Information and Communication Technology Reputation for XU030 Quote Companies
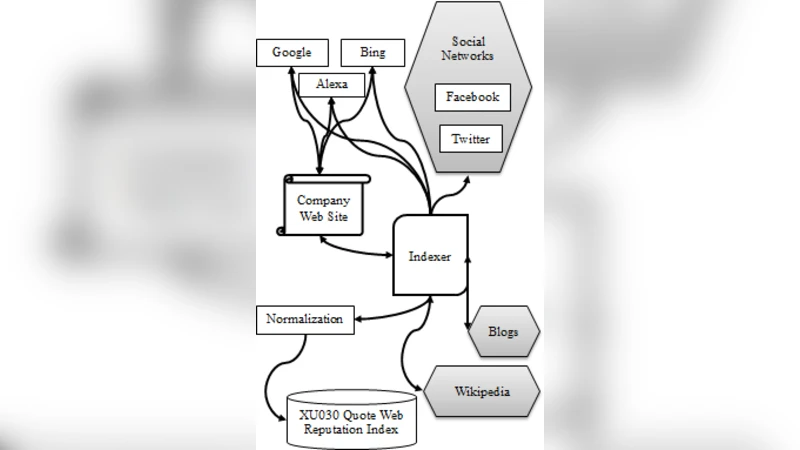
By the increasing spread of information technology and Internet improvements, most of the large-scale companies are paying special attention to their reputation on many types of the information and communication technology. The increasing developments and penetration of new technologies into daily life, brings out paradigm shift on the perception of reputation and creates new concepts like esocieties, techno-culture and new media. Contemporary companies are trying to control their reputation over the new communities who are mostly interacting with social networks, web pages and electronic communication technologies. In this study, the reputation of top 30 Turkish companies, quoted to the Istanbul Stock Market, is studied, based on the information technology interfaces between company and society, such as social networks, blogs, wikis and web pages. The web reputation is gathered through 17 different parameters, collected from Google, Facebook, Twitter, Bing, Alexa, etc. The reputation index is calculated by z-index and fscoring formulations after the min-max normalization of each web reputation parameter.
💡 Research Summary
This paper investigates the information and communication technology (ICT) reputation of the thirty largest Turkish companies listed on the Istanbul Stock Exchange (the XU030 index). Recognizing that the rapid diffusion of the Internet and digital platforms has shifted how corporate reputation is perceived and managed, the authors set out to quantify “digital reputation” by measuring a company’s presence and performance across a variety of online interfaces—social networks, blogs, wikis, and corporate web pages.
Data collection and indicators
Seventeen distinct metrics were identified to capture the breadth of a company’s ICT footprint. The metrics fall into four categories: (1) Search‑engine visibility (Google search results, Google PageRank, Bing index), (2) Social‑media influence (Facebook page likes, Twitter followers), (3) Web‑traffic and ranking (Alexa global rank, SimilarWeb visits, domain authority), and (4) User‑generated content (number of blog mentions, existence and edit count of Wikipedia pages, forum references). Data were harvested between January and March 2024 using publicly available APIs (e.g., Facebook Graph API, Twitter API) and web‑crawling tools (BeautifulSoup, Selenium). The authors applied standard data‑cleaning procedures—duplicate removal, outlier detection, and compliance with robots.txt—to ensure reliability.
Normalization and scoring methodology
Because raw values differ dramatically in scale, each metric was first subjected to min‑max normalization, mapping every observation to the interval
Comments & Academic Discussion
Loading comments...
Leave a Comment