A Generalized Markov-Chain Modelling Approach to $(1,lambda)$-ES Linear Optimization: Technical Report
Several recent publications investigated Markov-chain modelling of linear optimization by a $(1,\lambda)$-ES, considering both unconstrained and linearly constrained optimization, and both constant and varying step size. All of them assume normality of the involved random steps, and while this is consistent with a black-box scenario, information on the function to be optimized (e.g. separability) may be exploited by the use of another distribution. The objective of our contribution is to complement previous studies realized with normal steps, and to give sufficient conditions on the distribution of the random steps for the success of a constant step-size $(1,\lambda)$-ES on the simple problem of a linear function with a linear constraint. The decomposition of a multidimensional distribution into its marginals and the copula combining them is applied to the new distributional assumptions, particular attention being paid to distributions with Archimedean copulas.
💡 Research Summary
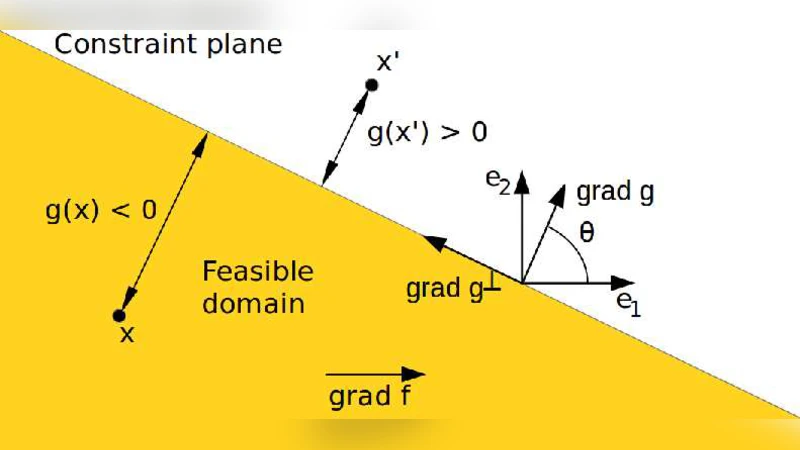
The paper investigates a generalized Markov‑chain framework for the (1,λ) Evolution Strategy (ES) when the mutation steps are drawn from an arbitrary absolutely continuous distribution rather than the usual multivariate normal law. The authors focus on a simple yet representative scenario: a linear objective function subject to a single linear inequality constraint, with a constant step‑size σ and a fixed covariance matrix (the identity). The constraint is handled by resampling infeasible offspring until a feasible one is obtained, a method that aligns with previous analyses of the (1,λ)‑ES under normal steps.
The main contributions are threefold. First, the authors decompose the distribution H of the raw mutation vector into its marginal distributions and an associated copula, thereby separating the dependence structure from the marginal behavior. This decomposition allows the analysis to accommodate a wide class of distributions, including those with heavy tails or asymmetric marginals, and in particular those whose dependence is described by an Archimedean copula. By assuming H is absolutely continuous and that the feasible region Lδ = {x ∈ ℝⁿ | g(x) ≤ δ} has positive probability for every δ > 0, they derive explicit expressions for the density of a feasible step (the first sampled mutation that satisfies the constraint) and for the density of the selected step (the offspring with the highest objective value among the λ feasible offspring). The feasible‑step density is simply the original density truncated to Lδ and renormalized, while the selected‑step density receives an additional factor λ·H((−∞,x₁)×ℝⁿ⁻¹)^{λ−1} that reflects the order‑statistics effect of picking the best among λ candidates.
Second, the paper provides a practical sampling scheme that avoids the infinite‑loop resampling inherent in the definition of feasible steps. By fixing the copula Cδ (assumed independent of δ) and using the inverse marginal cumulative distribution functions together with a rotation matrix that aligns the coordinate system with the gradient of the constraint, the authors construct a deterministic transformation G that maps a vector of uniform random numbers into a feasible mutation. The same construction yields a transformation G* that directly produces the selected mutation by applying the argmax operation on the transformed vectors. This finite‑sample scheme preserves the exact distributional properties derived earlier while being amenable to implementation.
Third, the authors embed the dynamics of the algorithm into a one‑dimensional Markov chain for the normalized distance to the constraint, δₜ = –g(Xₜ)/σ. They show that, regardless of the underlying distribution H, the sequence (δₜ)ₜ≥0 is a homogeneous Markov chain with transition δₜ₊₁ = δₜ – g(Mₜ). Using the explicit density of the selected step, they write the transition kernel in closed form. Under mild regularity conditions on H—namely continuity and strict positivity of its density, finiteness of the first absolute moment of g(Mᵢⱼₜ) conditional on δₜ, and a positive limit for the conditional expectation of g(Mₜ) as δ → ∞—they prove that the chain is μ⁺‑irreducible, aperiodic, and possesses compact small sets. By constructing a Lyapunov function V(δ)=δ and verifying a drift condition ΔV(δ)=E
Comments & Academic Discussion
Loading comments...
Leave a Comment