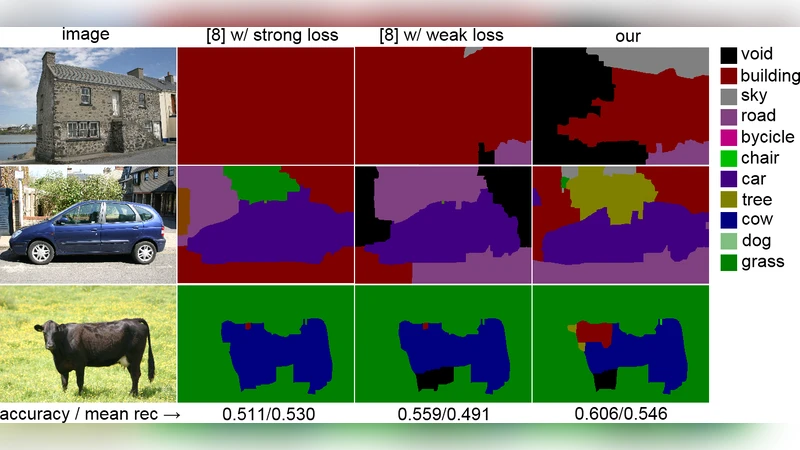
Experiments on the MSRC and PASCAL VOC datasets compare four settings: (i) fully supervised SSVM, (ii) SSVM with only image‑level labels, (iii) the proposed multi‑utility model using image‑level labels plus bounding boxes, and (iv) the full model using image‑level labels, bounding boxes, and seeds. Evaluation metrics include mean Intersection‑over‑Union (IoU), pixel accuracy, and average precision. The multi‑utility model consistently outperforms the single‑annotation baselines, achieving up to an 8 % increase in IoU over image‑level‑only training and a further 2–3 % gain when seeds are added. Ablation studies demonstrate that the balancing coefficient α is crucial: setting α too high over‑weights weak annotations and leads to over‑fitting, while too low under‑utilizes the abundant weak data. The authors also show that the framework can handle mixed annotation types within a single image (e.g., some classes annotated by boxes, others only by image‑level tags).
Key contributions are: (1) a principled method for constructing annotation‑specific loss functions that approximate expected Hamming loss, (2) integration of multiple weak supervision signals into a single LV‑SSVM objective with a simple scalar weighting scheme, and (3) efficient graph‑cut based algorithms for both loss‑augmented and annotation‑consistent inference, even with non‑decomposable losses. Limitations include the need for some fully‑labeled data or reliable class‑area statistics to estimate expectations, and scalability concerns when the number of classes becomes very large, as graph‑cut memory usage grows with the label set.
In summary, the paper presents a robust, scalable approach to leverage heterogeneous weak annotations for structured prediction tasks. By unifying diverse supervision signals under a common loss framework and solving the resulting optimization efficiently, it demonstrates that high‑quality segmentation models can be trained with far fewer fully annotated images, opening the door to broader application of structured‑output learning in domains where annotation cost is prohibitive.
Comments & Academic Discussion
Loading comments...
Leave a Comment